
本文首发于 vivo互联网技术 微信公众号
链接:https://mp.weixin.qq.com/s/P-YdQPOQ9GZgjDEP7VG8ag
作者:Wang Zhenzheng
Puppeteer 是 Chrome开发团队2017年发布的一个 Node.js包,提供了一组用来操纵Chrome的API,通俗来说就是一个Headless Chrome浏览器,这Headless Chrome也可以配置成有UI的 。利用Puppeteer可以做到爬取页面数据,页面截屏或者生成PDF文件,前端自动化测试(模拟输入/点击/键盘行为)以及捕获站点的时间线,分析网站性能问题。
一、起因
虽说Puppeteer是Chrome开发团队2017年发布的一个 Node.js包,但是在团队日常工作中基本没有使用。前段时间在开发一个聊天工具的时候,需要引入emoji表情,但是业务方的需求是要使用Google emoji,那我们就需要在emojipedia上将这些图保存下来。这么多的图如果一张一张保存,那就枉为开发了。首先想到的是调用该页面的api接口,从接口中拿到对应的emoji地址然后遍历到本地文件。
尴尬的是这个页面是直出的,不是通过接口调用,那就需要我们换个思路,我们发现这些emoji的DOM是在一个class为emoji-grid的ul下,那么如果拿到该ul节点下的全部img的url,然后遍历到本地,是不是就做到将emoji表情保存下来。
依据这个思路,我们就想到使用Puppeteer,在介绍Puppeteer之前我们先将这段简单的捕获moji表情的代码放出来。
const puppeteer = require('puppeteer')
const request = require('request')
const fs = require('fs')
async function getEmojiImage (url) {
// 返回解析为Promise的浏览器
const browser = await puppeteer.launch()
// 返回新的页面对象
const page = await browser.newPage()
// 页面对象访问对应的url地址
await page.goto(url, {
waitUntil: 'networkidle2'
})
// 等待3000ms,等待浏览器的加载
await page.waitFor(3000)
// 可以在page.evaluate的回调函数中访问浏览器对象,可以进行DOM操作
const emojis = await page.evaluate(() => {
let ol = document.getElementsByClassName('emoji-grid')[0]
let imgs = ol.getElementsByTagName('img')
let url = []
for (let i = 0; i < 97; i++) {
url.push(imgs[i].getAttribute('src'))
}
// 返回所有emoji的url地址数组
return url
})
// 定义一个存在的json
let json = []
for (let i = 0; i < emojis.length; i++) {
const name = emojis[i].slice(emojis[i].lastIndexOf('/') + 1)
// 将emoji写入本地文件中
request(emojis[i]).pipe(fs.createWriteStream('./' + (i < 10 ? '0' + i : i) + name))
json.push({
name,
url: `./a/a/${name}` // 你的url地址
})
console.log(`${name}----emoji写入成功`)
}
// 写入json文件
fs.writeFile('./google-emoji.json', JSON.stringify(json), function () {})
// 关闭无头浏览器
await browser.close()
}
getEmojiImage('https://emojipedia.org/google/')
