大家好,我是皮皮。
一、前言
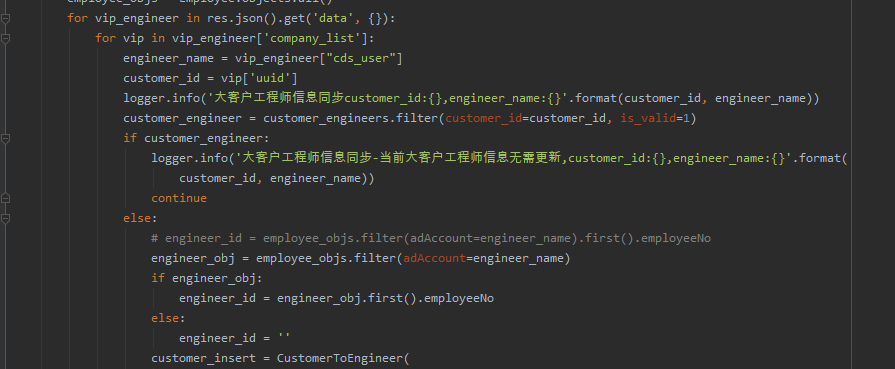
前几天在Python最强王者交流群【wen】问了一个Pandas数据处理的问题,一起来看看吧。
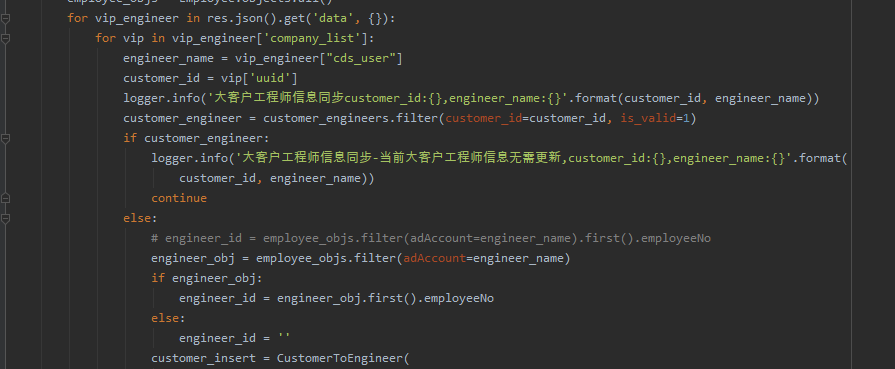
他的代码如下:
import pandas as pd
results = []
df = pd.read_excel('G:\合并结果+2023-09-22.xlsx',dtype=str).convert_dtypes()
list = set(df['销售地'])
for i in list :
a = df['销售地'].count(i)
data = {'销售地': i, '行数': a,}
results.append(data)
print(f'销售地:{i},行数:{a}')他的数据截图如下:
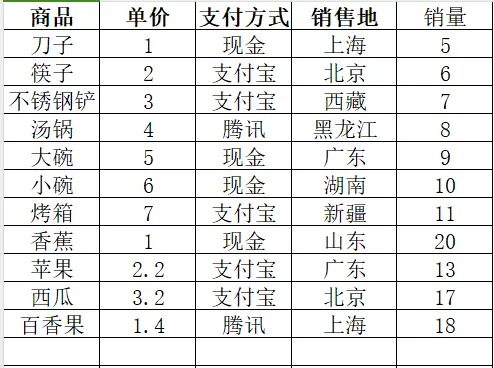
二、实现过程
这里【莫生气】给了一个思路,如下所示:
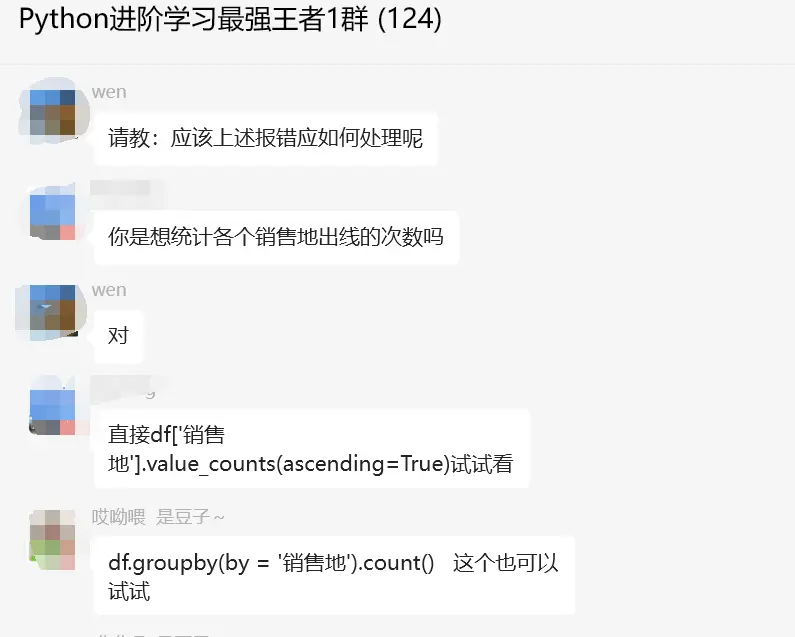
直接df['销售地'].value_counts(ascending=True)或者使用【哎呦喂 是豆子~】提出的df.groupby(by = '销售地').count()
都是可以得到预期的结果的:

后来【巭孬🕷】也给了一个代码,如下所示:
# 读取 Excel 文件
df = pd.read_excel('G:\合并结果+2023-09-22.xlsx', dtype=str).convert_dtypes()
# 统计销售地的行数
sales_counts = df['销售地'].value_counts().reset_index()
sales_counts.columns = ['销售地', '行数']
# 合并结果到原表格
df = df.merge(sales_counts, on='销售地', how='left')顺利地解决了粉丝的问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python数据处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【wen】提问,感谢【哎呦喂 是豆子~】、【巭孬🕷】给出的思路和代码解析,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。