@[toc]
一、项目概述
1.项目说明
本项目主要是对领导留言板内的所有留言的具体内容进行抓取,对留言详情、回复详情和评价详情进行提取保存,并用于之后的数据分析和进一步处理,可以对政府的决策和电子政务的实施提供依据。
网站链接是http://liuyan.people.com.cn/home?p=0,任意选择一条留言点击进入详情页后,如下
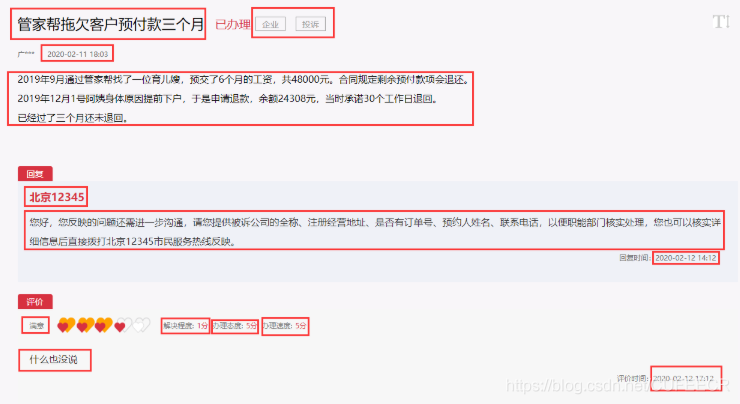 对于图中标出的数据,均要进行爬取,以此构成一条留言的组成部分。
对于图中标出的数据,均要进行爬取,以此构成一条留言的组成部分。
2.环境配置
(1)Python:3.x (2)所需库:
- dateutil
- 安装方法:
pip install python-dateutil
- selenium
- 安装方法:
pip install selenium
(3)模拟驱动: chromedriver,可点击https://download.csdn.net/download/CUFEECR/12193208进行下载Google浏览器80.0.3987.16版对应版本,或点击http://chromedriver.storage.googleapis.com/index.html下载与Google对应版本,并放入Python对应安装路径下的Scripts目录下。
二、项目实施
1.导入所需要的库
import csv
import os
import random
import re
import time
import dateutil.parser as dparser
from random import choice
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.chrome.options import Options主要导入在爬取过程中需要用到的处理库和selenium中要用到的类。
2.全局变量和参数配置
# 时间节点
start_date = dparser.parse('2019-06-01')
# 浏览器设置选项
chrome_options = Options()
chrome_options.add_argument('blink-settings=imagesEnabled=false')我们假设只爬取2019.6.1以后的留言,因为这之前的留言自动给好评,没有参考价值,因此设置时间节点,并禁止网页加载图片,减少对网络的带宽要求、提升加载速率。
3.产生随机时间和用户代理
def get_time():
'''获取随机时间'''
return round(random.uniform(3, 6), 1)
def get_user_agent():
'''获取随机用户代理'''
user_agents = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1",
"Mozilla/5.0 (Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.23 Mobile Safari/537.36",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20",
"Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
]
# 在user_agent列表中随机产生一个代理,作为模拟的浏览器
user_agent = choice(user_agents)
return user_agent
产生随机时间并随机模拟浏览器用于访问网页,降低被服务器识别出是爬虫而被禁的可能。
4.获取领导的fid
def get_fid():
'''获取所有领导id'''
with open('url_fid.txt', 'r') as f:
content = f.read()
fids = content.split()
return fids每个领导都有一个fid用于区分,这里采用手动获取fid并保存到txt中,在开始爬取时再逐行读取。
5.获取领导所有留言链接
def get_detail_urls(position, list_url):
'''获取每个领导的所有留言链接'''
user_agent = get_user_agent()
chrome_options.add_argument('user-agent=%s' % user_agent)
drivertemp = webdriver.Chrome(options=chrome_options)
drivertemp.maximize_window()
drivertemp.get(list_url)
time.sleep(2)
# 循环加载页面
while True:
datestr = WebDriverWait(drivertemp, 10).until(
lambda driver: driver.find_element_by_xpath(
'//*[@id="list_content"]/li[position()=last()]/h3/span')).text.strip()
datestr = re.search(r'\d{4}-\d{2}-\d{2}', datestr).group()
date = dparser.parse(datestr, fuzzy=True)
print('正在爬取链接 --', position, '--', date)
if date < start_date:
break
# 模拟点击加载
try:
WebDriverWait(drivertemp, 50, 2).until(EC.element_to_be_clickable((By.ID, "show_more")))
