10月11日,Google AI Language 发布了论文BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding 提出的 BERT 模型在 11 个 NLP 任务上的表现刷新了记录,包括问答 Question Answering (SQuAD v1.1),推理 Natural Language Inference (MNLI) 。BERT的出现,彻底改变了预训练产生词向量和下游具体NLP任务的关系,提出龙骨级的训练词向量概念。
一、BERT 的功能
BERT 可以用于问答系统,情感分析,垃圾邮件过滤,命名实体识别,文档聚类等任务中,作为这些任务的基础设施即语言模型。
BERT 的代码也已经开源:https://github.com/google-research/bert
二、BERT 原理
BERT 的创新点在于它将双向 Transformer 用于语言模型,之前的模型是从左向右输入一个文本序列,或者将 left-to-right 和 right-to-left 的训练结合起来。
实验的结果表明,双向训练的语言模型对语境的理解会比单向的语言模型更深刻,
论文中介绍了一种新技术叫做 Masked LM(MLM),在这个技术出现之前是无法进行双向语言模型训练的。
BERT 利用了 Transformer 的 encoder 部分。
Transformer 是一种注意力机制,可以学习文本中单词之间的上下文关系的。
Transformer 的原型包括两个独立的机制,一个 encoder 负责接收文本作为输入,一个 decoder 负责预测任务的结果。
BERT 的目标是生成语言模型,所以只需要 encoder 机制。
Transformer 的 encoder 是一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取,
这个特征使得模型能够基于单词的两侧学习,相当于是一个双向的功能。
下图是 Transformer 的 encoder 部分,输入是一个 token 序列,先对其进行 embedding 称为向量,然后输入给神经网络,输出是大小为 H 的向量序列,每个向量对应着具有相同索引的 token。
当我们在训练语言模型时,有一个挑战就是要定义一个预测目标,很多模型在一个序列中预测下一个单词,“The child came home from ___” 双向的方法在这样的任务中是有限制的,为了克服这个问题,BERT 使用两个策略:
1. Masked LM (MLM)
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词。
这样就需要:
- 在 encoder 的输出上添加一个分类层
- 用嵌入矩阵乘以输出向量,将其转换为词汇的维度
- 用 softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
2. Next Sentence Prediction (NSP)
在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。
在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
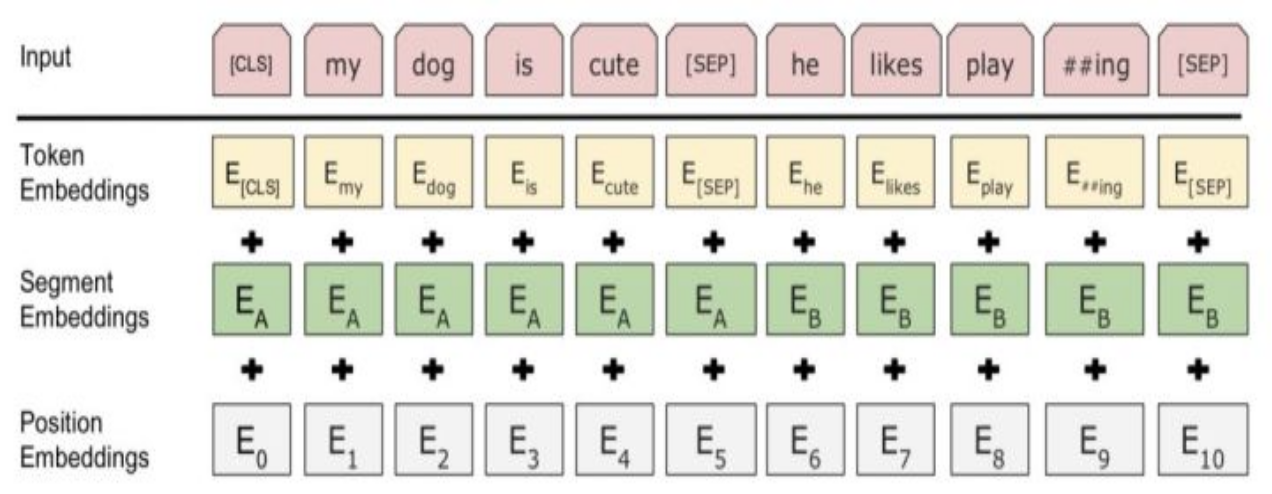
- 在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。
- 将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上。
- 给每个 token 添加一个位置 embedding,来表示它在序列中的位置。
为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
- 整个输入序列输入给 Transformer 模型
- 用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量
- 用 softmax 计算 IsNextSequence 的概率
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
三、如何使用 BERT?
BERT 可以用于各种NLP任务,只需在核心模型中添加一个层,例如:
- 在分类任务中,例如情感分析等,只需要在 Transformer 的输出之上加一个分类层
- 在问答任务(例如SQUAD v1.1)中,问答系统需要接收有关文本序列的 question,并且需要在序列中标记 answer。 可以使用 BERT 学习两个标记 answer 开始和结尾的向量来训练Q&A模型。
- 在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。 可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。
在 fine-tuning 中,大多数超参数可以保持与 BERT 相同,在论文中还给出了需要调整的超参数的具体指导(第3.5节)。
四、BERT细则
这里主要介绍BERT的三个亮点Masked LM、transformer、sentence-level。
4.1. Masked Language Model
原本叫cloze test,是完形填空的意思。
随机mask语料中15%的token,然后将masked token 位置输出的最终隐层向量送入softmax,来预测masked token。
这样输入一个句子,每次只预测句子中大概15%的词,所以BERT训练很慢。。。(但是google设备NB。。)