在了解Puppeteer之前,我们先来看下Headless Chrome。
二、Headless Chrome
Headless Chrome在Chrome59中发布,用于在headless环境中运行Chrome浏览器,也就是在非Chrome环境中运行Chrome。它将Chromium和Blink渲染引擎提供的所有现代Web平台功能引入命令行。
headless如何在终端中使用:我们尝试通过终端命令打开vivo 的官网
chrome --headless --disable-gpu --remote-debugging-port=8080 https://vivo.com.cn
注意:在Mac上使用前,建议先绑定Chrome的别名
alias chrome="/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome"
此时,Headless Chrome已经成功运行了,浏览器输入 http://127.0.0.1:8080,你会看到如下的vivo界面:
除此之外,还可以以命令行的形式去执行以下常见的操作:
1、打印DOM:
chrome --headless --disable-gpu --dump-dom https://vivo.com.cn
2、创建一个PDF文件
chrome --headless --disable-gpu --print-to-pdf https://vivo.com.cn
3、截屏
chrome --headless --disable-gpu --screenshot https://vivo.com.cn
// 设置截屏的尺寸
chrome --headless --disable-gpu --screenshot --window-size=1280,1696 https://vivo.com.cn
那么,Puppeteer是什么?又可以做些什么?Puppeteer是一个node库,提供了一组用来操纵Chrome的API,通俗来说就是一个Headless Chrome浏览器,这Headless Chrome也可以配置成有UI的,默认是没有的。
三、Puppeteer
Puppeteer可以做些什么呢?我们从文章开始的一个demo中可以发现,Puppeteer可以爬取页面数据。除此之外,结合Headless Chrome的一些命令行,Puppeteer可以做到一下几点:
- 爬取页面数据
- 页面截屏或者生成PDF文件
- 前端自动化测试(模拟输入/点击/键盘行为)
- 捕获站点的时间线,分析网站性能问题
1、初探
这是Puppeteer官方提供的一张API分层结构图
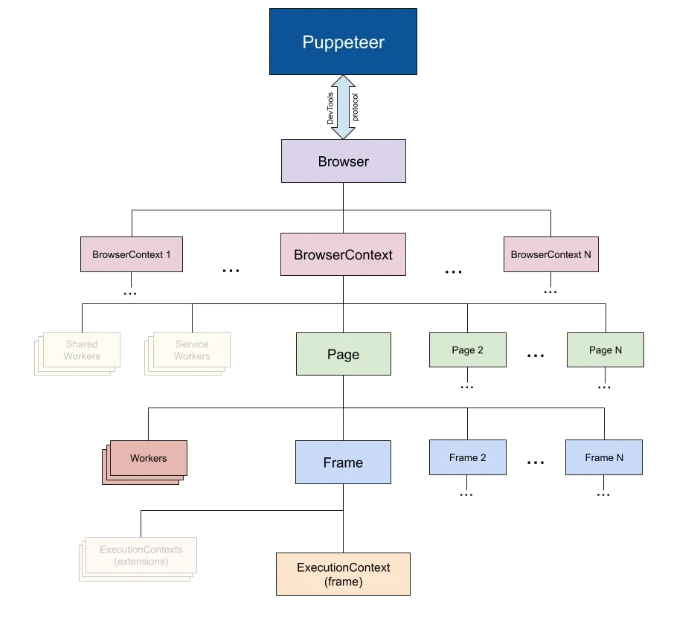
(图片来源于网络)
从图上我们可以发现,Puppeteer是通过使用Chrome DevTools Protocol(CDP)协议与浏览器进行通信,而Browser对应一个浏览器实例,可以拥有浏览器上下文,一个Browser可以包含多个BrowserContext。Page表示一个Tab页面,一个BrowserContext可以包含多个Page。每个页面都有一个主的Frame,ExecutionContext是Frame提供的一个JavasSript执行环境。
2、Browser
一切的起源都是从Browser开始的,我们先来梳理下Browser实例以后发生了什么。
首先,通过puppeteer.launch()创建一个Browser实例
const browser = await puppeteer.launch({
// --remote-debugging-port=3333会启一个端口,在浏览器中访问http://127.0.0.1:3333/可以查看
args: ['--remote-debugging-port=3333']
})
console.log(browser.wsEndpoint())
通过打印的browser.wsEndpoint(),我们看到输出一个如下的链接:
ws://127.0.0.1:57546/devtools/browser/5d6ee624-6b5e-4b8c-b284-5e4800eac853
