
前言
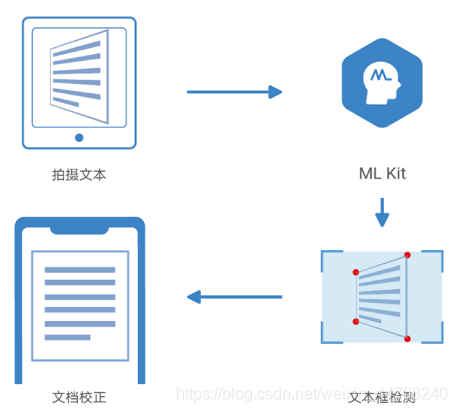
在之前的《超简单集成华为HMS ML Kit文本识别SDK,一键实现账单号自动录入》文章中,我们给大家介绍了华为HMS ML Kit文本识别技术如何通过拍照自动识别照片中的文本信息。那么有的小伙伴可能会问,如果拍照时不是正对着文本拍摄,拍出来的照片是歪斜的,那么还能准确识别文本吗?当然可以啦。HMS ML Kit文档校正技术可以自动识别文档位置,校正拍摄角度,并且支持用户自定义边界点位置,即使在倾斜角度也能够拍摄出文档的正面图像。
应用场景
文档校正技术在生活中有很多的应用场景。比如说在拍摄纸质文档时,相机处于倾斜的角度,导致阅读文档非常不方便。使用文档校正技术可以把文档调整到正对的视角,这样阅读起来就顺利多了。

再比如在记录卡证信息时,使用文档校正技术,不需要调整到正对卡证的视角,也可以拍摄出卡证的正面照片。

另外,在行程中因为身处于倾斜位置,道路旁的路牌难以准确识别,这时可以通过文档校正技术拍摄到路牌正面图片。

怎么样,是不是很方便呢?那我们接下来详细给大家介绍安卓如何快速集成文档校正技术。
开发实战
详细的准备步骤可以参考华为开发者联盟: https://developer.huawei.com/consumer/cn/doc/development/HMS-Guides/ml-process-4 这里列举关键的开发步骤。
1.1 项目级gradle里配置Maven仓地址
buildscript {
repositories {
...
maven {url 'https://developer.huawei.com/repo/'}
}
}
dependencies {
...
classpath 'com.huawei.agconnect:agcp:1.3.1.300'
}
allprojects {
repositories {
...
maven {url 'https://developer.huawei.com/repo/'}
}
}
1.2 应用级gradle里配置SDK依赖
dependencies{
// 引入基础SDK
implementation 'com.huawei.hms:ml-computer-vision-documentskew:2.0.2.300'
// 引入文档检测/校正模型包
implementation 'com.huawei.hms:ml-computer-vision-documentskew-model:2.0.2.300'
}
1.3 在文件头添加配置
apply plugin: 'com.huawei.agconnect'
apply plugin: 'com.android.application'
1.4 添加如下语句到AndroidManifest.xml文件中,自动更新机器学习模型到设备
<meta-data
android:name="com.huawei.hms.ml.DEPENDENCY"
android:value= "dsc"/>
1.5 申请摄像机权限和读本地图片权限
<uses-permission android:name="android.permission.CAMERA" />
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE" />
2. 代码开发
2.1 创建文本框检测/校正分析器
MLDocumentSkewCorrectionAnalyzerSetting setting = new MLDocumentSkewCorrectionAnalyzerSetting.Factory().create();
MLDocumentSkewCorrectionAnalyzer analyzer = MLDocumentSkewCorrectionAnalyzerFactory.getInstance().getDocumentSkewCorrectionAnalyzer(setting);
2.2 通过android.graphics.Bitmap创建MLFrame对象用于分析器检测图片,支持的图片格式包括:jpg/jpeg/png,建议图片尺寸不小于320_320像素,不大于1920_1920像素。
MLFrame frame = MLFrame.fromBitmap(bitmap);
2.3 调用asyncDocumentSkewDetect异步方法或analyseFrame同步方法进行文本框的检测。当返回码是MLDocumentSkewCorrectionConstant.SUCCESS时,将会返回文本框的四个顶点的坐标值,该坐标值是相对于传入图像的坐标,若与设备坐标不一致,需调用者进行转换;否则,返回的数据没有意义。
// asyncDocumentSkewDetect异步调用。
Task<MLDocumentSkewDetectResult> detectTask = analyzer.asyncDocumentSkewDetect(mlFrame);
