
根据阿里交易型业务的特点,以及在双十一这样业内罕有的需求推动下,我们在官方的MySQL基础上增加了非常多实用的功能、性能补丁。而在使用MySQL的过程中,数据一致性是绕不开的话题之一。本文主要从阿里巴巴“去IOE”的后时代讲起,向大家简单介绍下我们过去几年在MySQL数据一致性上的努力和实践,以及目前的解决方案。
一.MySQL单机的数据一致性
MySQL作为一个可插拔的数据库系统,支持插件式的存储引擎,在设计上分为Server层和Storage Engine层。
在Server层,MySQL以events的形式记录数据库各种操作的Binlog二进制日志,其基本核心作用有:复制和备份。除此之外,我们结合多样化的业务场景需求,基于Binlog的特性构建了强大的MySQL生态,如:DTS、单元化、异构系统之间实时同步等等,Binlog早已成为MySQL生态中不可缺少的模块。而在Storage Engine层,InnoDB作为比较通用的存储引擎,其在高可用和高性能两方面作了较好的平衡,早已经成为使用MySQL的首选(PS:官方从MySQL 5.5.5开始,将InnoDB作为了MySQL的默认存储引擎 )。和大多数关系型数据库一样,InnoDB采用WAL技术,即InnoDB Redo Log记录了对数据文件的物理更改,并保证总是日志先行,在持久化数据文件前,保证之前的redo日志已经写到磁盘。Binlog和InnoDB Redo Log是否落盘将直接影响实例在异常宕机后数据能恢复到什么程度。InnoDB提供了相应的参数来控制事务提交时,写日志的方式和策略,例如:
innodb_flush_method:控制innodb数据文件、日志文件的打开和刷写的方式,建议取值:fsync、O_DIRECT。 innodb_flush_log_at_trx_commit:控制每次事务提交时,重做日志的写盘和落盘策略,可取值:0,1,2。 当innodb_flush_log_at_trx_commit=1时,每次事务提交,日志写到InnoDB Log Buffer后,会等待Log Buffer中的日志写到Innodb日志文件并刷新到磁盘上才返回成功。 sync_binlog:控制每次事务提交时,Binlog日志多久刷新到磁盘上,可取值:0或者n(N为正整数)。 不同取值会影响MySQL的性能和异常crash后数据能恢复的程度。当sync_binlog=1时,MySQL每次事务提交都会将binlog_cache中的数据强制写入磁盘。 innodb_doublewrite:控制是否打开double writer功能,取值ON或者OFF。 当Innodb的page size默认16K,磁盘单次写的page大小通常为4K或者远小于Innodb的page大小时,发生了系统断电/os crash ,刚好只有一部分写是成功的,则会遇到partial page write问题,从而可能导致crash后由于部分写失败的page影响数据的恢复。InnoDB为此提供了Double Writer技术来避免partial page write的发生。 innodb_support_xa:控制是否开启InnoDB的两阶段事务提交.默认情况下,innodb_support_xa=true,支持xa两段式事务提交。
