
我司 Engineering VP 申砾在 TiDB DevCon 2019 上分享了 TiDB 产品进化过程中的思考与未来规划。本文为演讲实录上篇,重点回顾了 TiDB 2.1 的特性,并分享了我们对「如何做一个好的数据库」的看法。

感谢这么多朋友的到场,今天我会从我们的一些思考的角度来回顾过去一段时间做了什么事情,以及未来的半年到一年时间内将会做什么事情,特别是「我们为什么要做这些事情」。
TiDB 这个产品,我们从 2015 年年中开始做,做到现在,三年半,将近四年了,从最早期的 Beta 版的时候就开始上线,到后来 RC 版本,最后在 2017 年终于发了 1.0,开始铺了一部分用户,到 2.0 的时候,用户数量就开始涨的非常快。然后我们最近发了 2.1,在 2.1 之后,我们也和各种用户去聊,跟他们聊一些使用的体验,有什么样的问题,包括对我们进行吐嘈。我们就在这些实践经验基础之上,设计了 3.0 的一些特性,以及我们的一些工作的重点。现在我们正在朝 3.0 这个版本去演进,到今天早上已经发了 3.0 Beta 版本。
TiDB 2.1
首先我们来讲 2.1,2.1 是一个非常重要的版本,这个版本我们吸取了很多用户的使用场景中看到的问题,以及特别多用户的建议。在这里我跟大家聊一聊它有哪些比较重要的特性。

首先我们两个核心组件:存储引擎和计算引擎,在这两方面,我们做了一些非常重要的改进,当然这些改进有可能是用户看不到的。或者说这些改进其实我们是不希望用户能看到的,一旦你看到了,注意到这些改进的话,说明你的系统遇到这些问题了。
1. Raft
1.1 Learner
大家都知道 Raft 会有 Leader 和 Follower 这两个概念,Leader 来负责读写,Follower 来作为 Backup,然后随时找机会成为新的 Leader。如果你想加一个新的节点,比如说在扩容或者故障恢复,新加了一个 Follower 进来,这个时候 Raft Group 有 4 个成员, Leader、Follower 都是 Voter,都能够在写入数据时候对日志进行投票,或者是要在成员变更的时候投票的。这时一旦发生意外情况,比如网络变更或者出现网络分区,假设 2 个被隔离掉的节点都在一个物理位置上,就会导致 4 个 Voter 中 2 个不可用,那这时这个 Raft Group 就不可用了。
大家可能觉得这个场景并不常见,但是如果我们正在做负载均衡调度或者扩容时,一旦出现这种情况,就很有可能影响业务。所以我们加了 Learner 这个角色,Learner 的功能也是我们贡献给 etcd 这个项目的。有了 Learner 之后,我们在扩容时不会先去加一个 Follower(也就是一个 Voter),而是增加一个 Learner 的角色,它不是 Voter,所以它只会同步数据不会投票,所以无论在做数据写入还是成员变更的时候都不会算上它。当同步完所有数据时(因为数据量大的时候同步时间会比较长),拿到所有数据之后,再把它变成一个 Voter,同时再把另一个我们想下线的 Follower 下掉就好了。这样就能极大的缩短同时存在 4 个 Voter 的时间,整个 Raft Group 的可用性就得到了提升。
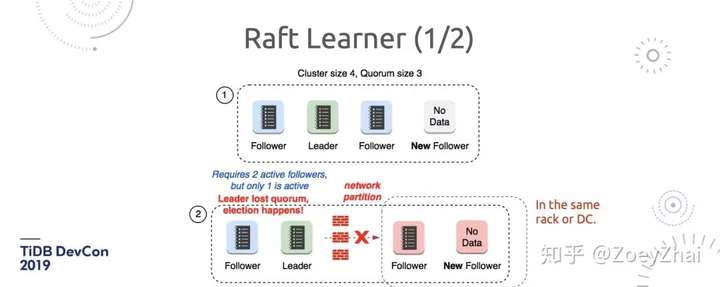
