
阿里云坚持将计算能力变成像水电煤一样的公共服务,提供给大众,而非单单而不是卖服务器给客户,这跟今日流行的Serverless 架构理念是一致的。Serverless 理念在数加平台得到了很好的体现,数加平台今天已经可以提供很多业务场景化的计算服务,比如推荐引擎,规则引擎,以及各种人工智能的服务,助力企业在DT时代更敏捷、更智能、更具洞察力。在本文中,班输从数据平台简介、大数据应用特点、数加平台Serverless架构解析和典型案例四部分讲述了数据平台如何利用Serverless 的架构来降低大数据应用的门槛,实现数据普惠。
以下内容根据分享视频和PPT整理。
数加平台简介

数加是阿里云大数据的品牌名,旗下包含一系列的大数据产品及服务,其目的是为大众提供一站式数据开发、分析、应用平台。开发者使用数加平台可以快速构建数据支撑的应用。数加平台的产品具体分为两大部分:基础平台和数据应用。前者包括大数据产品主要有数据开发、机器学习、大数据计算、分析型数据库、流计算等;后者主要包括推荐引擎、人脸识别、数据可视化DataV等应用。
在数加平台,各种计算服务开箱即用,用户不必关心大数据集群的搭建、配置和运维工作,仅需简单的几步操作,用户就可以在数加平台中上传数据、分析数据并得到分析结果。用户不必关心数据规模增长带来的存储困难、运算时间延长等烦恼,数加平台根据用户的数据规模自动扩展大数据集群的存储和计算能力,使用户专心于数据分析和挖掘,最大化发挥数据的价值。
大数据应用的特点
大数据的价值需要借助一些具体的应用模式和场景才能得到集中体现。相比于传统应用,大数据应用具有以下特点:
- 流程长,业务逻辑复杂:从数据的采集、存储、分析、挖掘到最终提供数据服务,需要把多种数据源融合入,关联分析,复杂度大大增加。