以上参数不同的取值分别影响着MySQL异常crash后数据能恢复的程度和写入性能,实际使用过程中,需要结合业务的特性和实际需求,来设置合理的配置。比如:
MySQL单实例,Binlog关闭场景: innodb_flush_log_at_trx_commit=1,innodb_doublewrite=ON时,能够保证不论是MySQL Crash 还是OS Crash 或者是主机断电重启都不会丢失数据。 MySQL单实例,Binlog开启场景: 默认innodb_support_xa=ON,开启binlog后事务提交流程会变成两阶段提交,这里的两阶段提交并不涉及分布式事务,mysql把它称之为内部xa事务。 当innodb_flush_log_at_trx_commit=1,sync_binlog=1,innodb_doublewrite=ON,innodb_support_xa=ON时,同样能够保证不论是MySQL Crash 还是OS Crash 或者是主机断电重启都不会丢失数据。
但是,当由于主机硬件故障等原因导致主机完全无法启动时,则MySQL单实例面临着单点故障导致数据丢失的风险,故MySQL单实例通常不适用于生产环境。
二.MySQL集群的数据一致性
MySQL集群通常指MySQL的主从复制架构。通常使用MySQL主从复制来解决MySQL的单点故障问题,其通过逻辑复制的方式把主库的变更同步到从库,主备之间无法保证严格一致的模式,于是,MySQL的主从复制带来了主从“数据一致性”的问题。
MySQL的复制分为:异步复制、半同步复制、全同步复制。
异步复制
主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从库上,如果此时,强行将从提升为主,可能导致“数据不一致”。早期MySQL仅仅支持异步复制。
半同步复制
MySQL在5.5中引入了半同步复制,主库在应答客户端提交的事务前需要保证至少一个从库接收并写到relay log中,半同步复制通过rpl_semi_sync_master_wait_point参数来控制master在哪个环节接收 slave ack,master 接收到 ack 后返回状态给客户端,此参数一共有两个选项 AFTER_SYNC & AFTER_COMMIT。
配置为WAIT_AFTER_COMMIT
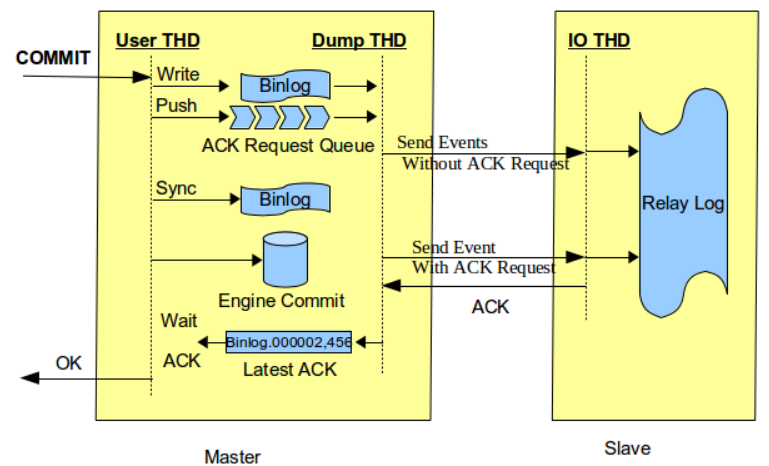
