

Hi!大家好呀!我是你们努力的喵哥!
很多同学都对变声成为别人的声音比较感兴趣。毕竟,声音可是人的重要特征。而且,在没有重大的身体特征变化情况,声音的特征都会跟随我们一辈子。
换个声音,通常会有新的体验。通过变声,突然间给朋友个惊喜,感觉应该很不错的。
是的,说的就是柯南那种效果!

变声也是现在恶搞最常用的方式之一。在短视频大行其道的今天,网上可以找到各式各样的恶搞视频。一些变声视频,娱乐效果满满。看游戏直播的同学,应该对这个场景并不陌生吧。萌萌的萝莉,屏幕后的抠脚大汉。乔碧萝?
如果你是短视频作者,肯定也少不了这个主题。很多短视频 App 也会带有变声的玩法。
如果,那些语音助手 App 也能实现任意切换成任何人的语音,甚至能使用自己语音作为语音助手的声音,是不是非常酷?想想每天早上叫你起床的是你的某个女神的声音!是不是一天感觉都精神了很多。
最常用的变身方式是使用各类变声软件,去调节声音的各类数字特征,以输出特定风格的声音。这种方式,通常可以实现把男声转化为女声、把年轻人的声音转化为老人的声音等。所以,变声软件仅仅是声音风格的改变,很难实现模拟相同的声音。

那么到这里,喵哥就又要开始推荐开源项目了。这个人工智能项目,可以实现人声的学习和模拟。比如,输入一段周杰伦的唱歌的语音,就可以模拟输出周杰伦的声音。例如,输入一段文字,以周杰伦的声音念出来。甚至,你在唱歌的时候,实时将你歌声转化为周杰伦的声音。是不是非常酷?这个开源的人工智能项目就是 Real-Time Voice Cloning。
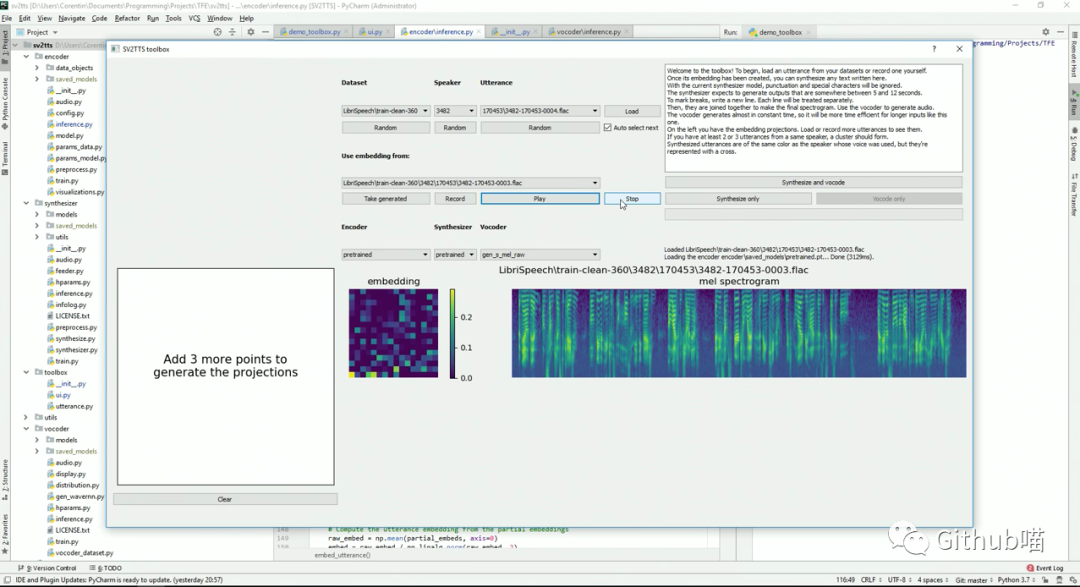
Real-Time Voice Cloning 是“Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis(SV2TTS)”论文的实现,这是一个三阶深度学习框架,允许从几秒钟的音频中创建一个数字化的语音,并使用它来调节训练的“文本转语音”模型,以推广到新的声音。此项目中带有一个实时工作的声码器。
安装和使用
1.安装要求
需要Python 3.6或3.7才能运行该工具箱。
安装PyTorch(> = 1.0.1)。
安装ffmpeg。
运行pip install -r requirements.txt以安装其余必需的软件包。
2.下载预训练的模型
在 Wiki 的 Pretrained-models 中下载最新版本。
3.测试配置(可选)
在下载任何数据集之前,您可以先使用以下方法测试配置:
python demo_cli.py
如果所有测试都通过,那就 OK。
4.下载数据集(可选)
对于仅使用工具箱的情况,建议下载 LibriSpeech/train-clean-100。提取内容 /LibriSpeech/train-clean-100 的 是你选择的目录。
工具箱中支持其他数据集,请参见 Wiki。
您也可以不下载任何数据集,但是您将需要自己的数据作为音频文件,或者必须在工具箱中记录下来。
5.启动工具箱
然后,您可以尝试使用工具箱:
python demo_toolbox.py -d
取决于您是否下载了任何数据集。
6.启用GPU支持(可选)
注意:启用GPU支持是很多工作。如果您要训练自己的模型,则需要进行设置。
pip install -r requirements_gpu.txt
此外,您需要确保正确安装了GPU驱动程序,并且您的CUDA版本与PyTorch和Tensorflow安装相匹配。
最后
喵哥要特别友情提醒下大家,声音也是有版权的,可不要乱搞哦!特别是名人的声音!
Real-Time Voice Cloning 项目的作者是 Corentin Jemine 。该项目是去年开源在 Github 的,共有12位贡献者。Real-Time Voice Cloning 在 Github 上共收获了 18.4k Star。
Corentin Jemine 现在已经是全职在开发该项目的商业升级版本。所以,基于 Real-Time Voice Cloning 之上 Resemble.AI 提供了更好的体验。
项目地址:https://github.com/CorentinJ/Real-Time-Voice-Cloning
Resemble.AI:https://www.resemble.ai/
往期精彩内容:
再见 Excel?推荐这款集成 Python 的电子表格神器
...
关注Github喵,回复「进阶」,
领取喵哥推荐的技术进阶知识大礼包!!!
扫描二维码
获取更多内容
Github喵


本文分享自微信公众号 - Github喵(gh_acfcf1689379)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