drivertemp.execute_script('window.scrollTo(document.body.scrollHeight, document.body.scrollHeight - 600)')
time.sleep(get_time())
drivertemp.execute_script('window.scrollTo(document.body.scrollHeight - 600, document.body.scrollHeight)')
WebDriverWait(drivertemp, 50, 2).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="show_more"]')))
drivertemp.find_element_by_xpath('//*[@id="show_more"]').click()
except:
break
time.sleep(get_time() - 1)
detail_elements = drivertemp.find_elements_by_xpath('//*[@id="list_content"]/li/h2/b/a')
# 获取所有链接
for element in detail_elements:
detail_url = element.get_attribute('href')
yield detail_url
drivertemp.quit()根据第4步提供的fid找到一个领导对应的所有留言的链接,由于领导的留言列表并未一次显示完,下方有一个加载更多按钮,如下
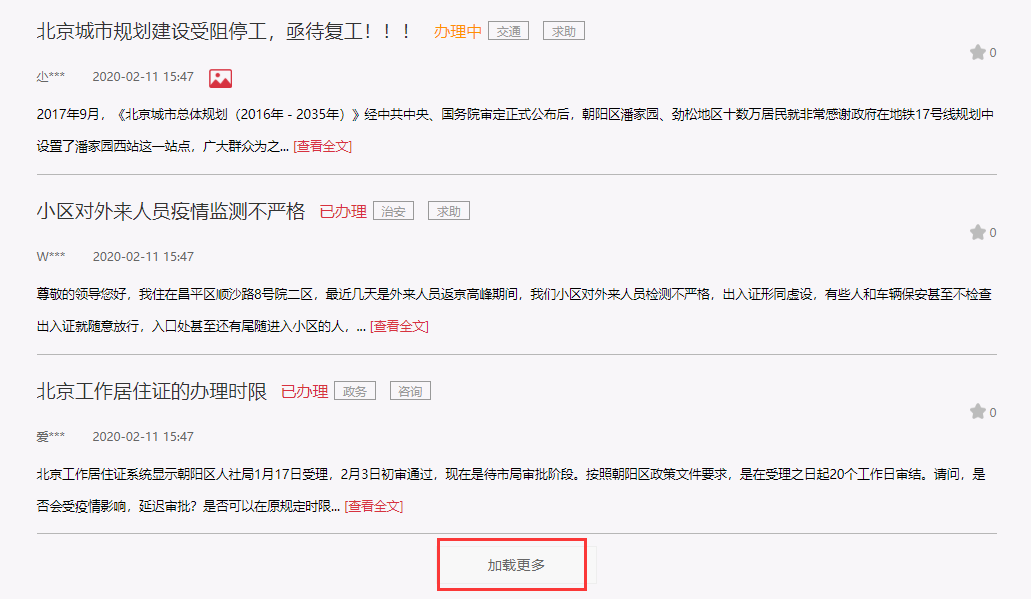 每次需要进行点击向下加载,所以要模拟点击的操作,向下滑动,等完全加载后再次点击,直到底部。
函数返回值时,不是一次返回一个列表,而是通过yield关键字生成生成器,按照程序执行的进度生成url,可以减少内存的压力。
每次需要进行点击向下加载,所以要模拟点击的操作,向下滑动,等完全加载后再次点击,直到底部。
函数返回值时,不是一次返回一个列表,而是通过yield关键字生成生成器,按照程序执行的进度生成url,可以减少内存的压力。
6.获取留言详情
def get_message_detail(driver, detail_url, writer, position):
'''获取留言详情'''
print('正在爬取留言 --', position, '--', detail_url)
driver.get(detail_url)
# 判断,如果没有评论则跳过
try:
satis_degree = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_element_by_class_name("sec-score_firstspan")).text.strip()
except:
return
# 获取留言各部分内容
message_date_temp = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_element_by_xpath("/html/body/div[6]/h3/span")).text
message_date = re.search(r'\d{4}-\d{2}-\d{2}', message_date_temp).group()
message_datetime = dparser.parse(message_date, fuzzy=True)
if message_datetime < start_date:
return
message_title = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_element_by_class_name("context-title-text")).text.strip()
label_elements = WebDriverWait(driver, 2.5).until(lambda driver: driver.find_elements_by_class_name("domainType"))
try:
label1 = label_elements[0].text.strip()
label2 = label_elements[1].text.strip()
except:
label1 = ''
label2 = label_elements[0].text.strip()
message_content = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_element_by_xpath("/html/body/div[6]/p")).text.strip()
replier = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_element_by_xpath("/html/body/div[8]/ul/li[1]/h3[1]/i")).text.strip()
reply_content = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_element_by_xpath("/html/body/div[8]/ul/li[1]/p")).text.strip()
reply_date_temp = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_element_by_xpath("/html/body/div[8]/ul/li[1]/h3[2]/em")).text