- 场景多样化,不确定性强:大数据相关的应用要产生价值,需要和业务紧密结合。现实中很多场景都具有探索性质,并且要随着业务变化和反馈持续地调整,灵活性要求很高。
- 技术门槛高:在大数据应用中存在多种技术引擎,如离线、在线、流式引擎,以及多种计算模型,如SQL、MR、机器学习,很多场景下需要这些工具组合使用。
上述特点使得从头搭建一个完成的大数据应用平台的难度成倍增加,大型公司内需要专门的团队应对开发、维护等工作;对于小型公司几乎是不可能完成的任务。那么如何把企业内有限的数据科学家从基础设施构建和运维的复杂性中解放出来呢?数加平台给出的答案是:Serverless架构。Serverless架构以服务的形式来提供计算能力而不是以服务器形式,让开发者在构建应用的过程中不用过多考虑基础设施的问题。这个理念在数加平台中得到了很好的体现。
数加平台Serverless架构解析
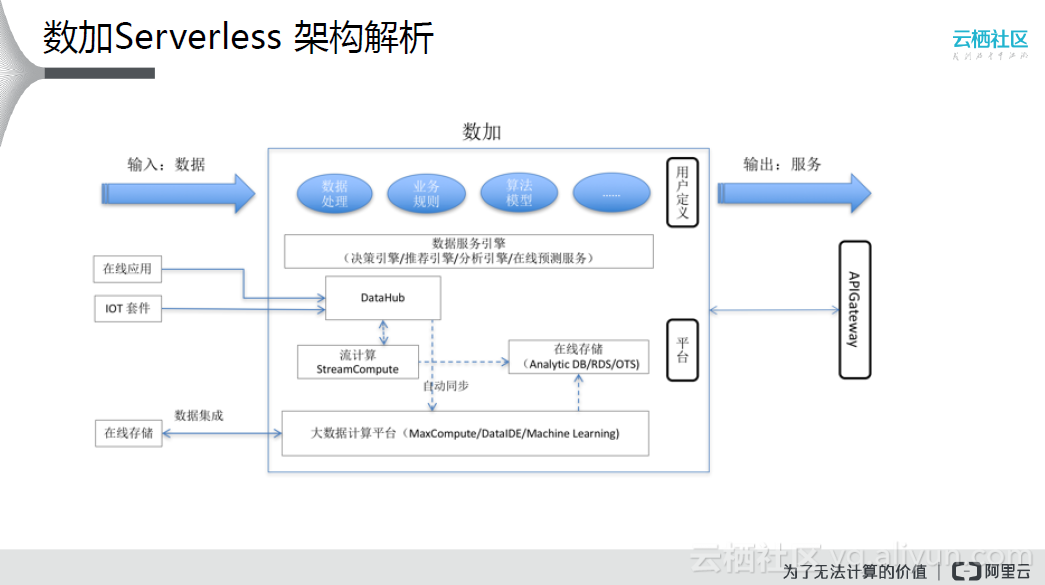
如上图所示,数加平台的输入是大量的数据,然后将数据进行融合,通过特定的计算或算法将其变成对业务有价值的服务,输出给用户;数加平台从底层将整个数据应用链路打通,提供了从数据采集、存储、处理等模块;用户需要做的就是开发、配置业务相关的处理逻辑、业务规则和确定所需算法;此外,数据平台还提供了服务的编排、管理、运维等功能,真正地将开发者从底层技术实现和运维管理以及资源调度方面解放出来,将精力集中于数据价值实现上,完美地诠释了Serverless的架构理念。
下面以数加平台最重要的大数据产品MaxCompute 为例,深入讲解。
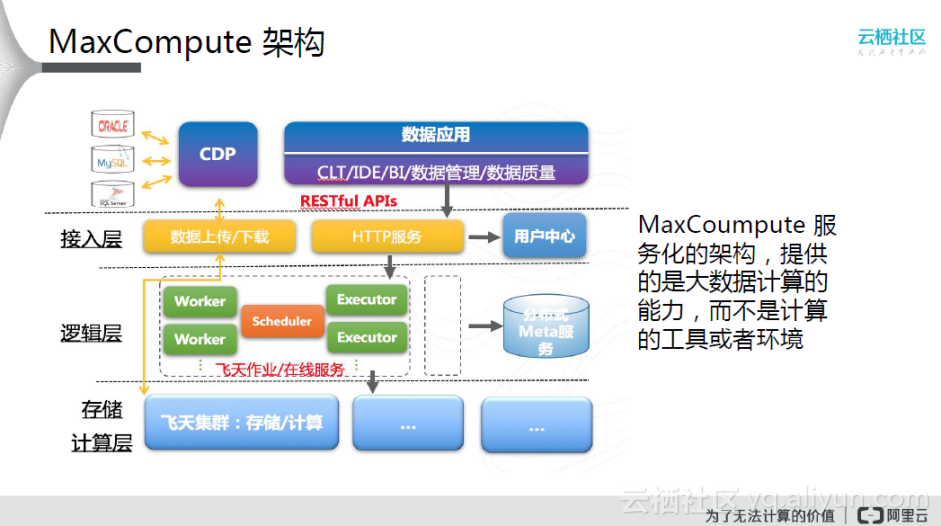
