


在分布式系统中,由于节点服务会部署多台,一旦出现线上问题需要通过日志分析定位问题就需要登录服务器一台一台进行日志检索,非常不便利,这时候就需要用到EFK日志收集工具。
在应用服务端部署Filebeat,将我们打印到日志文件中的日志发送到Logstash中,在经过Logstash的解析格式化后将日志发送到ElasticSearch中,最后通过Kibana展现出来。EFK基础版的架构如下: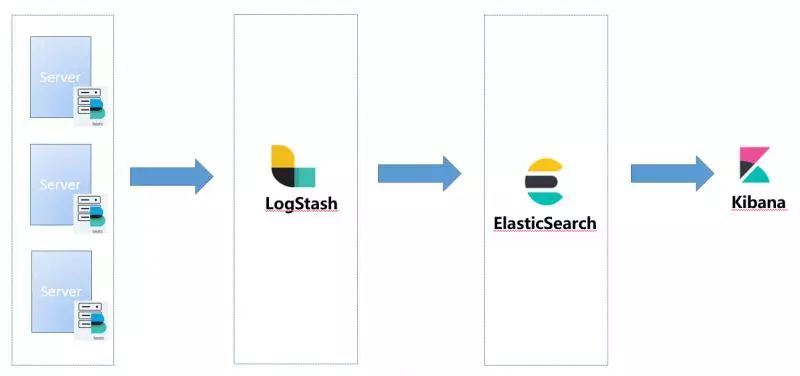
本文主要是使用docker和docker-Compose部署EFK的基础环境,选择7.5.1作为EFK组件版本。
当然了如果大家对docker,docker-compose不是很熟悉的话可以翻看我之前为大家准备的两篇文章:

实在不想使用docker部署的话也可以下载对应的安装包然后手动部署,配置方式基本一样。
安装配置
elasticsearch
安装elasticsearch之前先配置如下的系统变量
修改
/etc/sysctl.conf,在最后追加如下配置vm.max_map_count = 655360修改
/etc/security/limits.conf,增加如下配置soft memlock unlimited* hard memlock unlimited* hard nofile 65536* soft nofile 65536
修改
/etc/security/limits.d/20-nproc.conf,增加如下配置soft nproc 4096root soft nproc unlimited
启动elasticsearch临时容器
docker run --rm --name es -p9200:9200 -p9300:9300 -e discovery.type=single-node elasticsearch:7.5.1导出elasticsearch配置文件
docker cp fbce586c8a56:/usr/share/elasticsearch/config/elasticsearch.yml /app/elk/elasticsearch/conf/elasticsearch.yml修改es配置文件
cluster.name: "elk-cluster"network.host: 0.0.0.0bootstrap.memory_lock: truediscovery.type: single-node
建立es的日志文件夹和数据文件夹,并对文件夹授权
mkdir -p /app/elk/elasticsearch/logsmkdir -p /app/elk/elasticsearch/datachmod -R 777 /app/elk/elasticsearch/logschmod -R 777 /app/elk/elasticsearch/data
停止临时容器
docker stop fbce586c8a56
logstash
启动临时容器
docker run --rm --name logstash -p5044:5044 -p9600:9600 logstash:7.5.1导出docker的配置文件
docker cp 5adb0971bb0f:/usr/share/logstash/config /app/elk/logstash建立logstash数据文件夹,并对其授权
mkdir -p /app/elk/logstash/datachmod -R 777 /app/elk/logstash/data
复制logstash启动文件,并对其修改
cd /app/elk/logstash/configcp logstash-sample.conf logstash.conf
修改logstash.conf,配置output
# Sample Logstash configuration for creating a simple# Beats -> Logstash -> Elasticsearch pipeline.input { beats { port => 5044 }}output { elasticsearch { hosts => ["http://172.31.0.207:9200"] index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" #user => "elastic" #password => "changeme" }}
暂时修改一下ES的访问路径即可。
- 停止临时容器
docker stop 5adb0971bb0f
kibana
启动临时容器
docker run --rm --name kibana -p5601:5601 kibana:7.5.1导出kibana配置文件
docker cp f21f0f9e0259:/usr/share/kibana/config/kibana.yml /app/elk/kibana/conf/kibana.yml修改kibana配置
server.name: kibanaserver.host: "0"elasticsearch.hosts: [ "http://172.31.0.207:9200" ]xpack.monitoring.ui.container.elasticsearch.enabled: truei18n.locale: zh-CN
设置i18n.locale: zh-CN属性后会对kibana进行汉化,这样便于操作,主要还是我英语不太好~
- 停止临时容器
docker stop f21f0f9e0259
docker-compose
经过上面的准备,我们可以编写docker-compose文件,方便我们对容器进行编排,一键启动。有了之前的基础,我们很容易编写出对应的yml文件,编写后的内容如下:
version: "3"services: elasticsearch: image: docker.io/elasticsearch:7.5.1 container_name: elasticsearch environment: - "ES_JAVA_OPTS=-Xms4096m -Xmx4096m -Xmn1300m" volumes: - /app/elk/elasticsearch/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml - /app/elk/elasticsearch/data:/usr/share/elasticsearch/data:rw - /app/elk/elasticsearch/logs:/usr/share/elasticsearch/logs:rw ports: - "9200:9200" - "9300:9300" restart: always kibana: image: docker.io/kibana:7.5.1 container_name: kibana volumes: - /app/elk/kibana/conf/kibana.yml:/usr/share/kibana/config/kibana.yml ports: - "5601:5601" depends_on: - elasticsearch restart: always logstash: image: logstash:7.5.1 container_name: logstash command: logstash -f /usr/share/logstash/config/logstash.conf volumes: - /app/elk/logstash/config:/usr/share/logstash/config - /app/elk/logstash/data:/usr/share/logstash/data ports: - "9600:9600" - "5044:5044" depends_on: - elasticsearch restart: always
将docker-compose文件上传至服务器,启动docker服务docker-compose -f elk.yml up -d
启动完成后访问kibana地址http://172.31.0.207:5601/验证是否正常访问
安全认证
我们刚刚部署的elk环境是不需要密码就可以登录kibana的,这样谁都可以访问而且可以更改数据。所以我们需要给kibana加个密码,必须要登录才可以进行操作。
主要是利用elasticsearch自带的xpack作为权限验证功能。操作步骤如下:
修改es外部配置文件
/app/elk/elasticsearch/conf/elasticsearch.yml,开启权限验证xpack.security.enabled: true
重启
elasticsearch服务docker-compose -f elk.yml restart elasticsearch进入es容器,为内置账号设置密码
docker exec -it elasticsearch /bin/bashcd /usr/share/elasticsearch/bin./elasticsearch-setup-passwords interactive
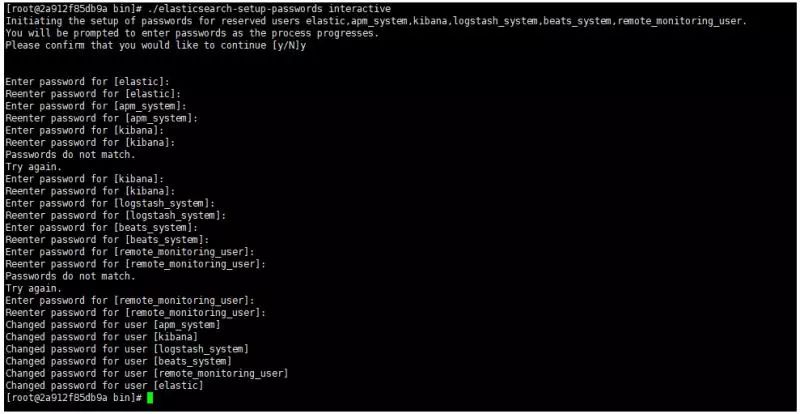
file
修改kibana配置文件
/app/elk/kibana/conf/kibana.ymlelasticsearch.username: "elastic"elasticsearch.password: "xxxxxx"
重启kibana
docker-compose -f elk.yml restart kibana重新访问kibana,并使用上面设置的elastic账号进行登录
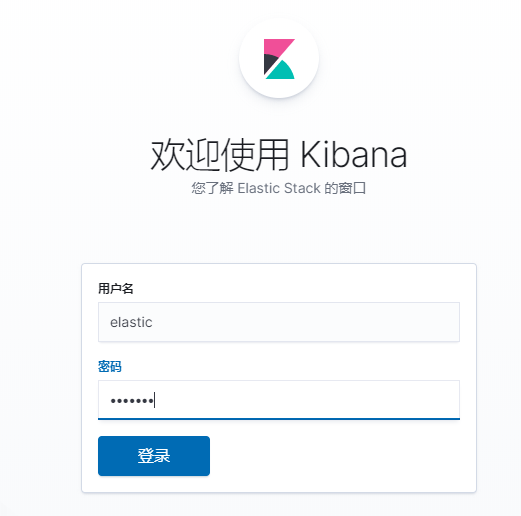
至此我们顺利给EFK加上了安全认证,可以放心在生产环境部署使用了!
好了,各位朋友们,本期的内容到此就全部结束啦,下一期我们会将业务系统的日志接入EFK并对日志进行解析格式化,欢迎持续关注。
如果觉得这篇文章对你有所帮助的话请扫描下面二维码加个关注。"转发" 加 "在看",养成好习惯!咱们下期再见!


本文分享自微信公众号 - JAVA日知录(javadaily)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