detectTask.addOnSuccessListener(new OnSuccessListener<MLDocumentSkewDetectResult>() {
@Override
public void onSuccess(MLDocumentSkewDetectResult detectResult) {
// 检测成功。
}
}).addOnFailureListener(new OnFailureListener() {
@Override
public void onFailure(Exception e) {
// 检测失败。
}
})
// analyseFrame同步调用。
SparseArray<MLDocumentSkewDetectResult> detect = analyzer.analyseFrame(mlFrame);
if (detect != null && detect.get(0).getResultCode() == MLDocumentSkewCorrectionConstant.SUCCESS) {
// 检测成功。
} else {
// 检测失败。
}
2.4 检测成功后,分别获取文本框四个顶点的坐标数据,然后以左上角为起点,按顺时针方向,分别把左上角、右上角、右下角、左下角加入到列表(List)中,最后构建MLDocumentSkewCorrectionCoordinateInput对象。
2.4.1 如果使用analyseFrame同步调用,先获取到检测结果,如下所示(使用asyncDocumentSkewDetect异步调用可忽略此步骤直接进行步骤2.4.2):
MLDocumentSkewDetectResult detectResult = detect.get(0);
2.4.2 获取文本框四个顶点的坐标数据并构建MLDocumentSkewCorrectionCoordinateInput对象:
Point leftTop = detectResult.getLeftTopPosition();
Point rightTop = detectResult.getRightTopPosition();
Point leftBottom = detectResult.getLeftBottomPosition();
Point rightBottom = detectResult.getRightBottomPosition();
List<Point> coordinates = new ArrayList<>();
coordinates.add(leftTop);
coordinates.add(rightTop);
coordinates.add(rightBottom);
coordinates.add(leftBottom);
MLDocumentSkewCorrectionCoordinateInput coordinateData = new MLDocumentSkewCorrectionCoordinateInput(coordinates);
2.5 调用asyncDocumentSkewCorrect异步方法或syncDocumentSkewCorrect同步方法进行文本框的校正。
// asyncDocumentSkewCorrect异步调用。
Task<MLDocumentSkewCorrectionResult> correctionTask = analyzer.asyncDocumentSkewCorrect(mlFrame, coordinateData);
correctionTask.addOnSuccessListener(new OnSuccessListener<MLDocumentSkewCorrectionResult>() {
@Override
public void onSuccess(MLDocumentSkewCorrectionResult refineResult) {
// 检测成功。
}
}).addOnFailureListener(new OnFailureListener() {
@Override
public void onFailure(Exception e) {
// 检测失败。
}
});
// syncDocumentSkewCorrect同步调用。
SparseArray<MLDocumentSkewCorrectionResult> correct= analyzer.syncDocumentSkewCorrect(mlFrame, coordinateData);
if (correct != null && correct.get(0).getResultCode() == MLDocumentSkewCorrectionConstant.SUCCESS) {
// 校正成功。
} else {
// 校正失败。
}
2.6 检测完成,停止分析器,释放检测资源。
if (analyzer != null) {
analyzer.stop();
}
Demo效果
下面这个demo展示了在倾斜角度扫描文档,文档校正技术可以把文档调整到正对视角。效果是不是很棒?