这就是devTool用于连接调试页面的连接了,这个websocket连接遵循CDP协议,我们看下这里面具体有什么。
{"id":46,"method":"CSS.getMatchedStylesForNode","params":{"nodeId":5}}
{"id":47,"method":"CSS.getComputedStyleForNode","params":{"nodeId":5}}
每条信息的格式是有一个递增的id值,然后有method和params参数。这些消息指挥者被调试页面做出各种各样的动作。换而言之,任何一个实现了CDP的程序都可以用来调试页面,chrome 这个协议等于是开放了用程序控制页面动作的接口。比如我们可以这样子模拟一个alert到页面。
{"id":190,"method":"Runtime.compileScript","params":{"expression":"alert()","sourceURL":"","persistScript":false,"executionContextId":3}}
这种直接操作太不友好,而Puppeteer正是实现了遵循CDP的Node顶层API,使我们可以调用简单方便的操作对应的指令。
3、Page
browser.newPage()为Browser中浏览器上下文的方法。我们看下newPage()的代码实现。
/**
* @param {?string} contextId
* @return {!Promise<!Puppeteer.Page>}
*/
async _createPageInContext(contextId) {
const {targetId} = await this._connection.send('Target.createTarget', {url: 'about:blank', browserContextId: contextId || undefined});
const target = await this._targets.get(targetId);
assert(await target._initializedPromise, 'Failed to create target for page');
const page = await target.page();
return page;
}
this._connection.send('Target.createTarget',{})使用CDP中的Target.createTarget创建页面了页面,同样,在我们其他API时也是在使用CDP中的方法,例如page.goto()实际上是执行的是client.send('Page.navigate', {});。而在Page中的一些操作,如点击/模拟输入,则是调用的DomWorld实例,DomWorld通过FrameManager管理,Page对象主要使用三种manager来管理常见操作:
FrameManager:页面行为管理。如跳转goto,点击clcik,模拟输入type,等待加载waitFor等
NetworkManager:网络行为管理。如设置每个请求忽略缓存setCacheEnabled,请求拦截setRequestInterception等
EmulationManager:模拟行为管理。只有一个方法,emulateViewport,模拟设备与视口尺寸
四、应用
除了文章开始的抓取emoji表情外,我们尝试将Puppeteer应用在一个前端自动化测试的场景中,我们在后台管理系统开发测试中,经常会碰到表单的提交,对于表单中不同字段的校验需要模拟不同的场景,人工的点击效率低,而且每次都需要重复表单输入,比较繁琐。
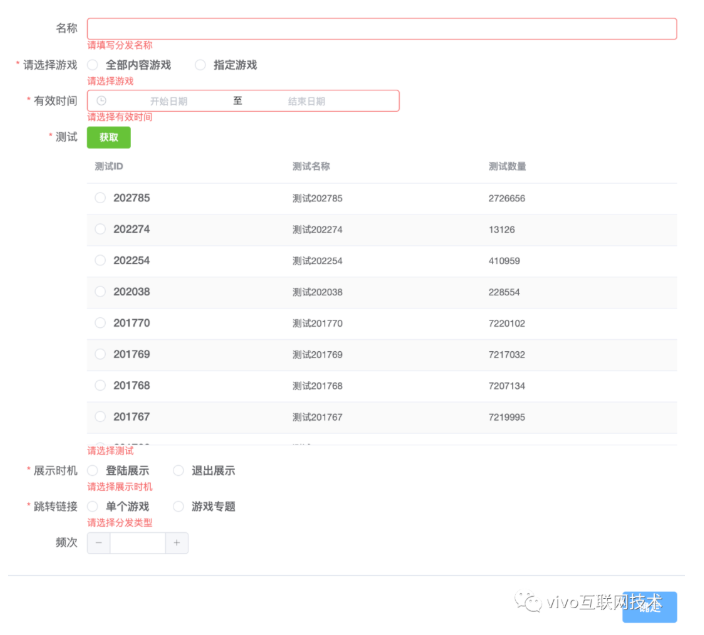
基于该场景,我们使用Puppeteer实现自动填写-保存-打印接口返回数据-截图。
STEP 1
创建一个Browser类的实例,并通过参数设置初始化它(更多设置参数参考官网API)
const browser = await puppeteer.launch({
devtools: true, //是否为每个选项卡自动打开DevTools面板
headless: false, //是否以无头模式运行浏览器。默认是true,除非devtools选项是true
