
互联网并发编程中,锁的概念时时刻刻都在我们身边,无论是并发编程时候线程锁,还是数据库网络中的锁,都有一些相似之处,都是为了保持数据库的完整性和一致性。不恰当的使用锁,会导致性能下降,出现死锁等情况,所以弄清楚锁的原理概念是必要的。
一、锁分类
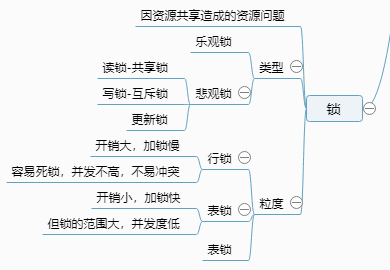
二、悲观锁(Pessimistic Lock)
顾名思义,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人拿这个数据就会阻塞,直到它拿锁。正如其名,具有强烈的独占和排他特性。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制。传统的关系数据库里用到了很多这种锁机制,比如行锁、表锁、读锁、写锁等,都是在操作之前先上锁。
1.共享锁(Share Lock)
S锁,也叫读锁,用于所有的只读数据操作。共享锁是非独占的,允许多个并发事务读取其锁定的资源。结合下图我们可以知道,有如下性质:
- 多个事务可封锁同一个共享页;
- 任何事务都不能修改该页;
- 通常是该页被读取完毕,S锁应立即被释放。
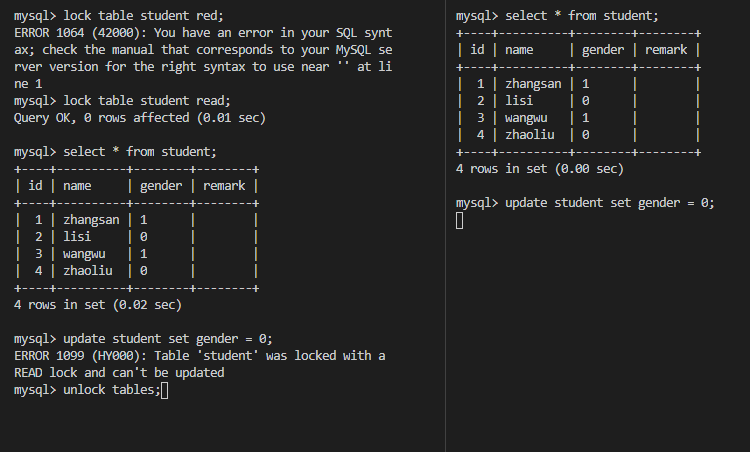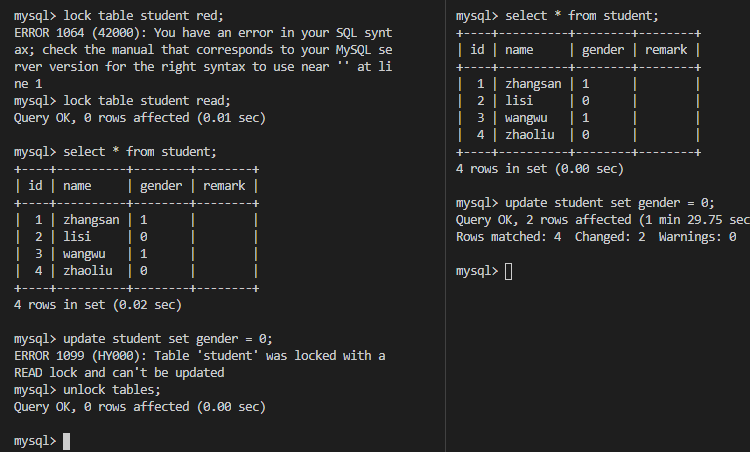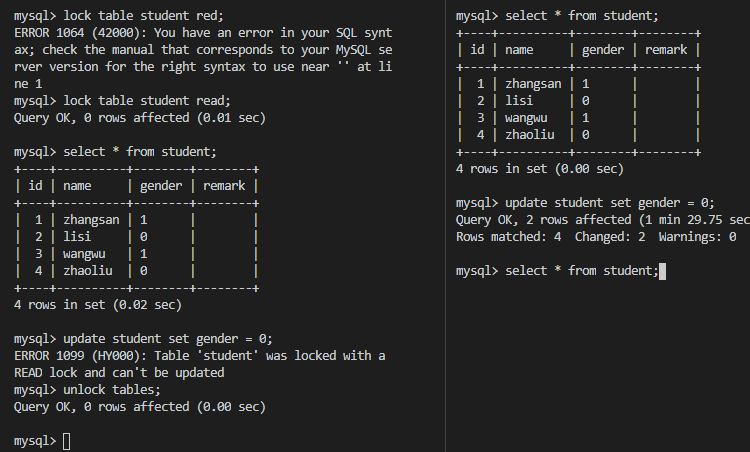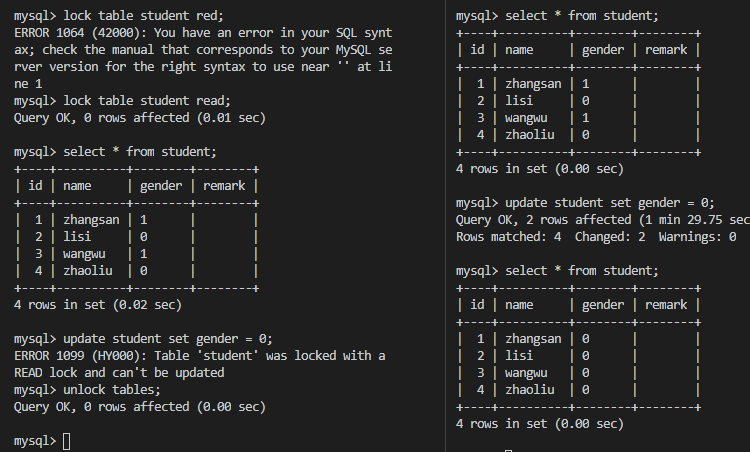
2.排他锁(Exclusive Lock)