MaxCompute的服务化架构图如上所示,它提供的是大数据计算能力,而不是计算的工具或环境;它向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速地解决用户海量数据计算问题,有效降低企业成本,并保障数据安全;MaxCompute主要服务于批量结构化数据的存储和计算,可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务,其上的全部能力均已通过API的形式对外提供,当数据需要存储、处理时,仅需调用相应的API即可得到目标结果,也就是说用户可以不必关心分布式计算细节,从而达到分析大数据的目的。
目前,数加平台已经在企业界得到了大规模应用:
- 物联网大数据应用:通过组合使用数加平台提供的Datahub、StreamCompute、MaxCompute、DataV等服务实现物联网数据的分析应用;
- 预测即服务:组合使用数加平台提供的MaxCompute、机器学习、在线预测等服务实现孩子成绩的预测;
- 个性化推荐:使用数加平台的推荐引擎快速搭建个性化推荐系统。
典型场景实践分享
接下来,将结合几个具体的应用案例讲解数加平台在各方面的实践经验。
物联网案例:智慧水务
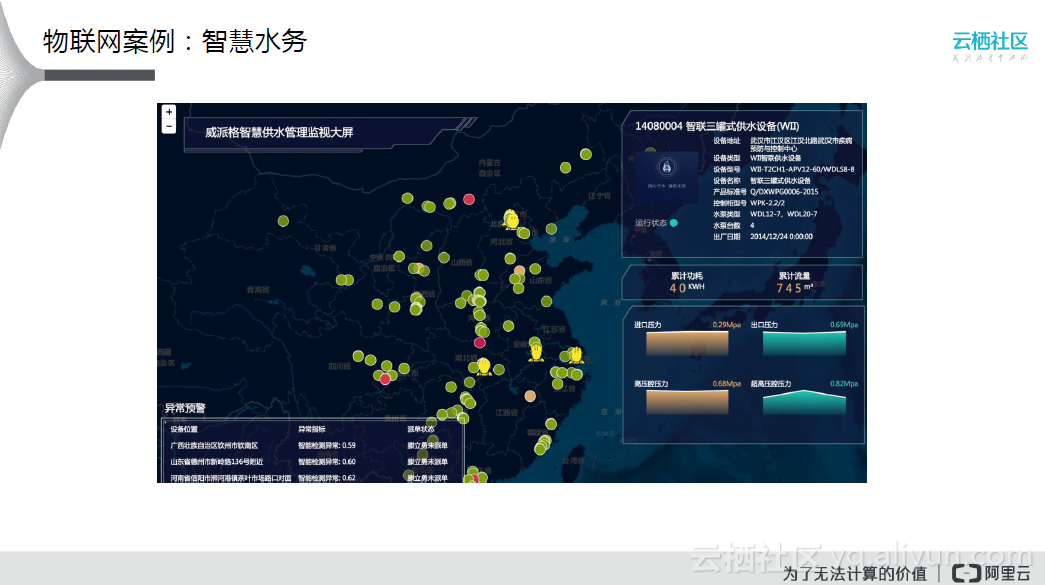
通过IoT 设备对水务设备的流量、水压等数据进行实时采集和监控,再通过简单的配置将数据实时对接到大数据平台的DataHub,通过监控大屏进行实时控制。
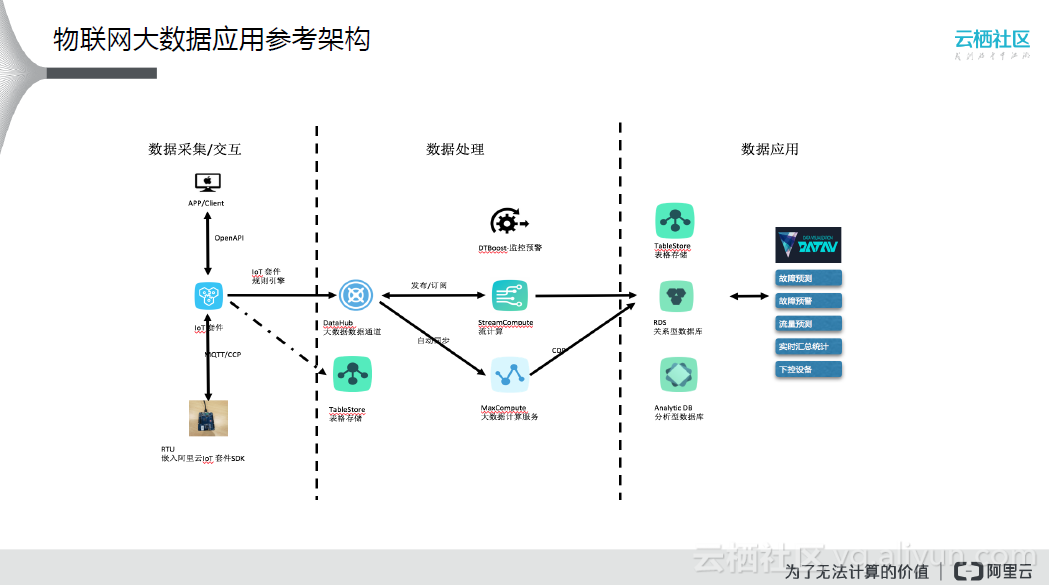
上图是通用的物联网大数据应用参考架构。最前端是数据采集模块,然后进行数据存储,通过某些算法、模型发掘数据中的价值,最后变成有效的应用,如:
- 可视化的展示,将水务整体的运行状态展示出来;
- 故障预测,通过已有数据的分析,提前对可能发生故障的管道进行预测,提前维护。
在物联网应用场景中,通过数加平台提供的离线存储和计算、流式计算、机器学习模型训练、数据可视化等等大数据服务,有效地解放了使用者,他们只需关注流式计算SQL的开发、业务规则的配置以及偏好业务算法的参数配置,而无需关心底层的平台搭建、不同引擎之间的数据流转等问题,大大提升了开发效率。
个性化推荐案例
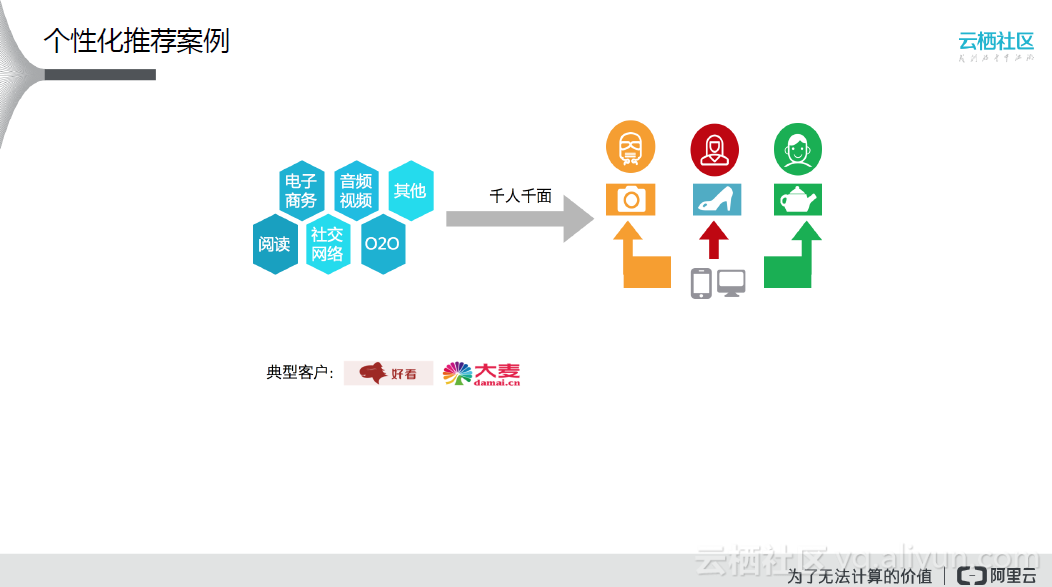
个性化推荐是目前非常通用的大数据场景,所谓的个性化推荐是指对根据不同的用户喜好,定性地进行产品的推送。在这个过程中,需要对用户和产品的特征进行准确地把握。
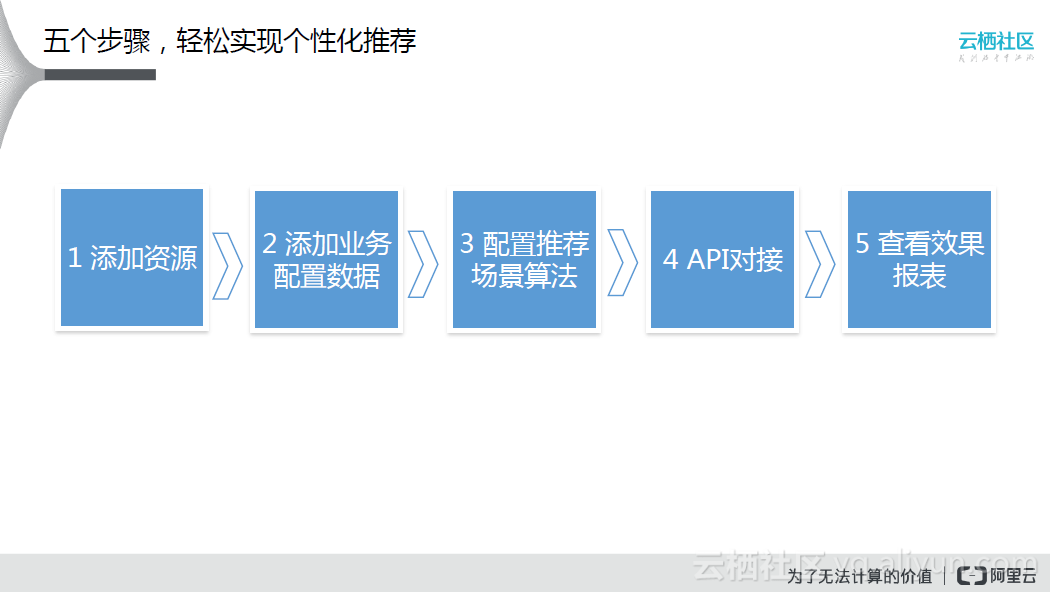
利用数据平台提供的服务,可以快速地实现个性化推荐,具体配置包括以下五步:
- 添加资源,个性化推荐会涉及到离线模型训练、在线模型修正,以及Key-Value存储、MaxCompute计算等服务,所谓添加资源就是将这些服务添加进来;
- 添加业务、配置数据,即将多维度用户和产品的数据添加到个性化推荐引擎中;
- 配置推荐场景算法,在数加平台中一些常见的算法也是以服务形态提供的,使用者需要根据不同的应用场景选择合适的算法。
- API对接,上述配置完成后,再进行API对接。
- 查看效果报表,形成大数据应用的闭环,通过反馈修正算法和模型。
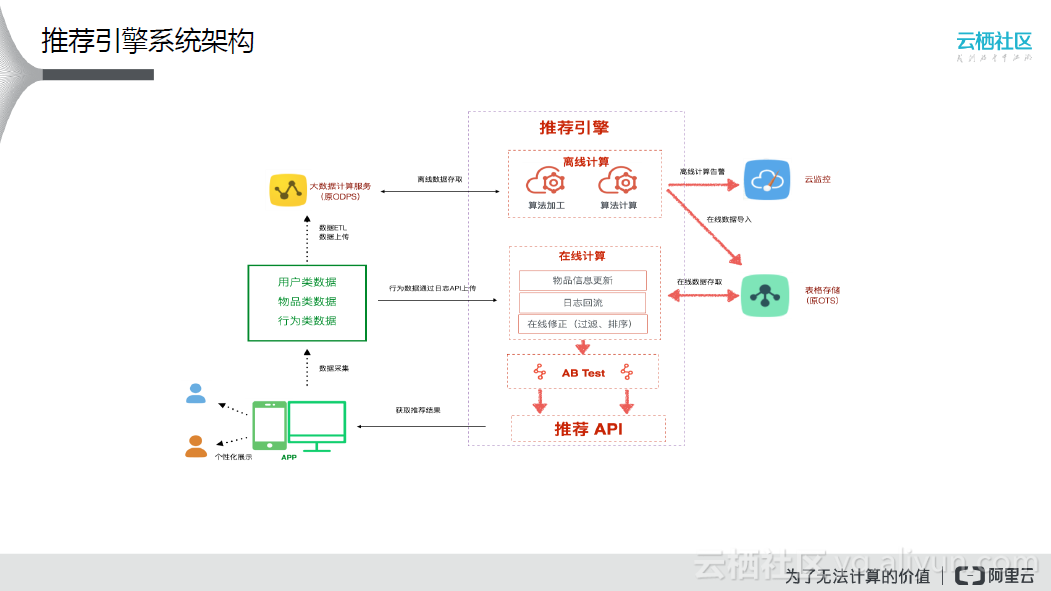