而对于盖住词的特殊标记,在下游NLP任务中不存在。因此,为了和后续任务保持一致,作者按一定的比例在需要预测的词位置上输入原词或者输入某个随机的词。如:my dog is hairy
- 有80%的概率用“[mask]”标记来替换——my dog is [MASK]
- 有10%的概率用随机采样的一个单词来替换——my dog is apple
- 有10%的概率不做替换——my dog is hairy
4.2. Transformer —— attention is all you need
Transformer模型是2018年5月提出的,可以替代传统RNN和CNN的一种新的架构,用来实现机器翻译,论文名称是attention is all you need。无论是RNN还是CNN,在处理NLP任务时都有缺陷。CNN是其先天的卷积操作不很适合序列化的文本,RNN是其没有并行化,很容易超出内存限制(比如50tokens长度的句子就会占据很大的内存)。
下面图是transformer模型一个结构,分成左边Nx框框的encoder和右边Nx框框的decoder,相较于RNN+attention常见的encoder-decoder之间的attention(上边的一个橙色框),还多出encoder和decoder内部的self-attention(下边的两个橙色框)。每个attention都有multi-head特征。最后,通过position encoding加入没考虑过的位置信息。下面从multi-head attention,self-attention, position encoding几个角度介绍。


4.2.1 multi-head attention:
将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
4.2.2 self-attention:
每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。比如上面右图这个句子,每个单词和同句其他单词之间都有一条边作为联系,边的颜色越深表明联系越强,而一般意义模糊的词语所连的边都比较深。比如:law,application,missing,opinion……
4.2.3 position encoding:
因为transformer既没有RNN的recurrence也没有CNN的convolution,但序列顺序信息很重要,比如你欠我100万明天要还和我欠你100万明天要还的含义截然不同。。。
transformer计算token的位置信息这里使用正弦波↓,类似模拟信号传播周期性变化。这样的循环函数可以一定程度上增加模型的泛化能力。
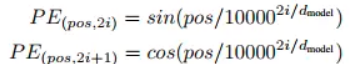
但BERT直接训练一个position embedding来保留位置信息,每个位置随机初始化一个向量,加入模型训练,最后就得到一个包含位置信息的embedding(简单粗暴。。),最后这个position embedding和word embedding的结合方式上,BERT选择直接拼接。
4.3. sentence-level representation
在很多任务中,仅仅靠encoding是不足以完成任务的(这个只是学到了一堆token级的特征),还需要捕捉一些句子级的模式,来完成SLI、QA、dialogue等需要句子表示、句间交互与匹配的任务。对此,BERT又引入了另一个极其重要却又极其轻量级的任务,来试图把这种模式也学习到。
4.3.1 句子级负采样
句子级别的连续性预测任务,即预测输入BERT的两端文本是否为连续的文本。训练的时候,输入模型的第二个片段会以50%的概率从全部文本中随机选取,剩下50%的概率选取第一个片段的后续的文本。 即首先给定的一个句子(相当于word2vec中给定context),它下一个句子即为正例(相当于word2vec中的正确词),随机采样一个句子作为负例(相当于word2vec中随机采样的词),然后在该sentence-level上来做二分类(即判断句子是当前句子的下一句还是噪声)。
4.3.2 句子级表示

BERT是一个句子级别的语言模型,不像ELMo模型在与下游具体NLP任务拼接时需要每层加上权重做全局池化,BERT可以直接获得一整个句子的唯一向量表示。它在每个input前面加一个特殊的记号[CLS],然后让Transformer对[CLS]进行深度encoding,由于Transformer是可以无视空间和距离的把全局信息encoding进每个位置的,而[CLS]的最高隐层作为句子/句对的表示直接跟softmax的输出层连接,因此其作为梯度反向传播路径上的“关卡”,可以学到整个input的上层特征。
4.3.3 segment embedding
对于句对来说,EA和EB分别代表左句子和右句子;对于句子来说,只有EA。这个EA和EB也是随模型训练出来的。
如下图所示,最终输入结果会变成下面3个embedding拼接的表示。