其实增加 Learner 功能不只是出于提升 Raft Group 可用性,或者说出于安全角度考虑,实际上我们也在用 Learner 来做更多的事情。比如,我们可以随便去加 Learner,然后把 Learner 变成一个只读副本,很多很重的分析任务就可以在 Learner 上去做。TiFlash 这个项目其实就是用 Learner 这个特性来增加只读副本,同时保证不会影响线上写入的延迟,因为它并不参与写入的时候投票。这样的好处是第一不影响写入延迟,第二有 Raft 实时同步数据,第三我们还能在上面快速地做很复杂的分析,同时线上 OLTP 业务有物理上的隔离。
1.2 PreVote
除了 Learner 之外,我们 2.1 中默认开启了 PreVote 这个功能。
我们考虑一种意外情况,就是在 Raft group 中出现了网络隔离,有 1 个节点和另外 2 个节点隔离掉了,然后它现在发现「我找不到 Leader 了,Leader 可能已经挂掉了」,然后就开始投票,不断投票,但是因为它和其他节点是隔离开的,所以没有办法选举成功。它每次失败,都会把自己的 term 加 1,每次失败加 1,网络隔离发生一段时间之后,它的 term 就会很高。当网络分区恢复之后,它的选举消息就能发出去了,并且这个选举消息里面的 term 是比较高的。根据 Raft 的协议,当遇到一个 term 比较高的时候,可能就会同意发起选举,当前的 Leader 就会下台来参与选举。但是因为发生网络隔离这段时间他是没有办法同步数据的,此时它的 Raft Log 一定是落后的,所以即使它的 term 很高,也不可能被选成新的 Leader。所以这个时候经过一次选举之后,它不会成为新 Leader,只有另外两个有机会成为新的 Leader。
大家可以看到,这个选举是对整个 Raft Group 造成了危害:首先它不可能成为新的 Leader,第二它把原有的 Leader 赶下台了,并且在这个选举过程中是没有 Leader 的,这时的 Raft Group 是不能对外提供服务的。虽然这个时间会很短,但也可能会造成比较大的抖动。
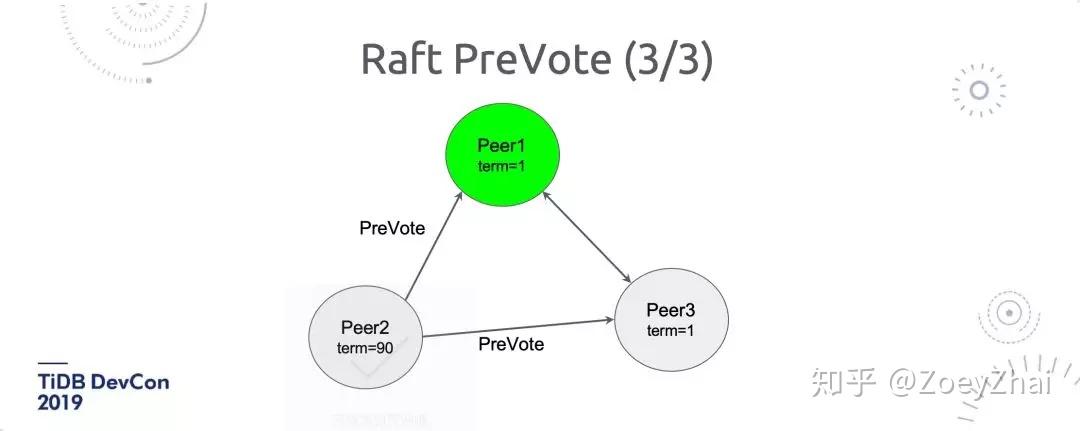
所以我们有了 PreVote 这个特性。具体是这样做的(如图 3):在进行选举之前,先用 PreVote 这套机制来进行预选举,每个成员把自己的信息,包括 term,Raft Log Index 放进去,发给其它成员,其它成员有这个信息之后,认为「我可以选你为 Leader」,才会发起真正的选举。
有了 PreVote 之后,我们就可以避免这种大规模的一个节点上很多数据、很多 Raft Group、很多 Peer 的情况下突然出现网络分区,在恢复之后造成大量的 Region 出现选举,导致整个服务有抖动。 因此 PreVote 能极大的提升稳定性。
2. Concurrent DDL Operation
当然除了 Raft 这几个改进之外,TiDB 2.1 中还有一个比较大的改进,就是在 DDL 模块。这是我们 2.1 中一个比较显著的特性。
在 2.1 之前的 DDL 整套机制是这样的(如图 4):用户将 DDL 提交到任何一个 TiDB Server,发过来一个 DDL 语句,TiDB Server 经过一些初期的检查之后会打包成一个 DDL Job,扔到 TiKV 上一个封装好的队列中,整个集群只有一个 TiDB Server 会执行 DDL,而且只有一个线程在做这个事情。这个线程会去队列中拿到队列头的一个 Job,拿到之后就开始做,直到这个 Job 做完,即 DDL 操作执行完毕后,会再把这个 Job 扔到历史队列中,并且标记已经成功,这时 TiDB Sever 能感知到这个 DDL 操作是已经结束了,然后对外返回。