
一、为什么使用Tidb
最近发现tidb在互联网圈大火,新生代的一个NewSql数据库 具体链接可以访问pincap的官网 https://www.pingcap.com/docs-cn/v3.0/
二、Tidb常见的问题:
1.数据热点问题
因为tidb使用的是基于raft的tikv实例(rocketdb),任何分布式的系统都会存在或多或少的数据热点问题,那我们遇到这个问题要是如何排查呢,tidb官网也提供了 很多便捷的查看hot key方案
第一种:
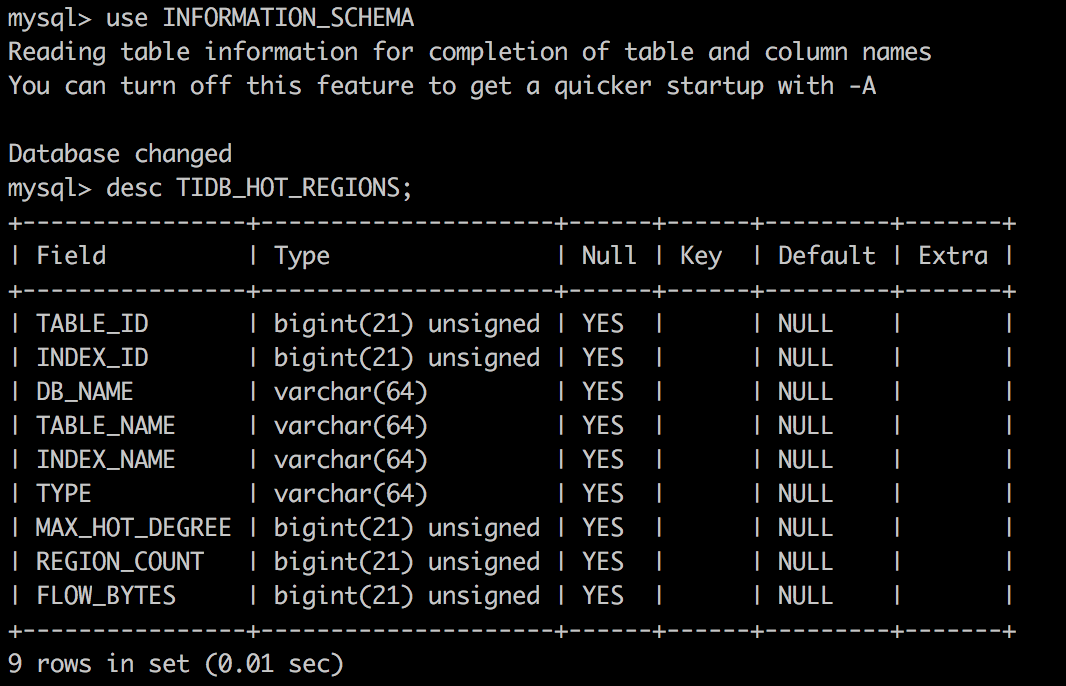
通过sql语句内置的表 进去hot热点查看,可以通过TIDB_HOT_REGIONS这张表查看,TIDB_HOT_REGIONS 表提供了关于热点 REGION 的相关信息
注意每一个tikv就为一个store
第二种:
通过pd-control工具进行查看
启动方式 ./pd-ctl -u http://xxxxxx:2379
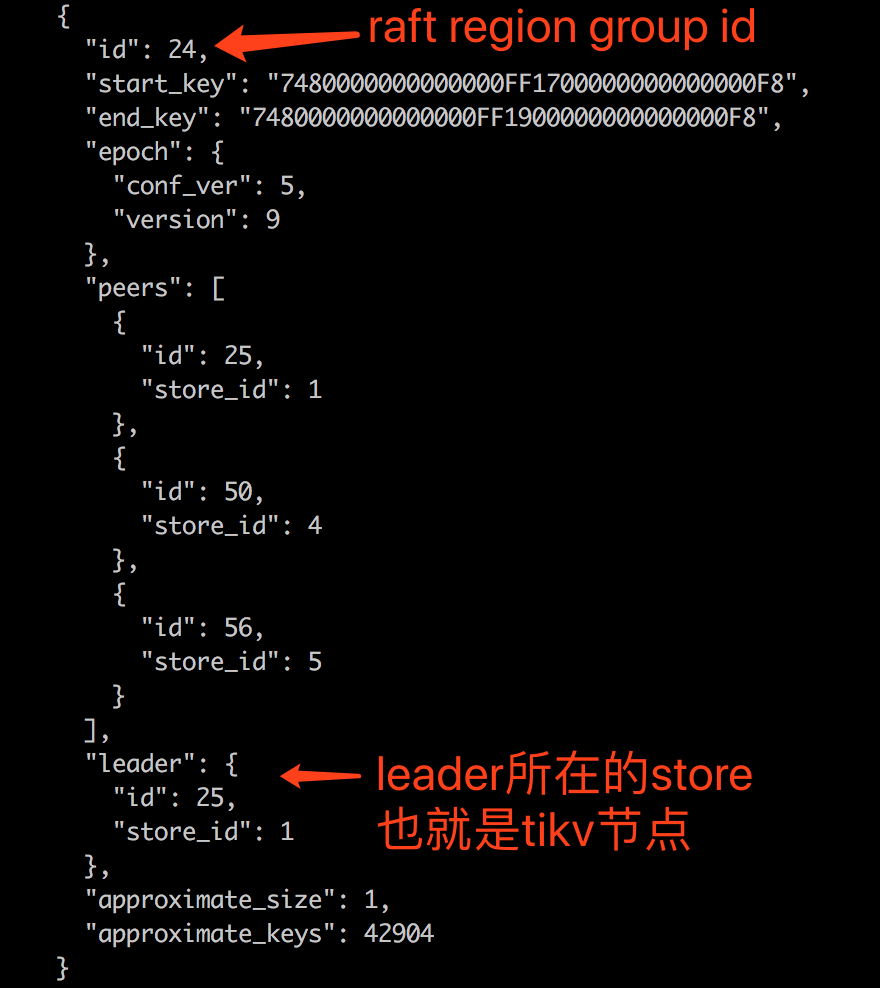
通过region命令 可以查看 每个raft group的id 里面raft leader 所在的store的位置,同时可以给如果出现热点当前raft group进行分裂
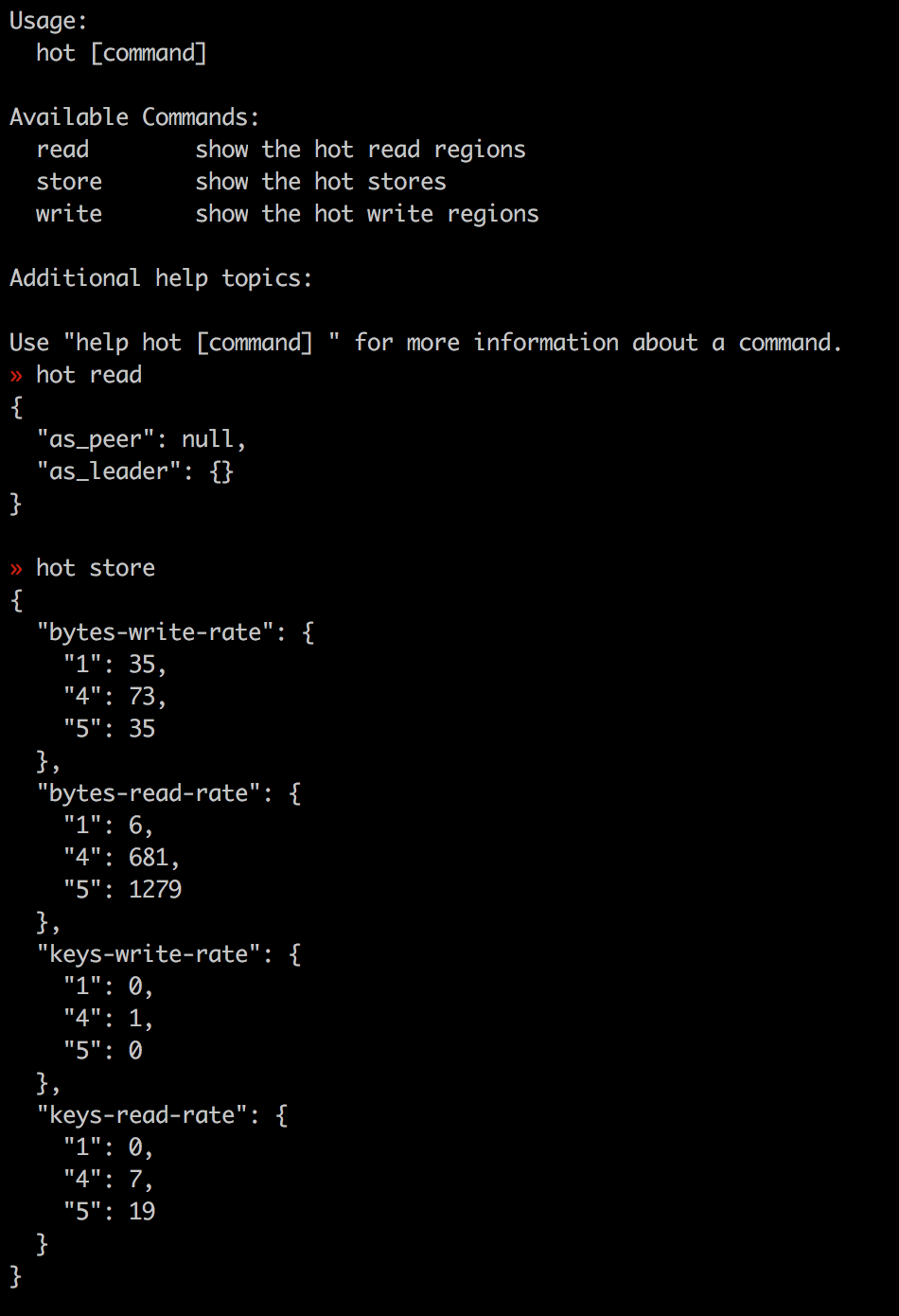
通过hot命令查看热点region/store
将某个region 分裂成多个
>> operator show // 显示所有的 operators