reply_date = re.search(r'\d{4}-\d{2}-\d{2}', reply_date_temp).group()
review_scores = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_elements_by_xpath("/html/body/div[8]/ul/li[2]/h4[1]/span/span/span"))
resolve_degree = review_scores[0].text.strip()[:-1]
handle_atti = review_scores[1].text.strip()[:-1]
handle_speed = review_scores[2].text.strip()[:-1]
review_content = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_element_by_xpath("/html/body/div[8]/ul/li[2]/p")).text.strip()
is_auto_review = '是' if (('自动默认好评' in review_content) or ('默认评价' in review_content)) else '否'
review_date_temp = WebDriverWait(driver, 2.5).until(
lambda driver: driver.find_element_by_xpath("/html/body/div[8]/ul/li[2]/h4[2]/em")).text
review_date = re.search(r'\d{4}-\d{2}-\d{2}', review_date_temp).group()
# 存入CSV文件
writer.writerow(
[position, message_title, label1, label2, message_date, message_content, replier, reply_content, reply_date,
satis_degree, resolve_degree, handle_atti, handle_speed, is_auto_review, review_content, review_date])我们只需要有评论的留言,因此在最开始要过滤掉没有评论的留言。然后通过xpath、class_name等方式定位到相应的元素获取留言的各个部分的内容,每条留言共保存14个内容,并保存到csv中。
7.获取并保存领导所有留言
def get_officer_messages(index, fid):
'''获取并保存领导的所有留言'''
user_agent = get_user_agent()
chrome_options.add_argument('user-agent=%s' % user_agent)
driver = webdriver.Chrome(options=chrome_options)
list_url = "http://liuyan.people.com.cn/threads/list?fid={}#state=4".format(fid)
driver.get(list_url)
position = WebDriverWait(driver, 10).until(
lambda driver: driver.find_element_by_xpath("/html/body/div[4]/i")).text
# time.sleep(get_time())
print(index, '-- 正在爬取 --', position)
start_time = time.time()
# encoding='gb18030'
csv_name = position + '.csv'
# 文件存在则删除重新创建
if os.path.exists(csv_name):
os.remove(csv_name)
with open(csv_name, 'a+', newline='', encoding='gb18030') as f:
writer = csv.writer(f, dialect="excel")
writer.writerow(
['职位姓名', '留言标题', '留言标签1', '留言标签2', '留言日期', '留言内容', '回复人', '回复内容', '回复日期', '满意程度', '解决程度分', '办理态度分',
'办理速度分', '是否自动好评', '评价内容', '评价日期'])
for detail_url in get_detail_urls(position, list_url):
get_message_detail(driver, detail_url, writer, position)
time.sleep(get_time())
end_time = time.time()
crawl_time = int(end_time - start_time)
crawl_minute = crawl_time // 60
crawl_second = crawl_time % 60
print(position, '已爬取结束!!!')
print('该领导用时:{}分钟{}秒。'.format(crawl_minute, crawl_second))
driver.quit()
time.sleep(5)获取该领导的职位信息并为该领导创建一个独立的csv用于保存提取到的留言信息,调用get_message_detail()方法获取每条留言的具体信息并保存,计算出每个领导的执行时间。
8.合并文件
def merge_csv():
'''将所有文件合并'''
file_list = os.listdir('.')