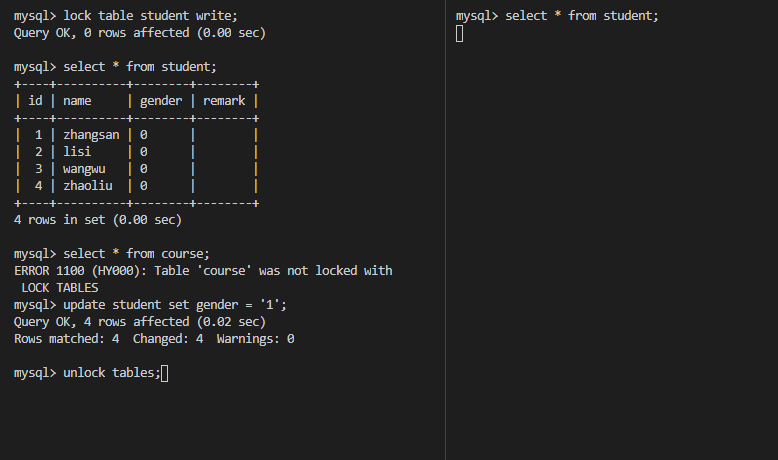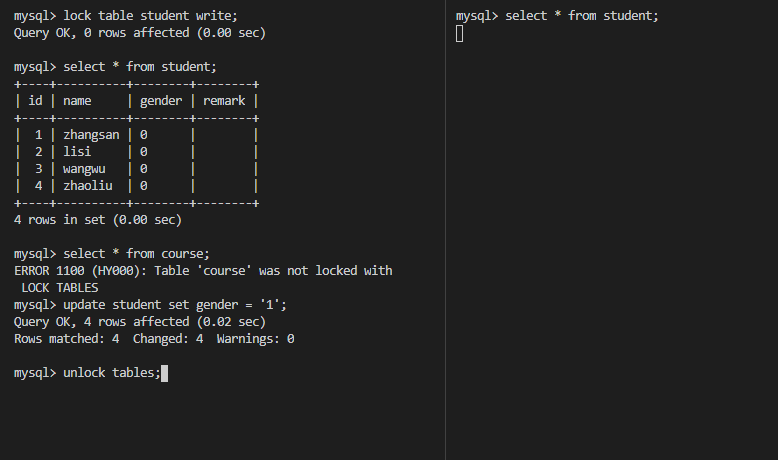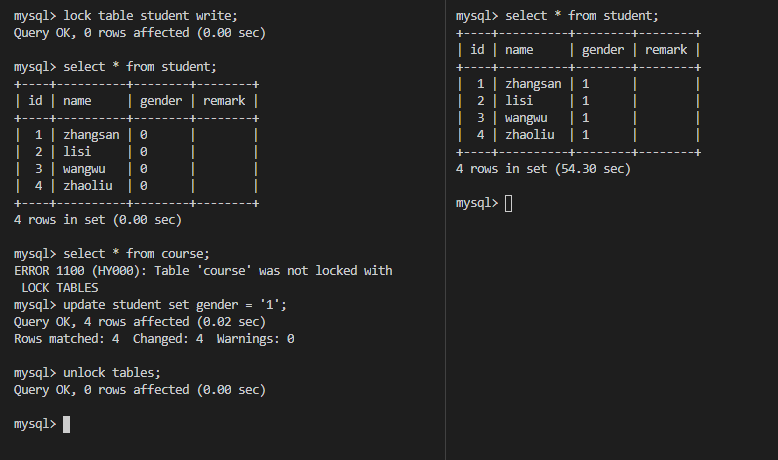
X锁,也叫写锁,表示对数据进行写操作。如果一个事务对对象加了排他锁,其他事务就不能再给它加任何锁了。结合下图可以得出以下特性:
- 仅允许一个事务封锁此页;
- 其他任何事务必须等到X锁被释放才能对该页进行访问;
- X锁一直到事务结束才能被释放。
3.更新锁
U锁,在修改操作的初始化阶段用来锁定可能要被修改的资源,这样可以避免使用共享锁造成的死锁现象。因为当使用共享锁时,修改数据的操作分为两步:
- 首先获得一个共享锁,读取数据,
