redis持久化策略
redis是一个内存数据库,但是它提供了持久化机制。即把数据永久的存储在磁盘上。我们来看看这个redis保存数据的流程
(1)客户端向服务端发送写操作(数据在客户端的内存中)。
(2)数据库服务端接收到写请求的数据(数据在服务端的内存中)。
(3)服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
(4)操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
(5)磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
这里有五步,正常情况下是能够把数据持久化到磁盘的,但是在大多数情况下,我们的机器等等都会有各种各样的故障,那么数据就可能损坏,数据损坏之后,redis是怎么回复的呢,这就涉及到redis的持久化策略
RDB机制
RDB其实就是把数据以快照的形式保存在磁盘上,既然需要存数据,那么RDB机制是怎么处罚的呢?即redis何时才会把数据以快照的形象保存在磁盘上呢?
redis提供了三种方式:save、bgsave、自动化
save
执行save命令,该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。
执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
bgsave
执行bgsave命令,执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求
具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
自动触发
在redis.conf配置文件进行配置
比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
附-其他一些相关配置:
**stop-writes-on-bgsave-error :**默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
**rdbcompression ;**默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
**rdbchecksum :**默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
**dbfilename :**设置快照的文件名,默认是 dump.rdb
**dir:**设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。
AOF机制
redis会将每一个收到的写命令都通过write函数追加到AOF文件中。即日志记录。
当然,AOF文件会越来越大,所以redis会fork出一条新进程来将文件重写。
在redis.conf文件中,AOF机制有以下几种配置:
always:每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
everysec:每秒记录,所以可能出现一秒数据丢失
正常来说,redis持久化是需要两者加一起才更好。
redis线程模型
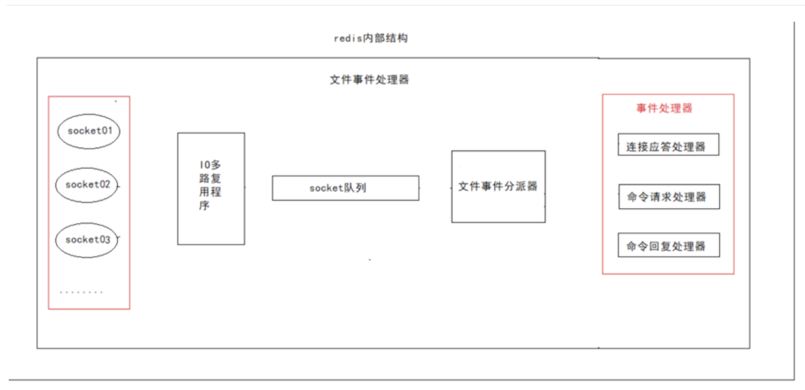
redis单线程模型中最为核心的就是文件事件处理器
文件事件处理器包含:多个socket、IO多路复用程序、socket队列、文件事件分派器、以及事件处理器
redis的单线程指的就是socket队列,IO多路复用程序会把监听有请求进来后,会将消息放入队列中,文件分配器再从队列中取出消息,然后再交给事件处理器。事件处理器会从对应的socket上读取相关的数据,处理完成后,,产生AE_WRITABLE事件,并准备好准备好相应的响应数据,然后由对应的命令回复处理器处理后返回对应的socket,返回给客户端.
如下图: 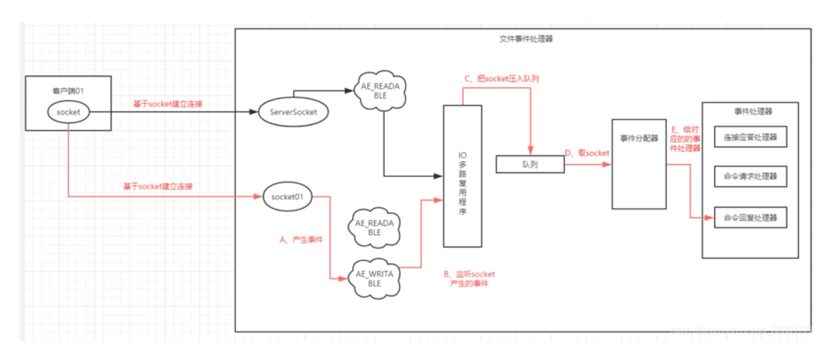
所以,通常所说的redis单线程是对应IO多路复用器及队列而说的,其实redis还是多线程的,比如AOF和RDB,都是fork子线程完成,上图事件处理器等,也是多线程完成。下文中提到的定时删除过期key,也是多线程的
redis key过期策略
1、惰性删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
2、主动删除:Redis执行定时任务,删除过期的key
3、当前已用内存超过限定内存时,会触发主动清除
在 Redis 中, 常规操作由 redis.c/serverCron 实现, 它主要执行以下操作
- 更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等。
- 清理数据库中的过期键值对。
- 对不合理的数据库进行大小调整。
- 关闭和清理连接失效的客户端。
- 尝试进行 AOF 或 RDB 持久化操作。
- 如果服务器是主节点的话,对附属节点进行定期同步。
- 如果处于集群模式的话,对集群进行定期同步和连接测试。
maxmemory 当前已用内存超过maxmemory限定时,触发主动清理策略
配置如下:
- volatile-lru:只对设置了过期时间的key进行LRU(默认值)
- allkeys-lru : 删除lru算法的key
- volatile-random:随机删除即将过期key
- allkeys-random:随机删除
- volatile-ttl : 删除即将过期的
- noeviction : 永不过期,返回错误
redis集群hash槽为什么是16383
我们知道,对于redis集群,当客户端请求key时,根据公式HASH_SLOT=CRC16(key) mod 16384,计算出映射到哪个分片上,然后Redis会去相应的节点进行操作!