csv_list = []
for file in file_list:
if file.endswith('.csv'):
csv_list.append(file)
# 文件存在则删除重新创建
if os.path.exists('DATA.csv'):
os.remove('DATA.csv')
with open('DATA.csv', 'a+', newline='', encoding='gb18030') as f:
writer = csv.writer(f, dialect="excel")
writer.writerow(
['职位姓名', '留言标题', '留言标签1', '留言标签2', '留言日期', '留言内容', '回复人', '回复内容', '回复日期', '满意程度', '解决程度分', '办理态度分',
'办理速度分', '是否自动好评', '评价内容', '评价日期'])
for csv_file in csv_list:
with open(csv_file, 'r', encoding='gb18030') as csv_f:
reader = csv.reader(csv_f)
line_count = 0
for line in reader:
line_count += 1
if line_count != 1:
writer.writerow(
(line[0], line[1], line[2], line[3], line[4], line[5], line[6], line[7], line[8],
line[9], line[10], line[11], line[12], line[13], line[14], line[15]))将爬取的所有领导的数据进行合并。
9.主函数调用
def main():
'''主函数'''
fids = get_fid()
print('爬虫程序开始执行:')
s_time = time.time()
for index, fid in enumerate(fids):
try:
get_officer_messages(index + 1, fid)
except:
get_officer_messages(index + 1, fid)
print('爬虫程序执行结束!!!')
print('开始合成文件:')
merge_csv()
print('文件合成结束!!!')
e_time = time.time()
c_time = int(e_time - s_time)
c_minute = c_time // 60
c_second = c_time % 60
print('{}位领导共计用时:{}分钟{}秒。'.format(len(fids), c_minute, c_second))
if __name__ == '__main__':
'''执行主函数'''
main()主函数中先获取领导所有留言,再合并所有数据文件,完成整个爬取过程,并统计整个程序的运行时间,便于分析运行效率。
三、结果、分析及说明
1.结果说明
完整代码和测试执行结果可点击https://download.csdn.net/download/CUFEECR/12198734下载,仅供交流学习,请勿滥用。
整个执行过程较长,因为是单线程的,必须要等一个领导数据爬取完毕之后才能爬取下一个,我选择了10个领导进行测试,在云服务器中的运行结果分别如下



 )
)
 )
) )
)
 )
)
 显然,整个运行时间将近5小时,效率相对较低,有很大的提升空间。
最终得到了合并的DATA.csv:
显然,整个运行时间将近5小时,效率相对较低,有很大的提升空间。
最终得到了合并的DATA.csv:
2.改进分析
(1)该版本的代码未实现自动爬取所有的fid,需要手动保存,是其中一点不足,可以在后期改进。 (2)爬取留言详情页也是采用的selenium模拟,会降低请求效率,可以考虑用requests库请求。 (3)该版本是单进程(线程)的,必须要一个领导爬取完之后才能进行下一个领导的爬取,效率较低,特别是留言较多的领导耗时很长,可以考虑使用多进程或多线程进行优化。
3.合法性说明
- 本项目是为了学习和科研的目的,所有读者可以参考执行思路和程序代码,但不能用于恶意和非法目的(恶意攻击网站服务器、非法盈利等),如有违者请自行负责。
- 本项目所获取的数据都是在进一步的分析之后用于对电子政务的实施改进,对政府的决策能起到一定的参考作用,并非于恶意抓取数据来攫取不正当竞争的优势,也未用于商业目的牟取不法利益,运行代码只是用几个fid进行测试,并非大范围地爬取,同时严格控制爬取的速率、争取不对服务器造成压力,如侵犯当事者(即被抓取的网络主体)的利益,请联系更改或删除。
- 本项目是留言板爬取系列的第一篇,后期会继续更新,欢迎读者交流,以期不断改进。
本文原文首发来自博客专栏Python爬虫,由本人转发至https://www.helloworld.net/p/QPrHpgSpkFyz,其他平台均属侵权,可点击https://blog.csdn.net/CUFEECR/article/details/104515322查看原文,也可点击https://blog.csdn.net/CUFEECR浏览更多优质原创内容。