defaultViewport: { width: 1000, height: 1200 }, //为每个页面设置一个默认视口大小
ignoreHTTPSErrors: true //是否在导航期间忽略 HTTPS 错误
})
STEP 2
创建一个 Page 实例,导航到一个url
const page = await browser.newPage()
await page.goto(url, {
waitUntil: 'networkidle0'
})
waitUntil参数是来确定满足什么条件才认为页面跳转完成。包括以下事件:
- load - 页面的load事件触发时
- domcontentloaded - 页面的DOMContentLoaded事件触发时
- networkidle0 - 不再有网络连接时触发(至少500毫秒后)
- networkidle2 - 只有2个网络连接时触发(至少500毫秒后)
该处用到的是不再有网络连接认为页面跳转完成。值得注意的是,后台管理系统会有token的校验,此处有两种解决方案,一种是等待页面自动跳转到登陆处,模拟登陆操作然后返回;一种是直接在cookie里设置token信息。我们采用第二种,代码如下:
const cookies = [
{
name: 'token',
value: 'system tokens', //你系统自己的token
domain: 'domain' //需要种在哪个domain下
}
]
await page.setCookie(...cookies)
STEP 3
模拟页面输入操作和点击事件,我们代码就只列举两个,不一一展开了。
// 操作input输入 132 ,delay参数表示输入延迟
await page.type('.el-form-item:nth-child(1) input', '132', { delay: 20 })
// 操作点击
await page.click('.el-form-item:nth-child(2) .el-form-item__content label:nth-child(1)')
STEP 4
监测页面是否有API响应,响应后将响应数据打印在控制台。
page.on('response', response => {
const req = response.request()
console.log(`Response的请求地址:${req.url()},请求方式是:${req.method()}, 请求返回的状态${response.status()},`)
let message = response.text()
message.then(function (result) {
console.log(`返回的数据:${result}`)
})
})
STEP 5
将操作后的页面信息截图保存
// 截取url中的路径标示,作为保存图片的命名,防止保存后覆盖
const testName = decodeURIComponent(url.split('#/')[1]).replace(/\//g, '-')
await page.screenshot({
path: `${testName}.png`,
fullPage: true
})
STEP 6
关闭Browser—await browser.close()
至此,我们完成了一个表单的自动化校验和测试。我们看下效果:
1.前端校验通过,请求到服务端接口的数据
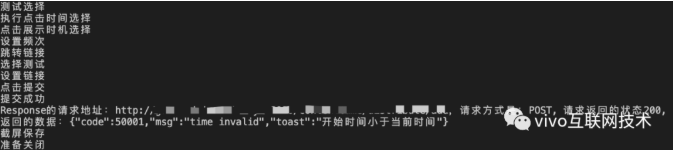
2.如果前端校验没通过,直接截图生成
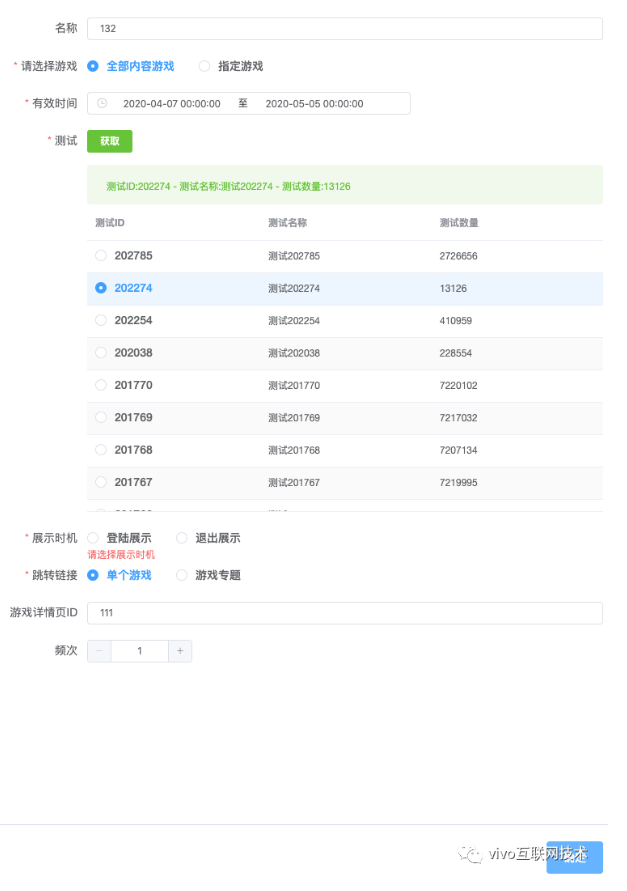
五、拓展
- 模拟线上环境点检操作走查
- 定时爬去周报日报数据,生成截图发送给相关人员查看
六、参考
https://developers.google.com/web/updates/2017/04/headless-chrome
https://peter.sh/experiments/chromium-command-line-switches/
更多内容敬请关注 vivo 互联网技术 微信公众号

注:转载文章请先与微信号:Labs2020 联系。











