
创建索引
#方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
#方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
#方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
#删除索引:DROP INDEX 索引名 ON 表名字;


#方式一
create table t1(
id int,
name char,
age int,
sex enum('male','female'),
unique key uni_id(id),
index ix_name(name) #index没有key
);
create table t1(
id int,
name char,
age int,
sex enum('male','female'),
unique key uni_id(id),
index(name) #index没有key
);
#方式二
create index ix_age on t1(age);
#方式三
alter table t1 add index ix_sex(sex);
alter table t1 add index(sex);
#查看
mysql> show create table t1;
| t1 | CREATE TABLE `t1` (
`id` int(11) DEFAULT NULL,
`name` char(1) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` enum('male','female') DEFAULT NULL,
UNIQUE KEY `uni_id` (`id`),
KEY `ix_name` (`name`),
KEY `ix_age` (`age`),
KEY `ix_sex` (`sex`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
例子
测试索引
数据准备


#1. 准备表
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2. 创建存储过程,实现批量插入记录
delimiter $$ #声明存储过程的结束符号为$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<3000000)do
insert into s1 values(i,'eva','female',concat('eva',i,'@oldboy'));
set i=i+1;
end while;
END$$ #$$结束
delimiter ; #重新声明分号为结束符号
#3. 查看存储过程
show create procedure auto_insert1\G
#4. 调用存储过程
call auto_insert1();
View Code
在没有索引的前提下测试查询速度
#无索引:mysql根本就不知道到底是否存在id等于333333333的记录,只能把数据表从头到尾扫描一遍,此时有多少个磁盘块就需要进行多少IO操作,所以查询速度很慢
mysql> select * from s1 where id=333333333;
Empty set (0.33 sec)
在表中已经存在大量数据的前提下,为某个字段段建立索引,建立速度会很慢

在索引建立完毕后,以该字段为查询条件时,查询速度提升明显

PS:
1. mysql先去索引表里根据b+树的搜索原理很快搜索到id等于333333333的记录不存在,IO大大降低,因而速度明显提升
2. 我们可以去mysql的data目录下找到该表,可以看到占用的硬盘空间多了
3. 需要注意,如下图
总结:
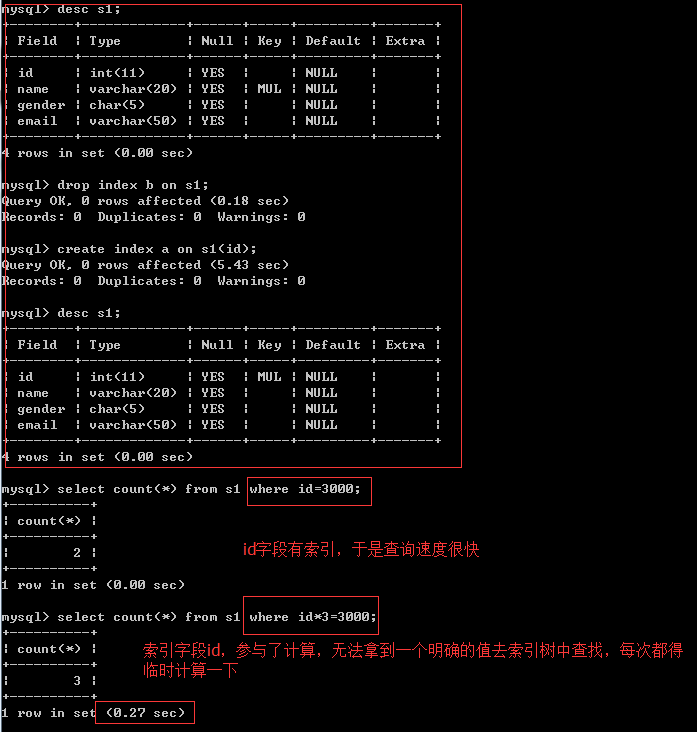
#1. 一定是为搜索条件的字段创建索引,比如select * from s1 where id = 333;就需要为id加上索引
#2. 在表中已经有大量数据的情况下,建索引会很慢,且占用硬盘空间,建完后查询速度加快
比如create index idx on s1(id);会扫描表中所有的数据,然后以id为数据项,创建索引结构,存放于硬盘的表中。
建完以后,再查询就会很快了。
#3. 需要注意的是:innodb表的索引会存放于s1.ibd文件中,而myisam表的索引则会有单独的索引文件table1.MYI
MySAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在innodb中,表数据文件本身就是按照B+Tree(BTree即Balance True)组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此innodb表数据文件本身就是主索引。
因为inndob的数据文件要按照主键聚集,所以innodb要求表必须要有主键(Myisam可以没有),如果没有显式定义,则mysql系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则mysql会自动为innodb表生成一个隐含字段作为主键,这字段的长度为6个字节,类型为长整型.
