
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


点击右侧关注,大数据开发领域最强公众号!


点击右侧关注,暴走大数据!

《Kafka重要知识点之消费组概念》讲到了kafka的消费组相关的概念,消费组有多个消费者,消费组在消费一个Topic的时候,kafka为了保证消息消费不重不漏,kafka将每个partition唯一性地分配给了消费者。但是如果某个消费组在消费的途中有消费者宕机或者有新的消费者加入的时候那么partition分配就是不公平的,可能导致某些消费者负载特别重,某些消费者又没有负载的情况。Kafka有一种专门的机制处理这种情况,这种机制称为Rebalance机制。
当kafka遇到如下四种情况的时候,kafka会触发Rebalance机制:
消费组成员发生了变更,比如有新的消费者加入了消费组组或者有消费者宕机
消费者无法在指定的时间之内完成消息的消费
消费组订阅的Topic发生了变化
订阅的Topic的partition发生了变化
1. 消费超时实践
笔者针对上文的第二个原因笔者有如下两个疑问
消费者默认消费超时的时间是多少
消息消费超时的时候会发生什么
于是笔者在Test-Group分组下创建了8个消费者线程,提交消息改为手动提交,并且消费完成一批消息后,让笔者让消费线程睡眠15秒
代码如下
public void consume() { try { while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.printf("id = %d , partition = %d , offset = %d, key = %s, value = %s%n", id, record.partition(), record.offset(), record.key(), record.value()); } try { TimeUnit.SECONDS.sleep(15); } catch (InterruptedException e) { e.printStackTrace(); } //手动提交offset consumer.commitSync(); } } finally { consumer.close(); }}
多消费者运行代码如下
public static void main(String[] args) throws InterruptedException { for (int i = 0; i < 8; i++) { final int id = i; new Thread() { @Override public void run() { new ReblanceConsumer(id).consume(); } }.start(); } TimeUnit.SECONDS.sleep(Long.MAX_VALUE);}
运行过程中,消费者抛出了如下消费者消费异常
[Consumer clientId=client-5, groupId=Test-Group] This member will leave the group because consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.
在手动提交offset的时候抛出了如下异常
Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.
在这一节,笔者只介绍第一个异常(第二个异常笔者将在Generation机制中介绍),抛出第一个异常的原因是消费超时,导致消费线程长时间无法向Coordinator节点发送心跳,Coordinator节点以为Consumer已经宕机,Coordinator于是将Consumer节点从消费组中剔除,并触发了Rebalance机制。其实这和Consumer的心跳发送机制也有关系。在大多数中间件的设计中都会分离业务线程和心跳发送线程,目的就是避免业务线程长时间执行业务流程,导致长时间无法发送心跳。但是kafka却没有这样做,kafka的目的可能是为了实现简单。如果消费者消费业务确实需要非常长时间,我们可以通过参数max. poll. interval. ms配置,它代表消费两次poll最大的时间间隔,比如将其配置成60s
props.put("max.poll.interval.ms", "60000");
或者我们可以减少consumer每次从broker拉取的数据量,consumer默认拉取500条,我们可以将其修改了50条
props.put("max.poll.records", "50");
Kafka在后续的新版本中修正了Consumer的心跳发送机制,将心跳发送的任务交给了专门的HeartbeatThread。那么max.poll.interval.ms参数还有意义么?该参数其实还是有意义,因为即使心跳发送正常,那也只能证明Consumer是存活状态,但是Consumer可能处于假死状态,比如Consumer遇到了死锁导致长时间等待超过了poll设定的时间间隔max.poll.interval.ms。
在这一节,笔者熟悉了会触发kafka Rebalance机制的第二种情况以及应对措施,接下来,笔者将深入介绍kafka的重平衡机制
2. Coordinator
在介绍Rebalance机制之前,笔者想先介绍一下Coordinator,它是Rebalance机制中非常重要的一个角色。每个消费组都会有一个coordinator,Coordinator负责处理管理组内的消费者和位移管理,Coordinator并不负责消费组内的partition分配。消费者通过心跳的方式告知Coordinator自己仍然处于存活状态,Coordinator以session. timeout. ms参数的频率检测消费组group内消费者存活情况,该参数的默认值是10s,如果该值太大,那么coordinator需要非常长时间才能检测到消费者宕机
选举机制
