
JVM内存结构
JVM
一,基本介绍
解释:java虚拟机,准确的来说是java二进制字节码的运行环境。(jvm是一套规范),用来执行class文件,保证java语言跨平台。
Java虚拟机可以看作是一台虚拟的计算机,和真是的计算机一样,有着自己的指令集以及各种运行时内存。
jvm就是一个字节码翻译器,它将字节码文件翻译成各个系统对应的的机器码,确保字节码文件能在各个系统上正确的运行。
优点:
(1)一次编写,到处运行(jvm屏蔽了字节码与底层操作系统的差异,对外提供了一致的运行环境,jvm用解释的方法执行二进制字节码来达到代码与平台无关系);
(2)自动内存管理,垃圾回收功能;(解决了内存泄漏的问题:被占用的资源无法释放)
(3)数组下标越界检查;
(4)多态(面向对象的基石)
二,jvm内存中包含的结构:
方法区,堆,虚拟机栈,程序计数器,本地方法栈,执行引擎(解释器,即时编译器,垃圾回收),本地方法接口
方法区(线程共享)
存放类的二进制字节码文件(二进制字节码文件中包括:类基本信息,常量池,类方法定义,包含了虚拟机指令)
所有java虚拟机共享的区,存储了和类的结构、类信息
类结构:运行时常量池(含字符串常量),静态变量,类的信息,常量
类信息:魔数,版本号,常量池,类(字段和方法),父类和接口数组,字段,方法等信息。
方法区逻辑上是堆的一部分,不同厂商在具体实现时不一定,方法区的位置不固定,方法区会产生内存溢出
方法区是JVM中的一个规范,永久代和元空间是方法区的两个不同实现。
Jdk1.8之前使用永生代实现,1.8之后使用元空间实现。
堆(线程共享)
解释:
存放类的Class对象,静态变量。堆中的对象在调用方法时会用到虚拟机栈,程序计数器,本地方法栈【获取资源】
通过new关键字创建的对象都会由堆存储
堆中不再被引用的对象会通过垃圾回收机制自动回收
堆的内存结构图:

特点:
- 堆是jvm中占内存最大的一块。
- 堆是被所有线程共享的内存区域,在虚拟机启动时创建。
- 堆是用来存放实例对象和数组的内存区域。
- 堆是垃圾收集器管理的主要区域。
- 堆在逻辑上分为新生代和老年代,垃圾收集器在这两个区使用的回收策略也不同【获取资源】
jvm堆内存常用参数
| 参数 | 描述 |
|---|---|
-Xms |
堆内存初始大小,单位:m,g |
-Xmx(MaxHeapSize) |
堆内存最大允许大小,一般不要大于物理内存的80% |
-XX:PermSize |
非堆内存初始大小,一般使用设置初始化200m,最大1024m就够了。 |
-XX:MaxPermSize |
非堆内存最大允许大小 |
-XX:NewSize(-Xns) |
年轻代内存初始大小 |
-XX:MaxNewSize(-Xmn) |
年轻代内存最大允许大小,也可以缩写 |
-XX:SurvivorRatio=8 |
年轻代中Eden区与Survivor区的容量比值,默认为8,即8:1 |
-Xss |
堆栈内存大小 |
虚拟机栈(线程私有)【获取资源】
解释:
简称:栈
线程运行时需要的内存空间
每个线程只能有一个活动栈帧,对应着一个线程正在执行的那个方法,该栈帧处于栈顶。
一个栈内是由多个栈帧组成的,一个栈帧对应着一个方法的调用,每个栈帧都有自己独立的存储空间
栈帧:每个方法运行时需要的内存
栈帧内部:
每个栈帧中包括:操作数栈,局部变量表,动态链接,方法返回值等信息。
局部变量表
用来存储方法中的局部变量(包括在方法中声明的非静态变量以及函数形参)。局部变量表的大小在编译期确定,程序执行期间局部变量表的大小不变。
对于基本数据类型的变量,则直接存储它的值,(long,double占两个局部变量,其他类型只占一个局部变量)
对于引用类型性的变量,则存储的是指向对象的引用。
操作数栈
当一个方法开始执行时,操作数栈为空;
随着方法的执行, 会从局部变量表或对象实例的字段中复制所需的数据并写入操作数栈中,在随着计算的进行将栈中的元素,出栈给局部变量表,或返回给调用者。
动态链接