上图是推荐引擎的通用系统架构,中间部分是组合离线计算、在线计算、AB Test等服务的推荐引擎;左侧是用户需要完成的工作,包括早期数据的配置以及最终通过推荐API将结果集成到应用中;右侧是监控以及在线数据存储部分。在推荐引擎中,用户可以通过场景管理配置推荐方法(推荐场景是指客户的APP中使用推荐功能的模块名称),场景隶属于业务,使用到的数据就是业务中配置的数据;同时场景中包含一个或多个算法流程(每一个算法流程都代表一种推荐物品的逻辑,由多个算法拼装组成),支持AB Test;此外,推荐系统还提供可视化编辑算法、支持同一个推荐位同时测试多种推荐算法以及多种算法模版供客户选择。
系统之间的对接通过API方式实现,其中API又分为日志API、推荐API、算法任务API三类:
- 日志API用于接收业务采集的数据,以行为类数据为主;
- 推荐API提供推荐的物品列表,用于在业务系统中展示给消费者进行推荐;
- 算法任务API用于启动离线计算流程的算法任务、查看任务状态等。
总结
自始至终,阿里云从一开始就坚持将计算能力变成像水电煤一样的公共服务,提供给大众,而非单单而不是卖服务器给客户,这跟今日流行的Serverless 架构理念是一致的。
Serverless 理念在数加平台得到了很好的体现,数加平台今天已经可以提供很多业务场景化的计算服务,比如推荐引擎,规则引擎,以及各种人工智能的服务,用户可以实现进行各种数据采集、数据加工、BI商业智能、人工智能和数据创新等操作;此外,通过数加平台的数据市场相关API,开发者可以按需以服务的方式调用所需的第三方数据(如获取各种交通数据、气象数据、海洋数据、水利数据等),并结合自有数据实现大数据分析和应用,以得到数据价值的最大化。阿里云数加平台作为大数据Serverless的典范,将助力企业在DT时代更敏捷、更智能、更具洞察力。