CRC16算法产生的hash值有16bit,该算法可以产生2^16-=65536个值,那么正常凯硕,redis的hash槽应该是65536。
以下为作者的解答:
The reason is:
- Normal heartbeat packets carry the full configuration of a node, that can be replaced in an idempotent way with the old in order to update an old config. This means they contain the slots configuration for a node, in raw form, that uses 2k of space with16k slots, but would use a prohibitive 8k of space using 65k slots.
- At the same time it is unlikely that Redis Cluster would scale to more than 1000 mater nodes because of other design tradeoffs.
So 16k was in the right range to ensure enough slots per master with a max of 1000 maters, but a small enough number to propagate the slot configuration as a raw bitmap easily. Note that in small clusters the bitmap would be hard to compress because when N is small the bitmap would have slots/N bits set that is a large percentage of bits set.
https://github.com/antirez/redis/issues/2576
在redis集群中,各个节点之间需要知道彼此的存在,他们之间定期都在发送ping/pong消息,交换数据信息。
数据结构如下: 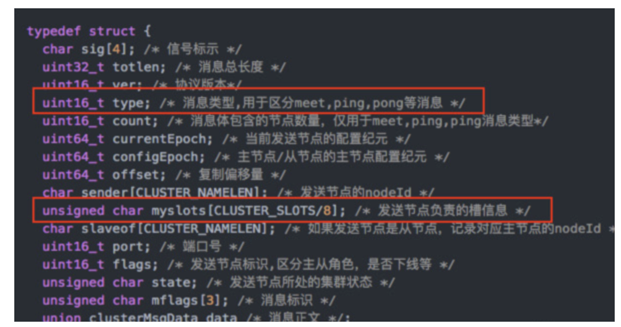
我们看到有个myslots字段,发送节点负责的槽信息,长度为[CLUSTER_SLOTS/8]
假设CLUSTER_SLOTS是65536,那么myslots的长度为:65536/8/1024=8K
假设CLUSTER_SLOTS是16384,那么myslots的长度为:16384/8/1024=2K
8K是2K的4倍,势必浪费带宽
定期发送消息的频率:
(1)每秒会随机选取5个节点,找出最久没有通信的节点发送ping消息
(2)每100毫秒(1秒10次)都会扫描本地节点列表,如果发现节点最近一次接受pong消息的时间大于cluster-node-timeout/2 则立刻发送ping消息
因此,每秒单节点发出ping消息数量为
数量=1+10*num(node.pong_received>cluster_node_timeout/2)
redis节点个数:redis的集群主节点数量基本不可能超过1000个,试想,没如果redis节点超过1000个,在1000个节点里面发送ping/pong消息,可能造成网络拥堵。
那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
当然,还有压缩比的考虑,redis所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中,会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。
综上所述,作者决定取16384个槽,不多不少,刚刚好!
redis为什么使用hash槽,而不使用一致性hash
一致性hash实际上是将整个hash值空间组织成一个圆环,hash值空间有2的32次方-1个数,并通过虚拟节点解决圆环分配不均匀的问题;
一致性hash有点:
1、扩展性:当扩展一个节点时,只影响顺时针遇到的数据;
2、容错性:当节点故障时,只影响逆时针遇到的数据
缺点:当增删节点时,需要找出影响的节点;
这中情况下,redis只能当缓存,不能当数据库使用;
所以redis使用hash槽,
当增删节点时,我们可以精准的知道影响的槽位,并进行数据迁移。
集群进入fail状态的必要条件
A、某个主节点和所有从节点全部挂掉,我们集群就进入faill状态。
B、如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态.
C、如果集群任意master挂掉,且当前master没有slave.集群进入fail状态
投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超时(cluster-node-timeout),认为当前master节点挂掉。
选举的依据依次是:网络连接正常->5秒内回复过INFO命令->10*down-after-milliseconds内与主连接过的->从服务器优先级->复制偏移量->运行id较小的。选出之后通过slaveif no ont将该从服务器升为新主服务器。
通过slaveof ip port命令让其他从服务器复制该信主服务器。