是指向运行时常量池的引用,在class文件中,描述一个方法调用或访问其他成员变量是通过符号引用来表示的,动态链接的作用是将这些符号引用所表示的方法转换为实际方法的直接引用。
方法返回地址
方法返回地址是方法调用的返回,包含正常返回(有返回值)和异常返回(无返回值),不同的返回值类型有不同的指令。
无论方法采用何种方式退出,在方法退出后都要返回方法调用的位置。程序才能继续执行。方法返回时可能需要在当前栈中保存一些信息,来帮助它恢复上层方法的执行状态。
栈内存溢出:
栈内存不足时就会发生栈内存溢出错误,可通过栈内存大小改变栈所占空间的大小。
- 栈帧过大导致栈内存溢出
- 栈帧过多导致栈内存溢出(死归)
设置栈内存大小:-Xss size【获取资源】
栈内存大小默认值:Linux:1024KB Mac:1024KB Windows:依赖虚拟机大小(1024K)
程序计数器(线程私有)
解释:
线程安全的,只要用于保存当前要执行的指令号,一旦指令执行,计数器将更新到下一条指令号
记住当前jvm指令的执行地址,一个处理机只能执行一条线程中的指令,为了线程切换后能恢复到正确的执行位置,每个线程有一个程序计数器
物理上程序计数器是通过寄存器(CPU组件中读取速度最快的单元)来实现的
程序计数器是线程私有的,是java内存中唯一不会存在内存溢出的区。
执行过程
- 计数器读入要执行的jvm指令号
- cpu获取计数器中的指令号
- cpu根据从计数器中获取到的指令号执行相对应的指令
- 计数器更新要执行的jvm指令号
本地方法栈(线程私有)
native修饰的方法称为本地方法,它不是java代码编写的方法,而是由本地的动态库提供,可以是任意语言,如:C,C++
本地方法栈的功能特点类似于虚拟机栈,每个线程单独创建自己的本地方法区,主要用于保存本地方法信息。
不同处:虚拟机栈服务的是java方法,本地方法栈服务的是Native方法。
本地方法举例:hashCode,notify,wait
执行引擎
解释器:读取字节码,每行代码是由解释器进行逐行执行
即时编译器:方法中的热点代码(频繁被调用的代码)使用即时编译器编译执行,即时编译器将热点代码编译为本地代码,用于多次的重复调用提高系统性能。
垃圾回收器:对堆中不再被引用的对象被垃圾回收,
可以调用System.gc()来触发垃圾回收机制进行垃圾回收。垃圾回收器只回收使用new关键字创建的对象,使用finalize方法清理其他对象。
本地方法接口:
一些java不方便实现的功能,必须调用底层操作系统的功能,需要调用本地方法接口来调用操作系统的一些功能方法;与本地方法库进行交互,提供执行引擎所需要的本地库。
本地方法库:执行引擎所需要的本地库的集合。
三,常见问题
1,垃圾回收是否涉及栈内存?【获取资源】
不会,栈内存就是一次次的方法调用所产生的栈帧内存,栈帧内存在每一次的方法调用结束后后被弹出栈,自动的被回收掉,不需要垃圾回收。
2,栈内存分配越大越好么?
栈内存划分的越大会使得线程数变少,因为我们物理内存的大小是一定的
3,方法内的局部变量是否线程安全?
如果方法内部局部变量没有逃离方法的作用范围它就是安全的,是线程私有的 ,不会产生在多个线程下产生线程干扰。
如果局部变量引用了对象,并逃离方法的作用范围,它就不是线程安全的。
(参数变量不是线程安全,会被返回得局部变量不是线程安全的)
4,什么情况下会产生栈溢出?
(1)栈帧过多,方法递归调用的不规范
(2)栈帧过大,此情况不易出现
四,堆内存的诊断工具
jps工具:查看当前系统中有哪些java进程
jmap:查看堆内存占用情况 jmap -heap 进程id
jconsole工具:图形界面的多功能检测工具,可连续检测
五,JDK1.8内存模型
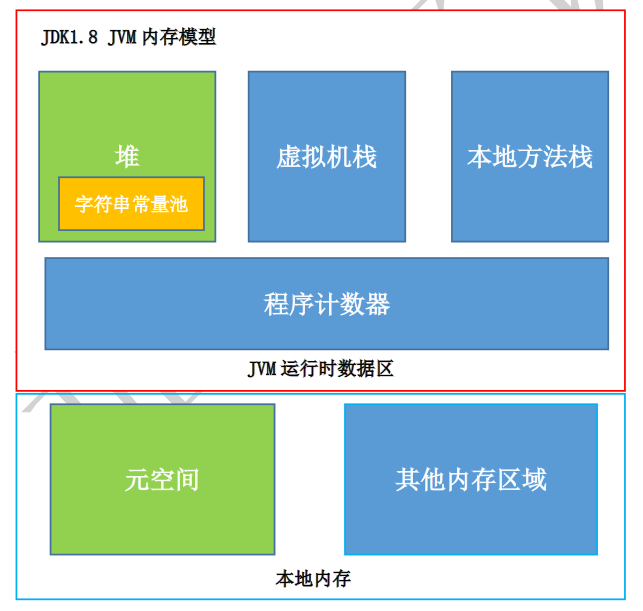
最后,祝大家早日学有所成,拿到满意offer,快速升职加薪,走上人生巅峰。
可以的话请给我一个三连支持一下我哟??????【获取资料】