>> operator show admin // 显示所有的 admin operators
>> operator show leader // 显示所有的 leader operators
>> operator show region // 显示所有的 Region operators
>> operator add add-peer 1 2 // 在 store 2 上新增 Region 1 的一个副本
>> operator add remove-peer 1 2 // 移除 store 2 上的 Region 1 的一个副本
>> operator add transfer-leader 1 2 // 把 Region 1 的 leader 调度到 store 2
>> operator add transfer-region 1 2 3 4 // 把 Region 1 调度到 store 2,3,4
>> operator add transfer-peer 1 2 3 // 把 Region 1 在 store 2 上的副本调度到 store 3
>> operator add merge-region 1 2 // 将 Region 1 与 Region 2 合并
>> operator add split-region 1 --policy=approximate // 将 Region 1 对半拆分成两个 Region,基于粗略估计值
>> operator add split-region 1 --policy=scan // 将 Region 1 对半拆分成两个 Region,基于精确扫描值
>> operator remove 1
其中,Region 的分裂都是尽可能地从靠近中间的位置开始。对这个位置的选择支持两种策略,即 scan 和 approximate。它们之间的区别是,前者通过扫描这个 Region 的方式来确定中间的 key,而后者是通过查看 SST 文件中记录的统计信息,来得到近似的位置。一般来说,前者更加精确,而后者消耗更少的 I/O,可以更快地完成。
通过调度策略操作region
>> scheduler show // 显示所有的 schedulers
>> scheduler add grant-leader-scheduler 1 // 把 store 1 上的所有 Region 的 leader 调度到 store 1
>> scheduler add evict-leader-scheduler 1 // 把 store 1 上的所有 Region 的 leader 从 store 1 调度出去
>> scheduler add shuffle-leader-scheduler // 随机交换不同 store 上的 leader
>> scheduler add shuffle-region-scheduler // 随机调度不同 store 上的 Region
>> scheduler remove grant-leader-scheduler-1 // 把对应的 scheduler 删掉