前面的 Job 在执行完之前,后面的 DDL 操作是不会执行的,因而会造成一个情况: 假设前面有一个 AddIndex,比如在一个百亿行表上去 AddIndex,这个时间是非常长的,后面的 Create Table 是非常快的,但这时 Create Table 操作会被 AddIndex 阻塞,只有等到 AddIndex 执行完了,才会执行 Create Table,这个给有些用户造成了困扰,所以我们在 TiDB 2.1 中做了改进。
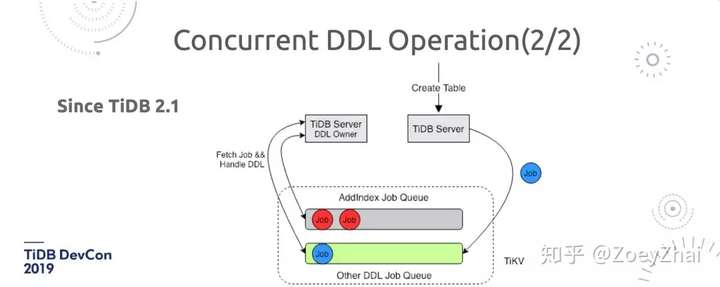
在 TiDB 2.1 中 DDL 从执行层面分为两种(如图 5)。一种是 AddIndex 操作,即回填数据(就是把所有的数据扫出来,然后再填回去),这个操作耗时是非常长的,而且一些用户是线上场景,并发度不可能调得很高,因为在回写数据的时候,可能会对集群的写入造成压力。
另外一种是所有其他 DDL 操作,因为不管是 Create Table 还是加一个 Column 都是非常快的,只会修改 metadata 剩下的交给后台来做。所以我们将 AddIndex 的操作和其他有 DDL 的操作分成两个队列,每种 DDL 语句按照分类,进到不同队列中,在 DDL 的处理节点上会启用多个线程来分别处理这些队列,将比较慢的 AddIndex 的操作交给单独的一个线程来做,这样就不会出现一个 AddIndex 操作阻塞其他所有 Create Table 语句的问题了。
这样就提升了系统的易用性,当然我们下一步还会做进一步的并行, 比如在 AddIndex 时,可以在多个表上同时 AddIndex,或者一个表上同时 Add 多个 Index。我们也希望能够做成真正并行的一个 DDL 操作。
3. Parallel Hash Aggregation
除了刚刚提到的稳定性和易用性的提升,我们在 TiDB 2.1 中,也对分析能力做了提升。我们在聚合的算子上做了两点改进。 第一点是对整个聚合框架做了优化,就是从一行一行处理的聚合模式,变成了一批一批数据处理的聚合模式,另外我们还在哈希聚合算子上做了并行。
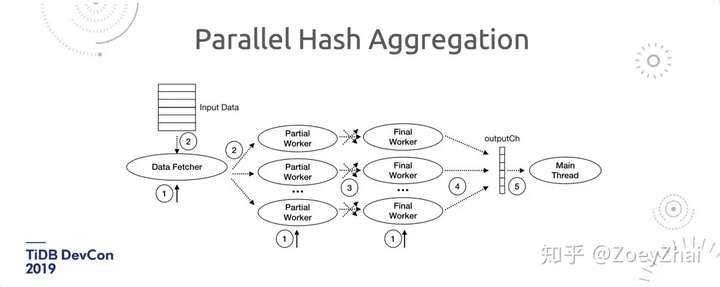
为什么我们要优化聚合算子?因为在分析场景下,有两类算子是非常重要的,是 Join 和聚合。Join 算子我们之前已经做了并行处理,而 TiDB 2.1 中我们进一步对聚合算子做了并行处理。在哈希聚合中,我们在一个聚合算子里启用多个线程,分两个阶段进行聚合。这样就能够极大的提升聚合的速度。
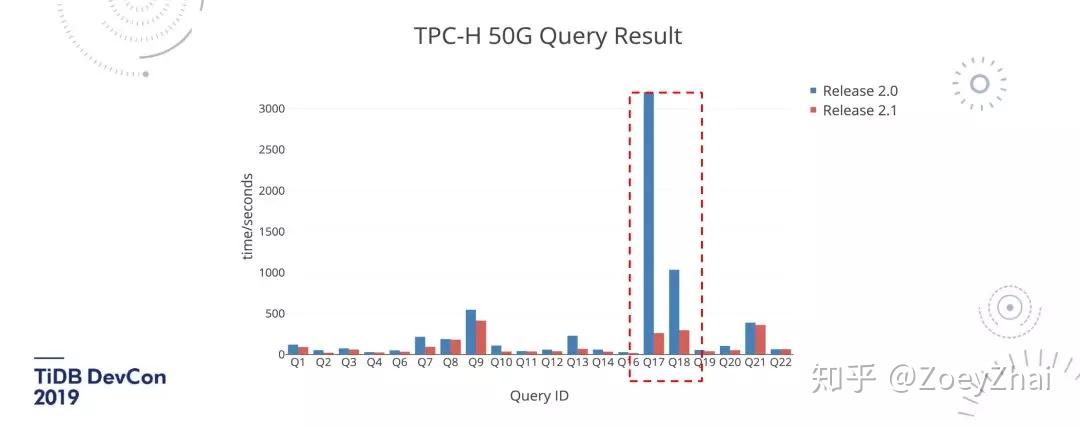
图 7 是 TiDB 2.1 发布的时候,我们做了一个 TPC-H Benchmark。实际上所有的 Query 都有提升,其中 Q17 和 Q18 提升最大。因为在 TiDB 2.0 测试时,Q17、Q18 还是一个长尾的 Query,分析之后发现瓶颈就在于聚合算子的执行。整个机器的 CPU 并不忙,但就是时间很长,我们做了 Profile 发现就是聚合的时间太长了,所以在 TiDB 2.1 中,对聚合算子做了并行,并且这个并行度可以调节。
4. Ecosystem Tools
TiDB 2.1 发布的时我们还发布了两个工具,分别叫 TiDB-DM 和 TiDB-Lightning。