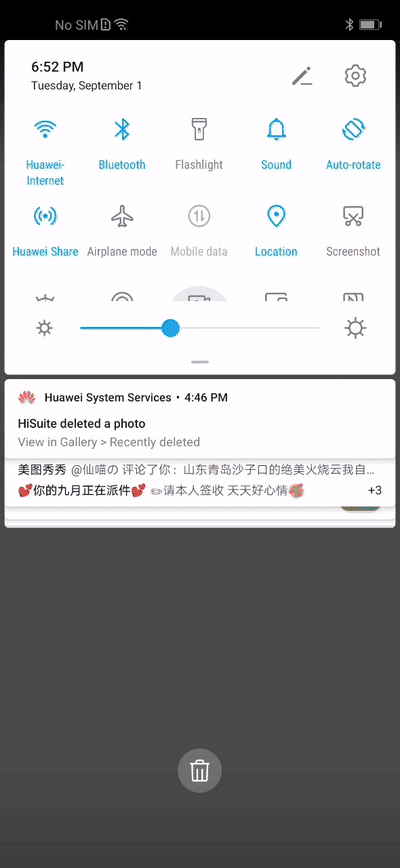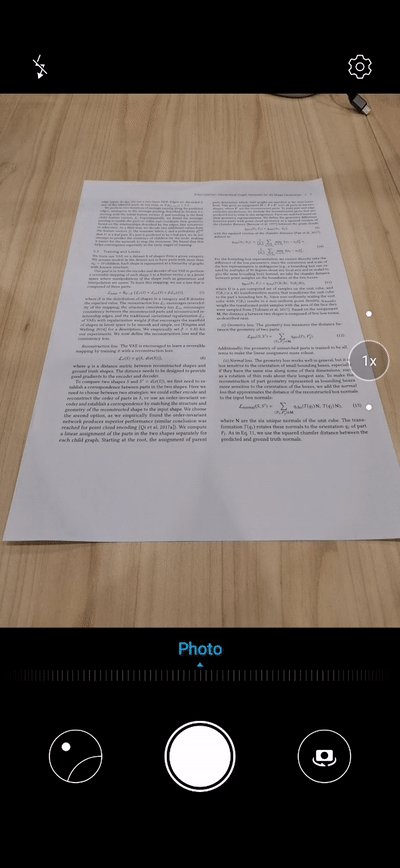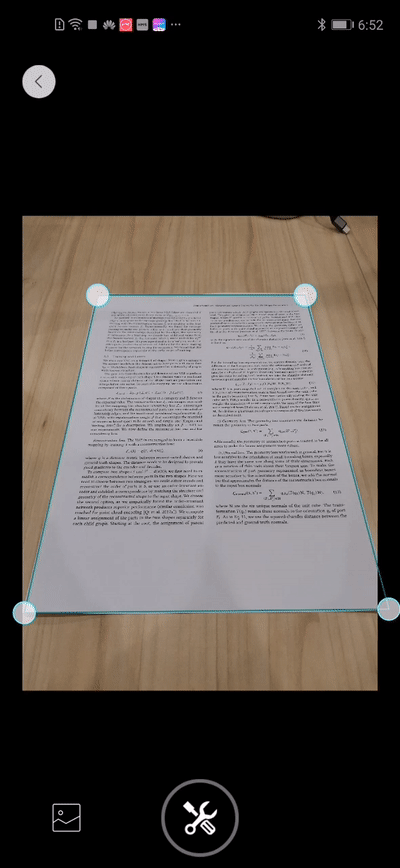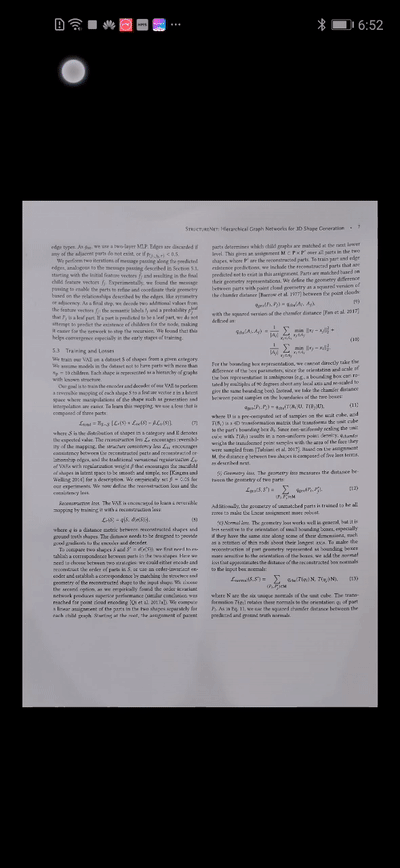
文档校正技术还可以辅助文档识别技术,将倾斜的文档调整到正面视角,快速实现从纸质文件到电子文件的转化,大幅度提升信息的录入效率。
Github源码
更详细的开发指南参考华为开发者联盟官网
https://developer.huawei.com/consumer/cn/hms/huawei-mlkit
欲了解更多详情,请参阅: 华为开发者联盟官网:https://developer.huawei.com/consumer/cn/hms 获取开发指导文档:https://developer.huawei.com/consumer/cn/doc/development 参与开发者讨论请到Reddit社区:https://www.reddit.com/r/HMSCore/ 下载demo和示例代码请到Github:https://github.com/HMS-Core 解决集成问题请到Stack Overflow:https://stackoverflow.com/questions/tagged/huawei-mobile-services?tab=Newest
文章来源:https://developer.huawei.com/consumer/cn/forum/topicview?tid=0202344452930050418&fid=18
作者:留下落叶