rpl_semi_sync_master_wait_point为WAIT_AFTER_COMMIT时,commitTrx的调用在engine层commit之后,如上图所示。即在等待Slave ACK时候,虽然没有返回当前客户端,但事务已经提交,其他客户端会读取到已提交事务。如果Slave端还没有读到该事务的events,同时主库发生了crash,然后切换到备库。那么之前读到的事务就不见了,出现了数据不一致的问题,如下图所示。图片引自Loss-less Semi-Synchronous Replication on MySQL 5.7.2。
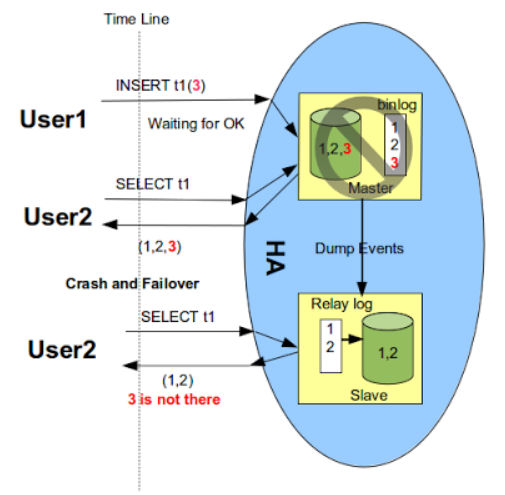
如果主库永远启动不了,那么实际上在主库已经成功提交的事务,在从库上是找不到的,也就是数据丢失了。
PS:早在11年前后,阿里巴巴数据库就创新实现了在engine层commit之前等待Slave ACK的方式来解决此问题。
配置为WAIT_AFTER_SYNC
MySQL官方针对上述问题,在5.7.2引入了Loss-less Semi-Synchronous,在调用binlog sync之后,engine层commit之前等待Slave ACK。这样只有在确认Slave收到事务events后,事务才会提交。如下图所示,图片引自Loss-less Semi-Synchronous Replication on MySQL 5.7.2 :
在after_sync模式下解决了after_commit模式带来的数据不一致的问题,因为主库没有提交事务。但也会有个问题,当主库在binlog flush并且binlog同步到了备库之后,binlog sync之前发生了abort,那么很明显这个事务在主库上是未提交成功的(由于abort之前binlog未sync完成,主库恢复后事务会被回滚掉),但由于从库已经收到了这些Binlog,并且执行成功,相当于在从库上多出了数据,从而可能造成“数据不一致”。
此外,MySQL半同步复制架构中,主库在等待备库ack时候,如果超时会退化为异步后,也可能导致“数据不一致”。
三.MySQL主备的“数据一致性”方案
下面简单介绍下阿里巴巴早期在MySQL数据一致性问题的一些思考和实践。
1.单元化架构下的“数据一致性”
背景:受机架位限制,单机房或地域总会出现容量瓶颈,业务发展受限;以及跨地域容灾的需求,阿里巴巴在早期通过单元化的方案来解决。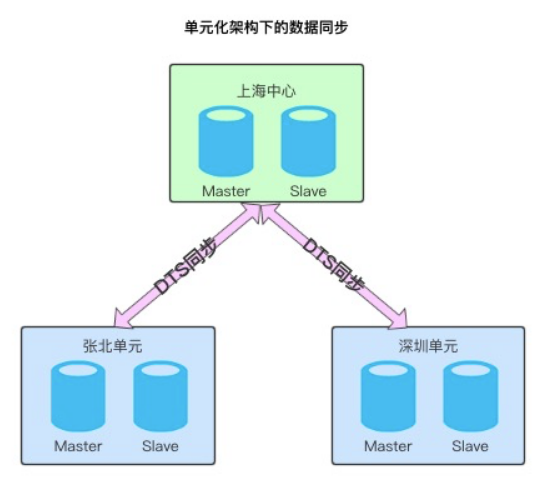
由上图看到中心和各单元之间通过DTS进行实时数据同步,为了保证中心和单元的数据一致性,我们早期搭建了数据校验和订正平台。主要包括:TCP(terminal compare platform)全量数据校验订正平台(支持表级,库级,实例级,集群级别的数据校验)和AMG(Alibaba Magic Glass)实时的增量数据校验订正平台。
TCP和AMG早已成为阿里巴巴数据库生态中的核心组件,被广泛用于众多场景中保障数据一致性,如:主从复制、单元化同步、逻辑迁移、数据库拆分、字符集升级等。
2.ADHA的回滚和回补
ADHA(Alibaba Database High Availability)是阿里巴巴集团数据库高可用体系。ADHA的回滚回补功能帮助我们在发生切换过程中尽量保证数据质量,将老主库还没传到老备库的数据回滚掉rollback,将回滚掉的数据回补到新主库中replay。