如果才能正确命中索引
索引未命中
并不是说我们创建了索引就一定会加快查询速度,****若想利用索引达到预想的提高查询速度的效果,我们在添加索引时,必须遵循以下问题
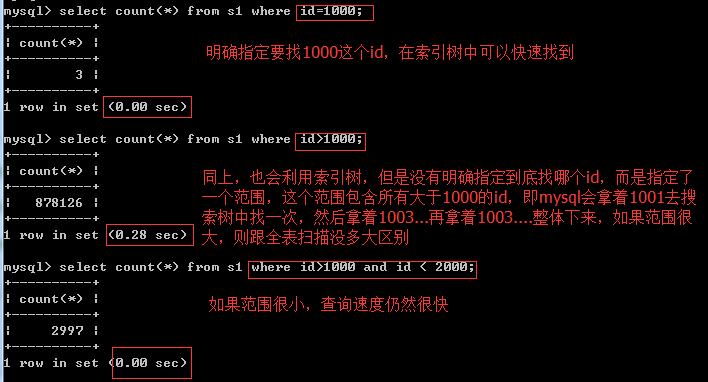
范围问题,或者说条件不明确
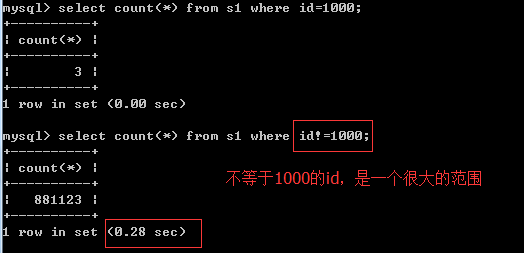
条件中出现这些符号或关键字:****>、>=、<、<=、!= 、between...and...、like、****
大于号、小于号
不等于!=
between ...and...

like

区分度问题
尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录


mysql> desc s1;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int(11) | YES | MUL | NULL | |
| name | varchar(20) | YES | | NULL | |
| gender | char(5) | YES | | NULL | |
| email | varchar(50) | YES | MUL | NULL | |
+--------+-------------+------+-----+---------+-------+
rows in set (0.00 sec)
mysql> drop index a on s1;
Query OK, 0 rows affected (0.20 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> drop index d on s1;
Query OK, 0 rows affected (0.18 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc s1;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| gender | char(5) | YES | | NULL | |
| email | varchar(50) | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
rows in set (0.00 sec)
先把表中的索引都删除,让我们专心研究区分度的问题
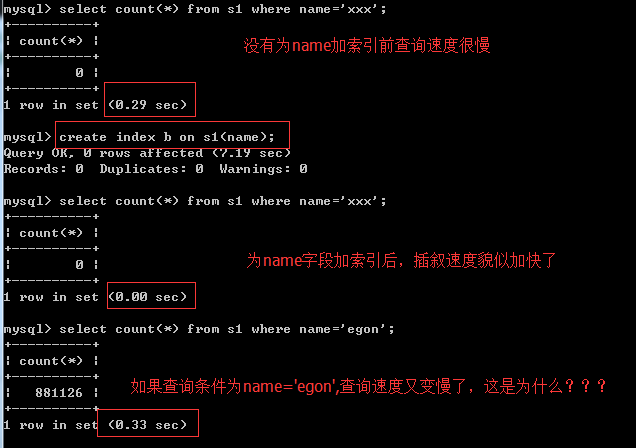


我们编写存储过程为表s1批量添加记录,name字段的值均为egon,也就是说name这个字段的区分度很低(gender字段也是一样的,我们稍后再搭理它)
回忆b+树的结构,查询的速度与树的高度成反比,要想将树的高低控制的很低,需要保证:在某一层内数据项均是按照从左到右,从小到大的顺序依次排开,即左1<左2<左3<...
而对于区分度低的字段,无法找到大小关系,因为值都是相等的,毫无疑问,还想要用b+树存放这些等值的数据,只能增加树的高度,字段的区分度越低,则树的高度越高。极端的情况,索引字段的值都一样,那么b+树几乎成了一根棍。本例中就是这种极端的情况,name字段所有的值均为'egon'
#现在我们得出一个结论:为区分度低的字段建立索引,索引树的高度会很高,然而这具体会带来什么影响呢???
#1:如果条件是name='xxxx',那么肯定是可以第一时间判断出'xxxx'是不在索引树中的(因为树中所有的值均为'egon’),所以查询速度很快
#2:如果条件正好是name='egon',查询时,我们永远无
分析原因
索引列不能在条件中参与计算
索引列不能在条件中参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)
and/or
#1、and与or的逻辑
条件1 and 条件2:所有条件都成立才算成立,但凡要有一个条件不成立则最终结果不成立
条件1 or 条件2:只要有一个条件成立则最终结果就成立
#2、and的工作原理
条件:
a = 10 and b = 'xxx' and c > 3 and d =4
索引:
制作联合索引(d,a,b,c)
工作原理:
对于连续多个and:mysql会按照联合索引,从左到右的顺序找一个区分度高的索引字段(这样便可以快速锁定很小的范围),加速查询,即按照d—>a->b->c的顺序
#3、or的工作原理
条件:
a = 10 or b = 'xxx' or c > 3 or d =4
索引:
制作联合索引(d,a,b,c)
工作原理:
对于连续多个or:mysql会按照条件的顺序,从左到右依次判断,即a->b->c->d
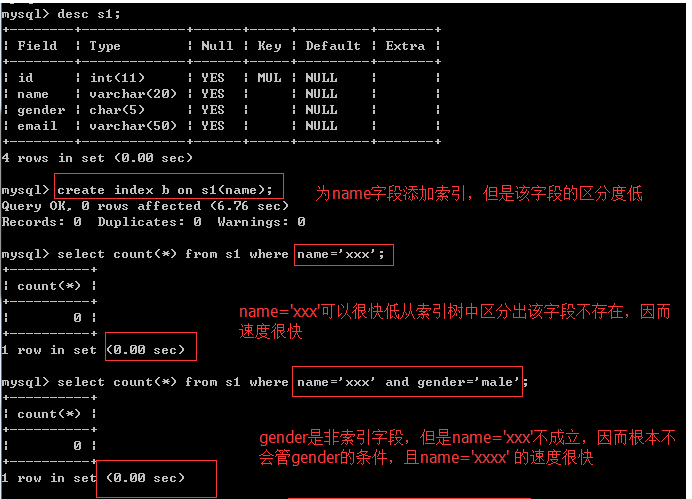
在左边条件成立但是索引字段的区分度低的情况下(name与gender均属于这种情况),会依次往右找到一个区分度高的索引字段,加速查询
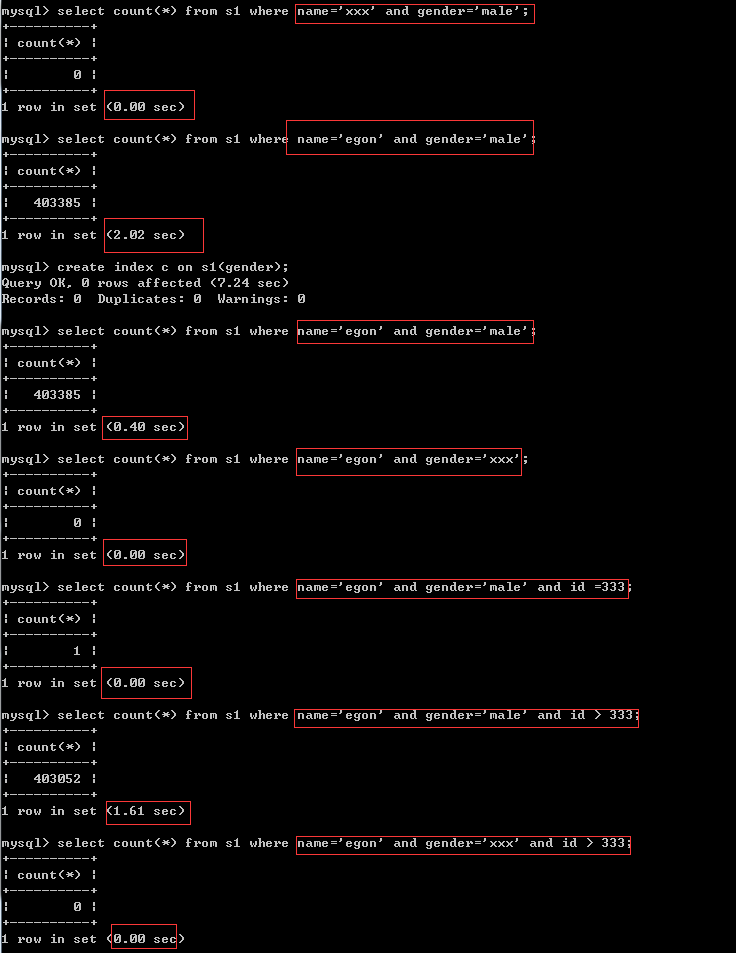
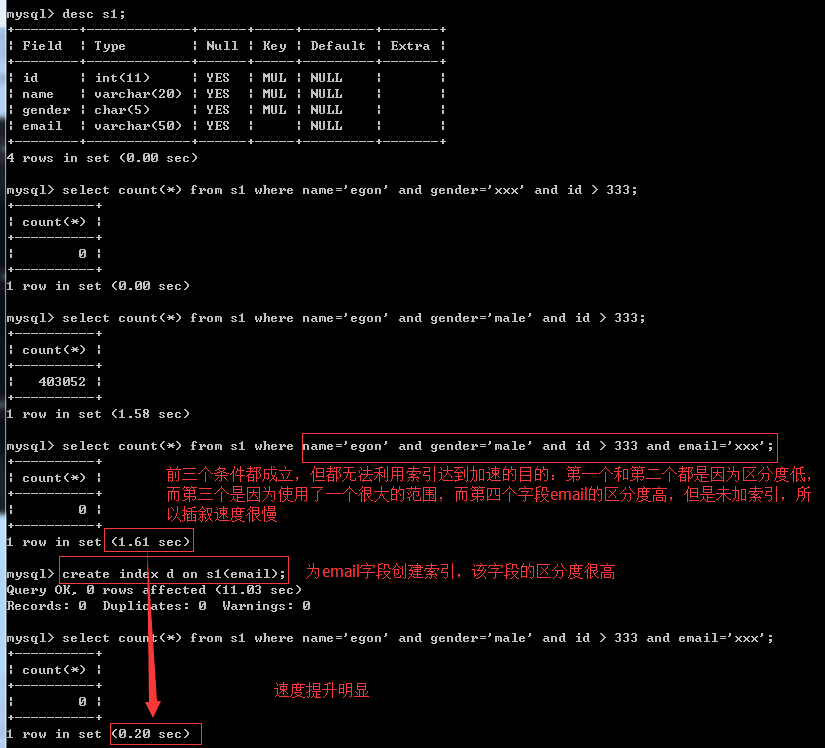
