
MySQL的sql_mode合理设置
sql_mode是个很容易被忽视的变量,默认值是空值,在这种设置下是可以允许一些非法操作的,比如允许一些非法数据的插入。在生产环境必须将这个值设置为严格模式,所以开发、测试环境的数据库也必须要设置,这样在开发测试阶段就可以发现问题。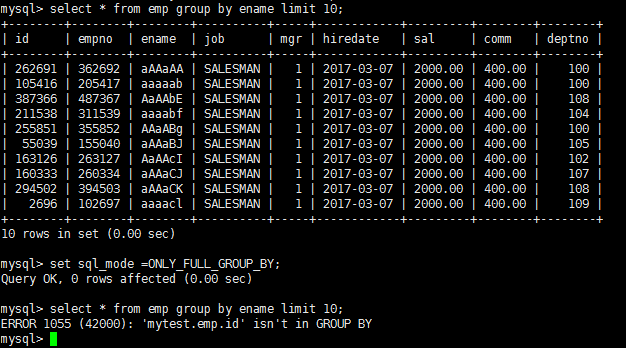
show variables like 'sql_mode';
sql_mode常用值如下:
set sql_mode='ONLY_FULL_GROUP_BY';
ONLY_FULL_GROUP_BY:
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中
NO_AUTO_VALUE_ON_ZERO:
该值影响自增长列的插入。默认设置下,插入0或NULL代表生成下一个自增长值。如果用户 希望插入的值为0,而该列又是自增长的,那么这个选项就有用了。
STRICT_TRANS_TABLES:
在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做限制
NO_ZERO_IN_DATE:
在严格模式下,不允许日期和月份为零
NO_ZERO_DATE:
设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告。
ERROR_FOR_DIVISION_BY_ZERO:
在INSERT或UPDATE过程中,如果数据被零除,则产生错误而非警告。如 果未给出该模式,那么数据被零除时MySQL返回NULL
NO_AUTO_CREATE_USER:
禁止GRANT创建密码为空的用户
NO_ENGINE_SUBSTITUTION:
如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常
PIPES_AS_CONCAT:
将"||"视为字符串的连接操作符而非或运算符,这和Oracle数据库是一样的,也和字符串的拼接函数Concat相类似
ANSI_QUOTES:
启用ANSI_QUOTES后,不能用双引号来引用字符串,因为它被解释为识别符
ORACLE:
设置等同:PIPES_AS_CONCAT, ANSI_QUOTES, IGNORE_SPACE, NO_KEY_OPTIONS, NO_TABLE_OPTIONS, NO_FIELD_OPTIONS, NO_AUTO_CREATE_USER.
概述
和其它数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上,
插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。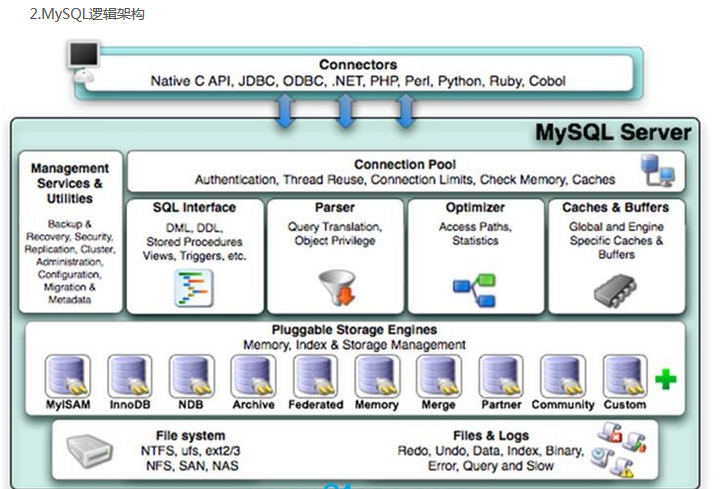
1.连接层
最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
2.服务层
2.1 Management Serveices & Utilities: 系统管理和控制工具
2.2 SQL Interface: SQL接口
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
2.3 Parser: 解析器
SQL命令传递到解析器的时候会被解析器验证和解析。
2.4 Optimizer: 查询优化器。
SQL语句在查询之前会使用查询优化器对查询进行优化。
用一个例子就可以理解: select uid,name from user where gender= 1;
优化器来决定先投影还是先过滤。
2.5 Cache和Buffer: 查询缓存。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
3.引擎层
存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。后面介绍MyISAM和InnoDB
4.存储层
数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
mysql执行顺序
查询流程图:
首先,mysql的查询流程大致是:
mysql客户端通过协议与mysql服务器建连接,发送查询语句,先检查查询缓存,如果命中,直接返回结果,否则进行语句解析,也就是说,在解析查询之前,服务器会先访问查询缓存(query cache)——它存储SELECT语句以及相应的查询结果集。如果某个查询结果已经位于缓存中,服务器就不会再对查询进行解析、优化、以及执行。它仅仅将缓存中的结果返回给用户即可,这将大大提高系统的性能。
语法解析器和预处理:首先mysql通过关键字将SQL语句进行解析,并生成一颗对应的“解析树”。mysql解析器将使用mysql语法规则验证和解析查询;预处理器则根据一些mysql规则进一步检查解析数是否合法。
查询优化器当解析树被认为是合法的了,并且由优化器将其转化成执行计划。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。。
然后,mysql默认使用的BTREE索引,并且一个大致方向是:无论怎么折腾sql,至少在目前来说,mysql最多只用到表中的一个索引。
sql执行顺序
手写
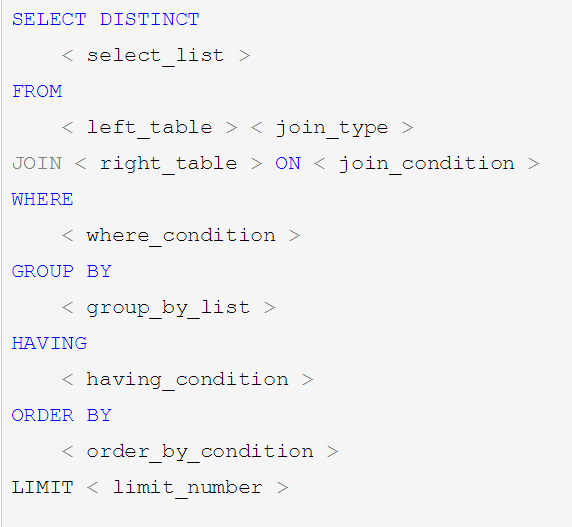
mysql读取后
随着Mysql版本的更新换代,其优化器也在不断的升级,优化器会分析不同执行顺序产生的性能消耗不同而动态调整执行顺序。
下面是经常出现的查询顺序:













