
此基础知识仅为个人学习记录,如有错误或遗漏之处,还请各位同行给个提示。
概述
TFLite主要含有如下内容:
(1)TFLite提供一系列针对移动平台的核心算子,包括量化和浮点运算。另外,TFLite也支持在模型中使用自定义算子。
(2)TFLite基于FlatBuffers定义了一种新的模型文件格式。FlatBuffers类似于protocol buffers, FlatBuffers在访问数据之前不需要进行解析/解包步骤,通常与每个对象的内存分配相结合。而且,FlatBuffers的代码占用空间比protocol buffers小一个量级。
(3)TFLite拥有一个新的优化解释器,其主要目标是保持应用程序的精简和快速。 解释器使用静态图形排序和自定义(动态性较小)内存分配器来确保最小的负载、初始化和执行延迟。
(4)TFLite提供了一个利用硬件加速的接口,通过安卓端的神经网络接口(NNAPI)实现,可在Android 8.1(API级别27)及更高版本上使用。
TFLite提供的支持:
(1)一组核心ops,包括量化和浮点运算,其中许多已经针对移动平台进行了调整。 这些可用于创建和运行自定义模型。开发人员还可以编写自己的自定义ops,并在模型中使用。
(2)一种新的基于FlatBuffers的模型文件格式。
(3)MobileNet模型的量化版本,其运行速度比CPU上的非量化(浮点)版本快。
(4)更小的模型:当使用所有支持的运算符时,TFLite小于300KB,当仅使用支持InceptionV3和Mobilenet所需的运算符时,TFLite小于200KB。
(5)支持Java和C++接口
(6)提供一些pre-trained模型,例如mobileNets、Inception。
TensorFlow Lite的架构设计:
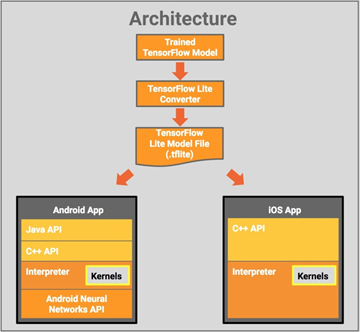
一、开发指南
在移动应用程序中使用TensorFlow Lite模型,分为三个以下步骤:
(1)选择预先训练或自定义模型;
这一步骤有三种选择模型的方式:a)使用pre-trained模型,例如mobileNets、Inception;b)在新的数据集上重新训练pre-trained模型;c)使用tf训练自定义的模型
(2)将模型转换为TensorFLow Lite格式;
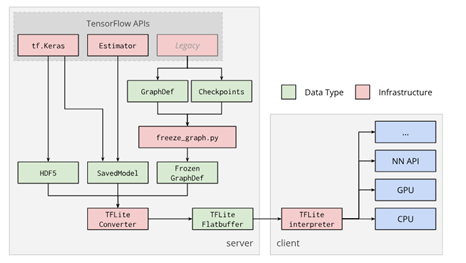
TFLite Converter的支持输入:SavedModels,frozen graphs(由freeze_graph.py生成的模型)和tf.keras HDF5模型。输出文件为TFLite模型文件,部署到客户端(包括移动端或嵌入式设备)后,通过TFLite interpreter提供的接口使用TFLite模型文件。**(具体转换过程见博文:TFLite模型转换过程)**
(3)最后将模型集成到应用程序中。
Android端:由于Android应用程序是用Java编写的,而核心TensorFlow库是用C ++编写的,因此需要提供一个JNI库作为接口。(在Android端如何编写JNI库,以及将C++程序成封装.so文件,包括JNI基础、java与C++如何通过JNI来建立连接、.so封装的过程、makelist****编写,具体见博文:Android studio 编写JNI库,封装成.so文件)
二 、TFLite接口
(1)C++接口
模型加载到FlatBufferModel对象中,然后由Interpreter类来执行。FlatBufferModel需要在Interpreter类的整个生命周期内保持有效,单个FlatBufferModel可以由多个Interpreter同时使用。具体而言,FlatBufferModel对象必须在使用它的任何Interpreter对象之前创建,并且必须保持至所有FlatBufferModel对象被销毁。

a)数据对齐
TFLite数据通常与16字节边界对齐。建议TFLite的所有输入数据都以这种方式对齐。
b)加载模型
FlatBufferModel类封装了模型加载,根据模型的存储位置以几种略有不同的方式构建:
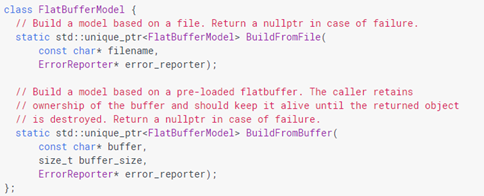
请注意,如果TFLite检测到Android NNAPI的存在,它将自动尝试使用共享内存来存储FlatBuffer模型。
c)运行模型
几个简单的步骤:
- 基于现有的FlatBufferModel构建解释器(Interpreter)
- 如果不需要预定义的大小,可以选择调整输入tensor的大小。
- 设置输入tensor值
- 调用inference类
- 读取输出张量值
Interpreter的公共接口,需要注意如下几点:
- 为了避免字符串比较,tensor由整数表示;
- 不能从并发线程中访问解释器;
- 在调整张量大小后,立即调用AllocateTensors()来分配输入和输出tensor的内存。
d)自定义算子
所有TFLite运算符(自定义和内置运算符)都使用纯C接口定义,该接口由四个函数组成:

有关TfLiteContext和TfLiteNode的详细信息,请参阅tensorflow\lite\c\c_api_internal.h,该文件定义了在tflite中实现操作的C API。
如下所示的全局注册函数(如同tensorflow\lite\kernels\下的内置算子)中自定义上述四个函数,可以与内置操作完全相同的方式实现自定义操作:
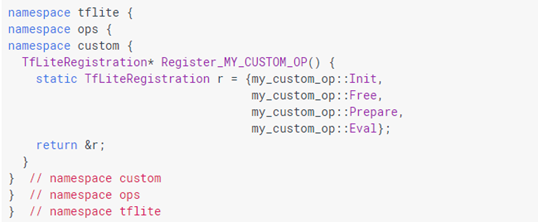
请注意,注册不是自动的,应该在某处使用BuiltinOpResolver显式调用Register_MY_CUSTOM_OP。
e)自定义内核库
Interpreter将加载一个内核库(kernel),这些内核将用于执行模型中的每个操作符。Interpreter使用OpResolver将operator codes和name转换为实际代码:
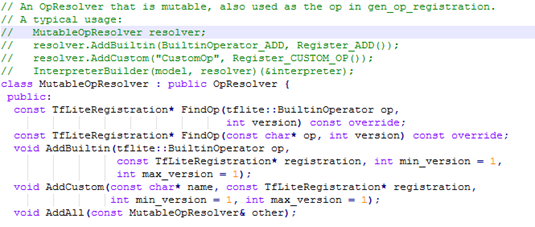
通常的使用方法(tensorflow\lite\mutable_op_resolver.h):
MutableOpResolver resolver;
resolver.AddBuiltin(BuiltinOperator_ADD, Register_ADD()); //添加内置算子
resolver.AddCustom("CustomOp", Register_CUSTOM_OP()); //注册自定义算子
InterpreterBuilder(model, resolver)(&interpreter);
(2)Java接口
TensorFlow Lite的Java API支持设备上inference,并作为Android Studio库提供,允许加载模型,提供输入和检索输出。
加载模型:使用Interpreter.java类进行TFLite模型推断(model inference)。使用模型文件初始化Interpreter类,Interpreter(@NonNull File modelFile, Options options)。
运行模型:
a)支持的数据类型
要使用TFLite,输入和输出tensor的数据类型必须是以下基本类型之一:float、int、long、byte。如果使用其他数据类型(包括类似Integer和Float的封装类型),则会抛出IllegalArgumentException。
b)输入值
每个输入应该是受支持的基本类型的数组或多维数组,或者是适当大小的原始ByteBuffer。 如果输入是数组或多维数组,则在模型推断时,模型相关的输入tensors将被隐式调整为数组的维度。如果输入是ByteBuffer,则调用者应首先在运行推断(inference)之前,手动调整输入张量(通过Interpreter.resizeInput())。
ByteBuffer是缓冲区类,使用它可以进行高效的IO操作,允许解释器避免不必要的copy。 如果ByteBuffer是直接字节缓冲区,则其顺序必须为ByteOrder.nativeOrder()。 ByteBuffer用于模型推断后,必须保持不变,直到模型推断完成。
c)输出
输出应该是受支持的基本类型的数组或多维数组,或者是适当大小的ByteBuffer。 请注意,某些型号具有动态输出,其中输出张量的形状可根据输入而变化。 使用现有的Java推理API没有直接的方法来处理这个问题,但未来计划的扩展将使这成为可能。
d)运行模型推断
一种输入和一种输出:
run(@NonNull Object input, @NonNull Object output)
多种输入或者多种输出:
runForMultipleInputsOutputs(Object[] inputs, @NonNull Map<Integer, Object> outputs)
e)释放资源
为避免内存泄漏,必须在使用后释放资源:interpreter.close();
三、如何使用自定义算子
通过一个例子来讨论这个问题。 假设我们正在使用Sin运算符,并且我们正在为函数y = sin(x + offset)构建一个非常简单的模型,其中offset是可训练的。
训练TensorFlow模型的代码将类似于:

如果使用带有--allow_custom_ops参数的TensorFlow Lite优化转换器将此模型转换为Tensorflow Lite格式,并使用默认解释器运行它,则解释器将引发以下错误消息:

TFLite中使用op所需要做的就是定义两个函数(Prepare和Eval),并构造一个TfLiteRegistration。如下示例(也可以根据kernel文件中的内置算子就行仿写):
 初始化OpResolver时,将自定义op添加到解析器中,这将使用Tensorflow Lite注册操作符,以便TensorFlow Lite可以使用新的实现。
初始化OpResolver时,将自定义op添加到解析器中,这将使用Tensorflow Lite注册操作符,以便TensorFlow Lite可以使用新的实现。

编写自定义运算符的最佳实践:
(a)谨慎地优化内存分配和取消分配。相比于invake(),在Prepare()中分配内存更有效,并在循环之前而不是在每次迭代中分配内存。使用临时tensor数据而不是自己进行mallocing(参见第2项)。尽可能使用指针/引用而不是复制。
(b)如果数据结构在整个操作期间一直存在,我们建议使用临时张量预分配内存。可能需要使用OpData结构来引用其他函数中的张量索引。请参阅kernel for convolution。
(c)倾向于使用静态固定大小的数组(或者在Resize()中预先分配的std :: vector),而不是每次执行迭代时都使用动态分配std :: vector。
(d)避免实例化尚不存在的标准库容器模板,它们会影响二进制文件大小。例如,如果操作中需要std :: map而其他内核中不存在,则使用带有直接索引映射的std :: vector就可以,这样可以保持二进制大小较小。
(e)检查指向malloc返回的内存的指针。如果此指针为nullptr,则不应使用该指针执行任何操作。如果函数中有malloc()并且出现错误,在退出之前释放内存。
(f)使用TF_LITE_ENSURE(context,condition)检查特定条件。
特殊TF Graph属性**:**
当Toco将TF graph转换为TFLite格式时,生成的graph可能不可执行。
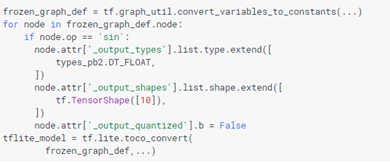
因此,在转换之前,可以将有关自定义算子输出的附加信息添加到TF graph中。 支持以下属性:
_output_quantized一个布尔属性,如果操作输出被量化,则为true
_output_types 输出张量的类型列表
_output_shapes 输出张量的形状列表
如何设置属性的示例:
四、TFLite 算子更新
由于TensorFlow Lite操作集小于TensorFlow,因此并非每个模型都可以转换。 即使对于受支持的操作,出于性能原因,有时也会出现非常具体的使用模式。在未来的TensorFlow Lite版本中将扩展支持的操作集。
本文档描述了TensorFlow Lite的op算子更新框架。 Op算子的更新使得开发人员能够将新功能和参数添加到现有操作中。 此外,它保证以下内容:
- 向后兼容性:新的TensorFlow Lite实现应该处理旧的模型文件。
- 向前兼容性:只要没有使用新功能,旧TensorFlow Lite实现应该处理由新版TOCO生成的新模型文件。
- 正向兼容性检测:如果旧的TensorFlow Lite实现不支持的新版本操作的新模型,则应报告错误。
示例:将dilation添加到卷积操作
本文档的其余部分通过展示如何将dilation参数添加到卷积操作来解释TFLite中的如何进行算子更新。需要注意两点:
- 将添加2个新的整数参数:dilation_width_factor和dilation_height_factor。
- 不支持扩张的旧卷积核相当于将扩张因子设置为1。
(1)更改FlatBuffer架构
将新参数添加到op中,需要更改lite/schema/schema.fbs中的options表。
例如,卷积选项表如下所示:

添加新参数时,需要添加注释,指示哪个版本支持哪些参数。
添加新参数后,表格将如下所示:

(2)更改C结构和内核实现
在TensorFlow Lite中,内核实现与FlatBuffer定义分离。 内核从lite/builtin_op_data.h中定义的C结构中读取参数。
原始卷积参数如下:

与FlatBuffer架构一样,需要添加注释,指示从哪个版本开始支持哪些参数。 结果如下:

最后更改内核,实现C结构中新添加的参数。 这里省略了细节。
(3)更改FlatBuffer阅读代码
文件lite/model.cc中读取FlatBuffer并生成C结构的逻辑。
更新文件以处理新参数,如下所示:
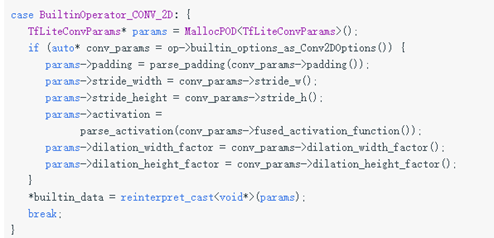
这里不需要检查op算子的版本。 因为,当新的方法读取缺少扩张因子的旧模型文件时,该方法将使用1作为默认值,保证新内核将与旧内核一致地工作。
(4)更改内核注册
MutableOpResolver(在lite / op_resolver.h中定义)提供了一些注册op内核的函数。 默认情况下,最小和最大版本为1:

内置的ops在lite / kernels / register.cc中注册。在这个例子中,实现了一个新的op内核,可以处理Conv2D版本1和2,所以我们需要将:

改为

(5)更改TOCO TFLite导出
最后一步是让TOCO填充执行操作所需的最低版本。 在这个例子中,它意味着:
- 填充 version=1 when dilation factors are all 1.
- 填充 version=2 otherwise.
为此,需要在lite/toco/tflite/operator.cc中覆盖运算符类的GetVersion函数。
对于只有一个版本的操作,GetVersion函数定义为:

支持多个版本时,请检查参数并确定op的版本,如以下示例所示:

(6)授权
TensorFlow Lite提供了一个授权API,可以将op授权给硬件后端。 在Delegate的Prepare函数中,检查授权代码中是否支持每个节点的版本。

五、TFLite 和TF兼容性指南
由于TensorFlow Lite操作集小于TensorFlow,因此并非每个模型都可以转换。 即使对于受支持的操作,出于性能原因,有时也会出现非常具体的使用模式。在未来的TensorFlow Lite版本中将扩展支持的操作集。
了解如何构建可与TensorFlow Lite一起使用的TensorFlow模型的最佳方法,是仔细考虑如何转换和优化操作,以及此过程施加的限制。
本文来源于tensorflow lite官网 https://tensorflow.google.cn/lite/overview