经过分析,在条件为name='egon' and gender='male' and id>333 and email='xxx'的情况下,我们完全没必要为前三个条件的字段加索引,因为只能用上email字段的索引,前三个字段的索引反而会降低我们的查询效率
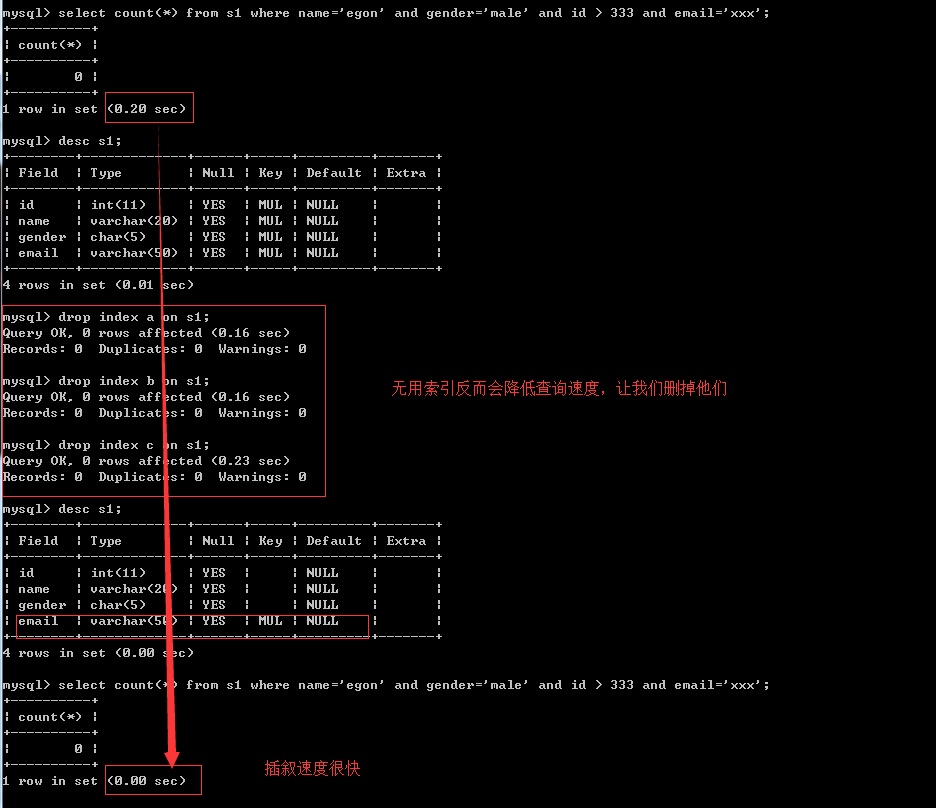
最左前缀匹配原则
非常重要的原则,对于组合索引mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配(指的是范围大了,有索引速度也慢),比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
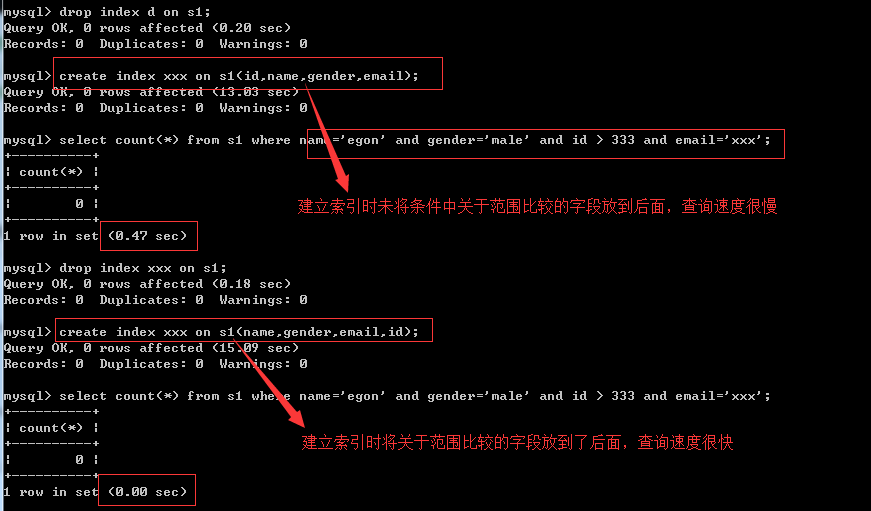
其他情况
使用函数
select * from tb1 where reverse(email) = 'egon';
- 类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然...
