
本文适合有 Python 基础的小伙伴进阶学习。

作者:pwwang
一、前言
本文基于开源项目:
补充扩展讲解,希望能够让读者一文搞懂 Python 的 import 机制。
1.1 什么是 import 机制?
通常来讲,在一段 Python 代码中去执行引用另一个模块中的代码,就需要使用 Python 的 import 机制。import 语句是触发 import 机制最常用的手段,但并不是唯一手段。
importlib.import_module 和 __import__ 函数也可以用来引入其他模块的代码。
1.2 import 是如何执行的?
import 语句会执行两步操作:
搜索需要引入的模块
将模块的名字做为变量绑定到局部变量中
搜索步骤实际上是通过 __import__ 函数完成的,而其返回值则会作为变量被绑定到局部变量中。下面我们会详细聊到 __import__ 函数是如果运作的。
二、import 机制概览
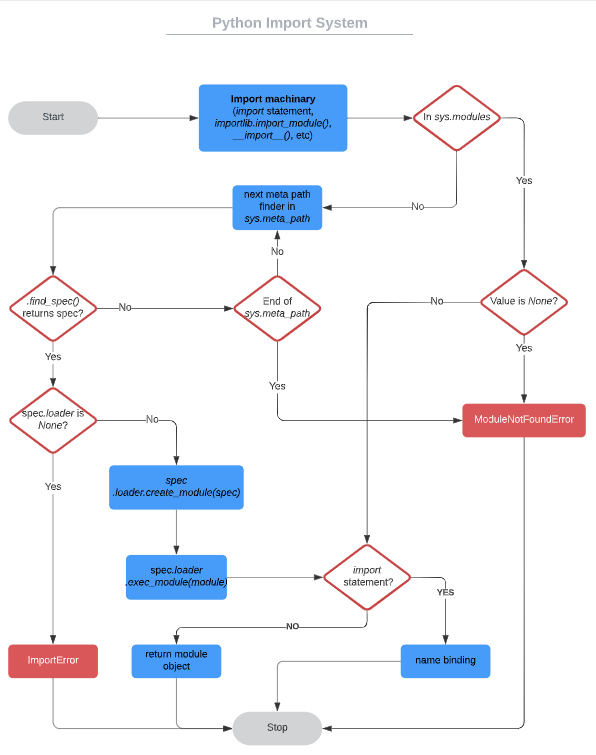
下图是 import 机制的概览图。不难看出,当 import 机制被触发时,Python 首先会去 sys.modules 中查找该模块是否已经被引入过,如果该模块已经被引入了,就直接调用它,否则再进行下一步。这里 sys.modules 可以看做是一个缓存容器。值得注意的是,如果 sys.modules 中对应的值是 None 那么就会抛出一个 ModuleNotFoundError 异常。下面是一个简单的实验:
In [1]: import sys
In [2]: sys.modules['os'] = None
In [3]: import os
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-3-543d7f3a58ae> in <module>
----> 1 import os
ModuleNotFoundError: import of os halted; None in sys.modules
如果在 sys.modules 找到了对应的 module,并且这个 import 是由 import 语句触发的,那么下一步将对把对应的变量绑定到局部变量中。
如果没有发现任何缓存,那么系统将进行一个全新的 import 过程。在这个过程中 Python 将遍历 sys.meta_path 来寻找是否有符合条件的元路径查找器(meta path finder)。sys.meta_path 是一个存放元路径查找器的列表。它有三个默认的查找器:
内置模块查找器
冻结模块(frozen module)查找器
基于路径的模块查找器。
In [1]: import sys
In [2]: sys.meta_path
Out[2]:
[_frozen_importlib.BuiltinImporter,
_frozen_importlib.FrozenImporter,
_frozen_importlib_external.PathFinder]
查找器的 find_spec 方法决定了该查找器是否能处理要引入的模块并返回一个 ModeuleSpec 对象,这个对象包含了用来加载这个模块的相关信息。如果没有合适的 ModuleSpec 对象返回,那么系统将查看 sys.meta_path 的下一个元路径查找器。如果遍历 sys.meta_path 都没有找到合适的元路径查找器,将抛出 ModuleNotFoundError。引入一个不存在的模块就会发生这种情况,因为 sys.meta_path 中所有的查找器都无法处理这种情况:
In [1]: import nosuchmodule
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-1-40c387f4d718> in <module>
----> 1 import nosuchmodule
ModuleNotFoundError: No module named 'nosuchmodule'
但是,如果这个手动添加一个可以处理这个模块的查找器,那么它也是可以被引入的:
In [1]: import sys
...:
...: from importlib.abc import MetaPathFinder
...: from importlib.machinery import ModuleSpec
...:
...: class NoSuchModuleFinder(MetaPathFinder):
...: def find_spec(self, fullname, path, target=None):
...: return ModuleSpec('nosuchmodule', None)
...:
...: # don't do this in your script