TiDB-DM 全称是 TiDB Data Migration,这个工具主要用来把我们之前的 Loader 和以及 Syncer 做了产品化改造,让大家更好用,它能够做分库分表的合并,能够只同步一些表中的数据,并且它还能够对数据做一些改写,因为分库分表合并的时候,数据合到一个表中可能会冲突,这时我们就需要一种非常方便、可配置的工具来操作,而不是让用户手动的去调各种参数。
TiDB-Lightning 这个工具是用来做全量的数据导入。之前的 Loader 也可以做全量数据导入,但是它是走的最标准的那套 SQL 的流程,需要做 SQL 的解析优化、 两阶段提交、Raft 复制等等一系列操作。但是我们觉得这个过程可以更快。因为很多用户想迁移到 TiDB 的数据不是几十 G 或者几百 G,而是几 T、几十 T、上百 T 的数据,通过传统导入的方式会非常慢。现在 TiDB-Lightning 可以直接将本地从 MySQL 或者其他库中导出的 SQL 文本,或者是 CSV 格式的文件,直接转成 RocksDB 底层的 SST file ,然后再注入到 TiKV 中,加载进去就导入成功了,能够极大的提升导入速度。当然我们还在不断的优化,希望这个速度能不断提升,将 1TB 数据的导入,压缩到一两个小时。这两个工具,有一部分用户已经用到了(并且已经正式开源)。
How to build a good database?
我们有相当多的用户正在使用 TiDB,我们在很多的场景中见到了各种各样的 Case,甚至包括机器坏掉甚至连续坏掉的情况。见了很多场景之后,我们就在想之后如何去改进产品,如何去避免在各种场景中遇到的「坑」,于是我们在更深入地思考一个问题:如何做一个好的数据库。因为做一个产品其实挺容易的,一个人两三个月也能搞一套数据库,不管是分库分表,还是类似于在 KV 上做一个 SQL,甚至做一个分布式数据库,都是可能在一个季度甚至半年之内做出来的。但是要真正做一个好的数据库,做一个成熟的数据库,做一个能在生产系统中大规模使用,并且能够让用户自己玩起来的数据库,其实里面有非常多工作要做。
首先数据库最基本的是要「有用」,就是能解决用户问题。而要解决用户问题,第一点就是要知道用户有什么样的问题,我们就需要跟各类用户去聊,看用户的场景,一起来分析,一起来获得使用场景中真实存在的问题。所以最近我们有大量的同事,不管是交付的同事还是研发的同事,都与用户做了比较深入的访谈,聊聊用户在使用过程中有什么的问题,有什么样的需求,用户也提供各种各样的建议。我们希望 TiDB 能够很好的解决用户场景中存在的问题,甚至是用户自己暂时还没有察觉到的问题,进一步的满足用户的各种需求。
第二点是「易用性」。就好像一辆车,手动挡的大家也能开,但其实大家现在都想开自动挡。我们希望我们的数据库是一辆自动挡的车,甚至未来是一辆无人驾驶的车,让用户不需要关心这些事情,只需要专注自己的业务就好了。所以我们会不断的优化现有的解决方案,给用户更多更好的解决方案,下一步再将这些方案自动化,让用户用更低的成本使用我们的数据库。
最后一点「稳定性」也非常重要,就是让用户不会用着用着担惊受怕,比如半夜报警之类的事情。而且我们希望 TiDB 能在大规模数据集上、在大流量上也能保持稳定。
未完待续...
下篇将于明日推送,重点介绍 TiDB 3.0 Beta 在稳定性、易用性和功能性上的提升,以及 TiDB 在 Storage Layer 和 SQL Layer 方面的规划。