如果kafka集群有多个broker节点,消费组会选择哪个partition节点作为Coordinator节点呢?它会通过如下公式,其中的50代表着kafka内部主题consumer offset的分区总数
Math.abs(hash(groupID)) % 50
那么当前Consumer Group的Coordinator就是上述公式计算出的partition的leader partition
3. Rebalance流程
Coordinator发生Rebalance的时候,Coordinator并不会主动通知组内的所有Consumer重新加入组,而是当Consumer向Coordinator发送心跳的时候,Coordinator将Rebalance的状况通过心跳响应告知Consumer。Rebalance机制整体可以分为两个步骤,一个是Joining the Group,另外一个是分配Synchronizing Group State
3.1 Joining the Group
在当前这个步骤中,所有的消费者会和Coordinator交互,请求Coordinator加入当前消费组。Coordinator会从所有的消费者中选择一个消费者作为leader consumer, 选择的算法是随机选择
3.2 Synchronizing Group State
leader Consumer从Coordinator获取所有的消费者的信息,并将消费组订阅的partition分配结果封装为SyncGroup请求,需要注意的是leader Consumer不会直接与组内其它的消费者交互,leader Consumer会将SyncGroup发送给Coordinator,Coordinator再将分配结果发送给各个Consumer。分配partition有如下3种策略RangeAssignor,RoundRobinAssignor,StickyAssignor,关于这三种分配方案更详细的资料请看上一篇文章
如果leader consumer因为一些特殊原因导致分配分区失败(Coordinator通过超时的方式检测),那么Coordinator会重新要求所有的Consumer重新进行步骤Joining the Group状态
4. Coordinator生命周期
为了更好的了解Coordinator的职责以及Rebalance机制,笔者详细介绍一下Coordinator的生命周期
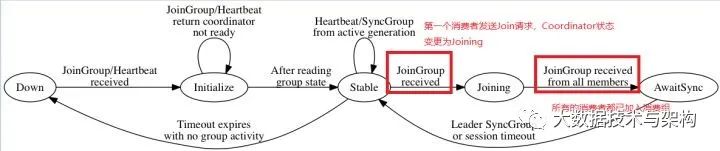
Coordinator生命周期中总共有5种状态,Down,Initialize,Stable,Joining,AwaitingSync
Down:Coordinator不会维护任何消费组状态
Initialize:Coordinator处于初始化状态,Coordinator从Zookeeper中读取相关的消费组数据,这个时候Coordinator对接受到消费者心跳或者加入组的请求都会返回错误
Stable:Coordinator处理消费者心跳请求,但是还未开始初始化generation,Coordinator正在等待消费者加入组的请求
Joining:Coordinator正在处理组内成员加入组的请求
AwaitingSync:等待leader consumer分配分区,并将分区分配结果发送给各个Consumer
这五个状态相互转换流程图示如下,其中的重点用红框标出,它们对应着Rebalance的流程步骤
5. Generation机制
在上文中提到消费者消费消息超时之后,如果再次尝试提交offset,就会出现如下的异常
Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.
出现该异常的原因是Coordinator消费组的保护机制。上文提到如果消费者消费超时,笔者称其为TimeoutConsumer,那么TimeoutConsumer就会被Coordinator从消费组中剔除,Coordinator就会进行Rebalance,将当前消费者负责的partition重新分配给其它的消费者,如果TimeoutConsumer完成了消息的消费,假设TimeoutConsumer成功提交partition的offset,那么就会出现混乱,因为TimeoutConsumer负责的partition已经被分配给了其它的消费者。Generation(代际)机制就是上述的保护机制。
Coordinator每进行一次Rebalance,就会为当前的Rebalance设置一个Generation标记,比如说第一次Rebalance标记是1,如果再次Rebalance,该标记就会成为2,消费者在提交offset的时候会将generation一同提交,Coordinator在发现TimeoutConsumer的标记已经超时的情况下会拒绝消费者提交generation标记。
Generation的机制可能会导致上一代际消费者和当前代际消费者消费相同的消息,所以消费者在消费消息的时候需要实现消息消费的幂等性,关于幂等性消费的问题笔者将会写一瓶文章详细介绍。
6. Leader Consumer
上文提到Leader Consumer是Coordinator在Joining the Group步骤的时候随机选择的,Leader Consumer负责组内各个Consumer的partition分配,除此之外Leader Consumer还负责整个消费组订阅的主题的监控,Leader Consumer会定期更新消费组订阅的主题信息,一旦发现主题信息发生了变化,Leader Consumer会通知Coordinator触发Rebalance机制。


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。
编辑|冷眼丶
微信公众号|import_bigdata
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