...: sys.meta_path = [NoSuchModuleFinder()]
...:
...: import nosuchmodule
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-6-b7cbf7e60adc> in <module>
11 sys.meta_path = [NoSuchModuleFinder()]
12
---> 13 import nosuchmodule
ImportError: missing loader
可以看到,当我们告诉系统如何去 find_spec 的时候,是不会抛出 ModuleNotFound 异常的。但是要成功加载一个模块,还需要加载器 loader。
加载器是 ModuleSpec 对象的一个属性,它决定了如何加载和执行一个模块。如果说 ModuleSpec 对象是“师父领进门”的话,那么加载器就是“修行在个人”了。在加载器中,你完全可以决定如何来加载以及执行一个模块。这里的决定,不仅仅是加载和执行模块本身,你甚至可以修改一个模块:
In [1]: import sys
...: from types import ModuleType
...: from importlib.machinery import ModuleSpec
...: from importlib.abc import MetaPathFinder, Loader
...:
...: class Module(ModuleType):
...: def __init__(self, name):
...: self.x = 1
...: self.name = name
...:
...: class ExampleLoader(Loader):
...: def create_module(self, spec):
...: return Module(spec.name)
...:
...: def exec_module(self, module):
...: module.y = 2
...:
...: class ExampleFinder(MetaPathFinder):
...: def find_spec(self, fullname, path, target=None):
...: return ModuleSpec('module', ExampleLoader())
...:
...: sys.meta_path = [ExampleFinder()]
In [2]: import module
In [3]: module
Out[3]: <module 'module' (<__main__.ExampleLoader object at 0x7f7f0d07f890>)>
In [4]: module.x
Out[4]: 1
In [5]: module.y
Out[5]: 2
从上面的例子可以看到,一个加载器通常有两个重要的方法 create_module 和 exec_module 需要实现。如果实现了 exec_module 方法,那么 create_module 则是必须的。如果这个 import 机制是由 import 语句发起的,那么 create_module 方法返回的模块对象对应的变量将会被绑定到当前的局部变量中。如果一个模块因此成功被加载了,那么它将被缓存到 sys.modules。如果这个模块再次被加载,那么 sys.modules 的缓存将会被直接引用。
三、import 勾子(import hooks)
为了简化,我们在上述的流程图中,并没有提到 import 机制的勾子。实际上你可以添加一个勾子来改变 sys.meta_path 或者 sys.path,从而来改变 import 机制的行为。上面的例子中,我们直接修改了 sys.meta_path。实际上,你也可以通过勾子来实现:
In [1]: import sys
...: from types import ModuleType
...: from importlib.machinery import ModuleSpec
...: from importlib.abc import MetaPathFinder, Loader
...:
...: class Module(ModuleType):
...: def __init__(self, name):
...: self.x = 1
...: self.name = name
...:
...: class ExampleLoader(Loader):
...: def create_module(self, spec):
...: return Module(spec.name)
...:
...: def exec_module(self, module):
...: module.y = 2
...:
...: class ExampleFinder(MetaPathFinder):
...: def find_spec(self, fullname, path, target=None):
...: return ModuleSpec('module', ExampleLoader())
...:
...: def example_hook(path):
...: # some conditions here
...: return ExampleFinder()
...:
...: sys.path_hooks = [example_hook]
...: # force to use the hook
...: sys.path_importer_cache.clear()
...:
...: import module
...: module
Out[1]: <module 'module' (<__main__.ExampleLoader object at 0x7fdb08f74b90>)>
四、元路径查找器(meta path finder)
元路径查找器的工作就是看是否能找到模块。这些查找器存放在 sys.meta_path 中以供 Python 遍历(当然它们也可以通过 import 勾子返回,参见上面的例子)。每个查找器必须实现 find_spec 方法。如果一个查找器知道怎么处理将引入的模块,find_spec 将返回一个 ModuleSpec 对象(参见下节)否则返回 None。
和之前提到的一样 sys.meta_path 包含三种查找器:
内置模块查找器
冻结模块查找器
基于路径的查找器
这里我们想重点聊一聊基于路径的查找器(path based finder)。它用于搜索一系列 import 路径,每个路径都用来查找是否有对应的模块可以加载。默认的路径查找器实现了所有在文件系统的特殊文件中查找模块的功能,这些特殊文件包括 Python 源文件(.py 文件),Python 编译后代码文件(.pyc 文件),共享库文件(.so 文件)。如果 Python 标准库中包含 zipimport,那么相关的文件也可用来查找可引入的模块。
路径查找器不仅限于文件系统中的文件,它还可以上 URL 数据库的查询,或者其他任何可以用字符串表示的地址。
你可以用上节提供的勾子来实现对同类型地址的模块查找。例如,如果你想通过 URL 来 import 模块,那么你可以写一个 import 勾子来解析这个 URL 并且返回一个路径查找器。
注意,路径查找器不同于元路径查找器。后者在 sys.meta_path 中用于被 Python 遍历,而前者特指基于路径的查找器。
五、ModuleSpec 对象
每个元路径查找器必须实现 find_spec 方法,如果该查找器知道如果处理要引入的模块,那么这个方法将返回一个 ModuleSpec 对象。这个对象有两个属性值得一提,一个是模块的名字,而另一个则是查找器。如果一个 ModuleSpec 对象的查找器是 None,那么类似 ImportError: missing loader 的异常将会被抛出。查找器将用来创建和执行一个模块(见下节)。
你可以通过 <module>.__spec__ 来查找模块的 ModuleSpec 对象:
In [1]: import sys
In [2]: sys.__spec__
Out[2]: ModuleSpec(name='sys', loader=<class '_frozen_importlib.BuiltinImporter'>)
六、加载器(loader)
加载器通过 create_module 来创建模块以及 exec_module 来执行模块。通常如果一个模块是一个 Python 模块(非内置模块或者动态扩展),那么该模块的代码需要在模块的 __dict__ 空间上执行。如果模块的代码无法执行,那么就会抛出ImportError 异常,或者其他在执行过程中的异常也会被抛出。
绝大多数情况下,查找器和加载器是同一个东西。这种情况下,查找器的 find_spec 方法返回的 ModuleSpec 对象的 loader 属性将指向它自己。
我们可以用 create_module 来动态创建一个模块,如果它返回 None Python 会自动创建一个模块。
七、总结
Python 的 import 机制灵活而强大。以上的介绍大部分是基于官方文档,以及较新的 Python 3.6+ 版本。由于篇幅,还有很多细节并没有包含其中,例如子模块的加载、模块代码的缓存机制等等。
**-----**------**-----**---**** End **-----**--------**-----**-****

往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/Y-swJ8YI70vxCvszRMeT_w,如有侵权,请联系删除。