select * from tb1 where email = 999;
#排序条件为索引,则select字段必须也是索引字段,否则无法命中
- order by
select name from s1 order by email desc;
当根据索引排序时候,select查询的字段如果不是索引,则速度仍然很慢
select email from s1 order by email desc;
特别的:如果对主键排序,则还是速度很快:
select * from tb1 order by nid desc;
- 组合索引最左前缀
如果组合索引为:(name,email)
name and email -- 命中索引
name -- 命中索引
email -- 未命中索引
- count(1)或count(列)代替count(*)在mysql中没有差别了
- create index xxxx on tb(title(19)) #text类型,必须制定长度
其他注意事项
- 避免使用select *
- 使用count(*)
- 创建表时尽量使用 char 代替 varchar
- 表的字段顺序固定长度的字段优先
- 组合索引代替多个单列索引(由于mysql中每次只能使用一个索引,所以经常使用多个条件查询时更适合使用组合索引)
- 尽量使用短索引
- 使用连接(JOIN)来代替子查询(Sub-Queries)
- 连表时注意条件类型需一致
- 索引散列值(重复少)不适合建索引,例:性别不适合
联合索引
联合索引
联合索引是指对表上的多个列合起来做一个索引。联合索引的创建方法与单个索引的创建方法一样,不同之处仅在于有多个索引列,如:
mysql> create table t(
-> a int,
-> b int,
-> primary key(a),
-> key idx_a_b(a,b)
-> );
Query OK, 0 rows affected (0.11 sec)
覆盖索引
InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询记录,而不需要查询聚集索引中的记录。
覆盖索引 查一个数据不需要回表
select name from 表 where age = 20 不是覆盖索引
select age from 表 where age =20 是覆盖索引
select count(age) from 表 where age =20 是覆盖索引
合并索引
当我们为单独的一列创建索引的时候
如果条件是这一列,且使用正确就可以命中索引
当我们为两列分别创建单独的索引的时候
如果这两列都是条件,那么可能只能命中期中一个条件
如果这两列都是条件,那么可能会命中两个索引 - 合并索引
我们为多列直接创建联合所以
条件命中联合索引
索引总结:
1.条件一定是建立了索引的字段,如果条件使用的字段根本就没有创建索引,那么索引不生效
2.如果条件是一个范围,随着范围的值逐渐增大,那么索引能发挥的作用也越小
3.如果使用like进行模糊查询,那么使用a%的形式能命中索引,%a形式不能命中索引
4.尽量选择区分度高的字段作为索引列
5.索引列不能在条件中参与计算,也不能使用函数
6.在多个条件以and相连的时候,会优点选择区分度高的索引列来进行查询
在多个条件以or相连的时候,就是从左到右依次判断
7.制作联合索引
1.最左前缀原则 a,b,c,d 条件是a的能命中索引,条件是a,b能命中索引,a,b,c能命中,a,c.... 只要没有a就不能命中索引
如果在联合查询中,总是涉及到同一个字段,那么就在建立联合索引的时候将这个字段放在最左侧
2.联合索引 如果按照定义顺序,从左到右遇到的第一个在条件中以范围为条件的字段,索引失效
尽量将带着范围查询的字段,定义在联合索引的最后面
drop index
如果我们查询的条件总是多个列合在一起查,那么就建立联合索引
create index ind_mix on s1(id,email)
select * from s1 where id = 1000000 命中索引
select * from s1 where email = 'eva1000000@oldboy' 未命中索引
但凡是创建了联合索引,那么在查询的时候,再创建顺序中从左到右的第一列必须出现在条件中
select count(*) from s1 where id = 1000000 and email = 'eva10%'; 命中索引
select count(*) from s1 where id = 1000000 and email like 'eva10%'; 可以命中索引
范围 :
select * from s1 where id >3000 and email = 'eva300000@oldboy'; 不能命中索引
8.条件中涉及的字段的值必须和定义表中字段的数据类型一致,否则不能命中索引
执行计划
执行计划
看看mysql准备怎么执行这条语句 可以看到是否命中索引,计划能命中哪些,实际命中了哪些,执行的顺序,是否发生了索引合并,覆盖索引
explain select * from s1;