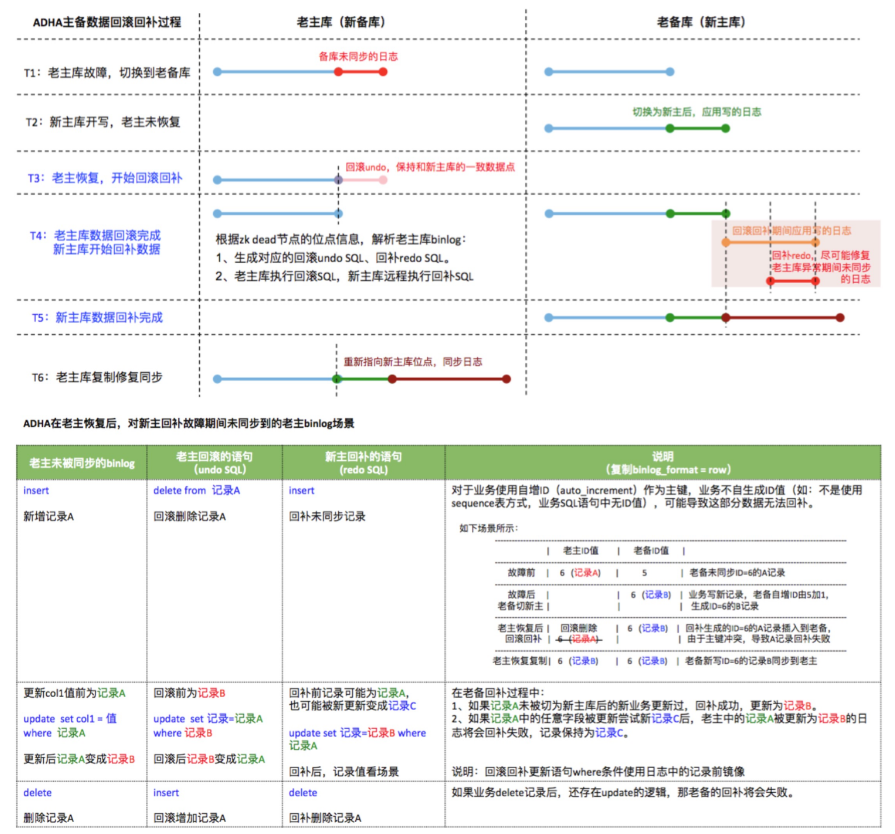
ADHA的回滚和回补的目的是尽量保证HA切换过程中的数据一致性。
3.主从一致性保障措施
复制冲突自动处理:MySQL 5.5/5.6/5.7的参数slave_exec_mode用于解决主从复制冲突和错误。默认值是STRICT适合于所有模式(不解决冲突),值IDEMPOTENT 会忽略duplicate-key和no-key-found错误,也不适合解决上面主从不一致问题。我们从5.6开始给slave_exec_mode增加了一个值smart,用于自动修复一些场景(包括PK冲突及UK冲突引起的HA_ERR_KEY_NOT_FOUND/HA_ERR_FOUND_DUPP_KEY/HA_ERR_END_OF_FILE),具体处理策略如下图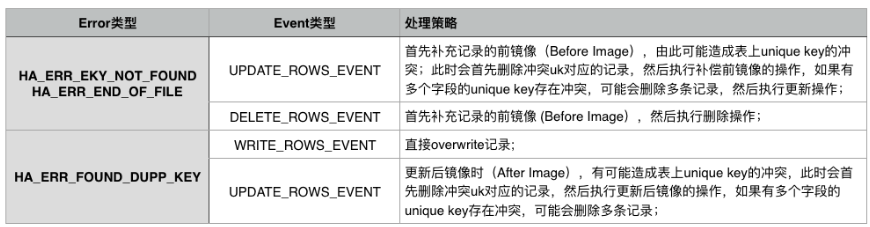
从库复制开启SMART模式,可以修复主从复制中断错误,但不能严格保证主备一致,因此当使用smart模式修复复制问题后,需要尽快对主从库做一个全量数据校验(这里包括TCP全量校验+AMG增量校验),以识别有差异的数据。
4.最大保护逻辑 Max Protection
为了保证主从强一致,我们增加了MySQL最大保护(maximum protection)模式功能,简称MP模式(这个是参照ORACLE数据库的最大保护模式(maximum protection))设计做的,具体由参数 maximum_protection 控制,取值为 ON和OFF )。当配置半同步时,一旦判断主从连接断开了,会让主库停止对外服务,主库所有当前连接会被KILL,并拒绝接受普通帐号新的连接请求。此刻如果有事务在等待从库回应binlog的同步信息这一步,连接是无法被kill,该事务在等待超时后会继续走完(Engine Commit),然后返回网络错误给客户端。即该笔事务被提交了,需要ADHA介入回滚掉。MySQL的MP机制是需要ADHA一起实现的。
引入最大保护逻辑,满足了对数据一致性要求非常高的业务场景,如金融业务。也给MySQL的高可用解决方案提出更大挑战。
以上都是我们早期在MySQL主备时代关于“数据一致性”问题的部分对策,其目的都是为了尽可能的保证“数据一致性”,并没有彻底解决“数据一致性”问题。然而我们相信技术的发展能带来更大的运维便利性以及更好的用户体验,以Google Spanner以及Amazon Aruora 为代表的NewSQL系统为数据库的“数据一致性”给出了与以往不同的思路: 基于一致性协议!基于一致性协议我们构建了高性能强一致MySQL数据库,RDS三节点企业版。关于一致性协议和RDS三节点企业版相关知识下面的章节会给大家详细介绍,敬请关注!
原文链接
本文为云栖社区原创内容,未经允许不得转载。