- 然后将共享锁升级为排他锁,再执行修改操作。
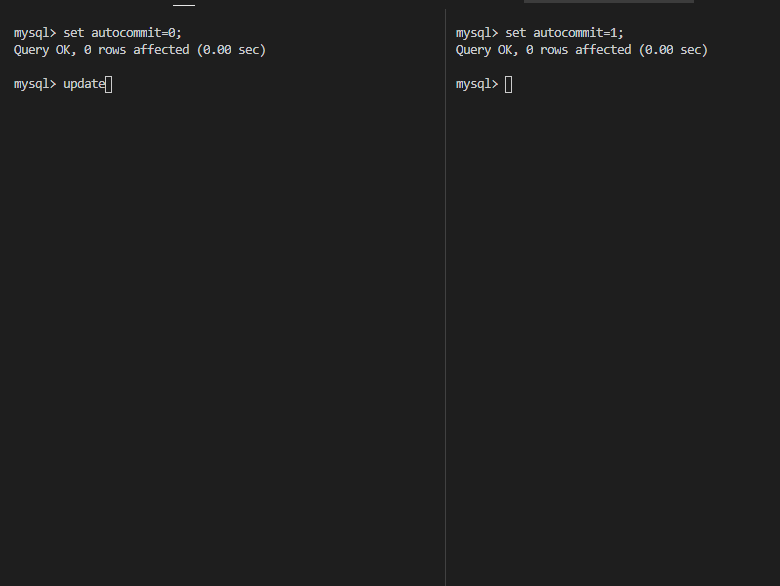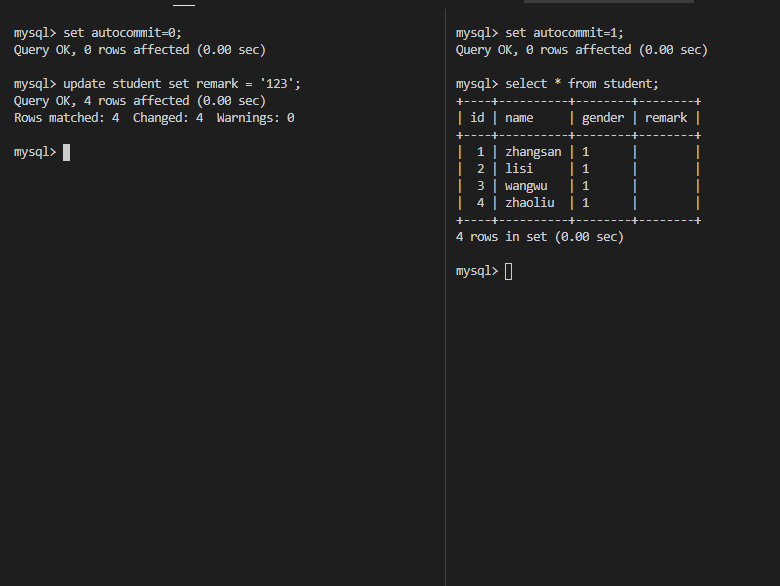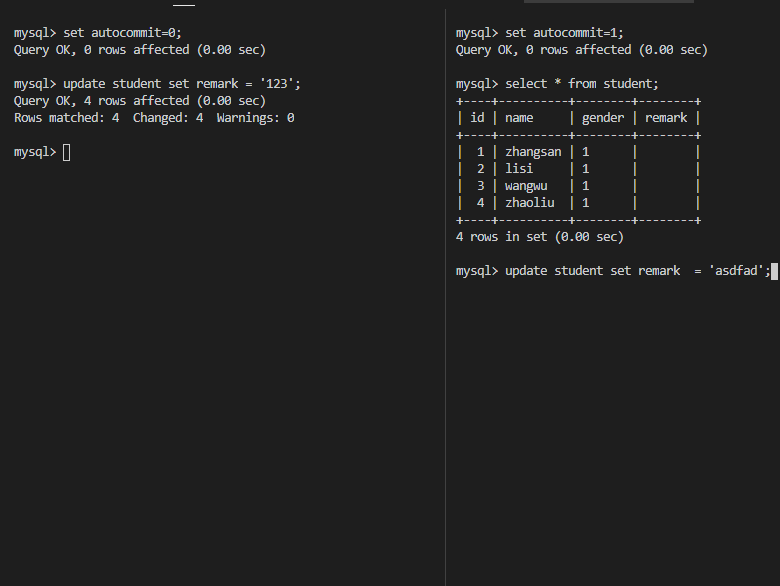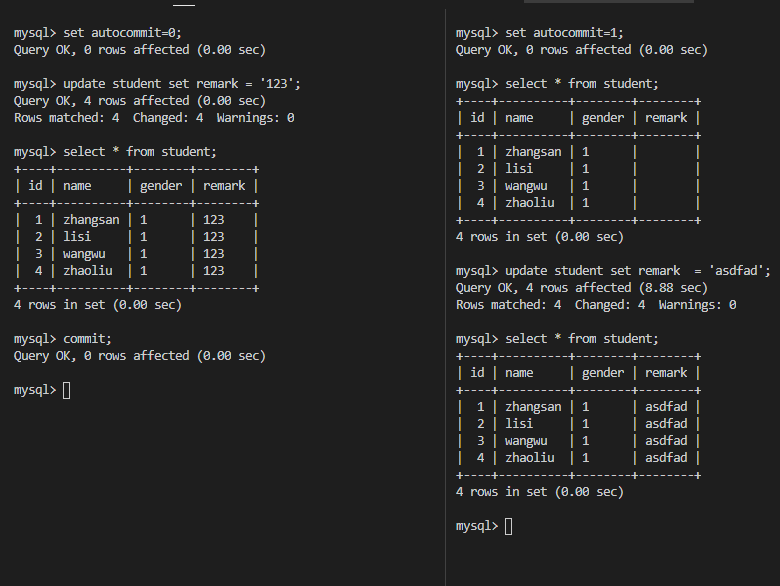
这样如果有两个或多个事务同时对一个事务申请了共享锁,在修改数据时,这些事务都要将共享锁升级为排他锁。这时,这些事务都不会释放共享锁,而是一直等待对方释放,这样就造成了死锁。如果一个数据在修改前直接申请更新锁,在数据修改时再升级为排他锁,就可以避免死锁。
- 用来预定要对此页施加X锁,它允许其他事务读,但不允许再施加U锁或X锁;
- 当被读取的页要被更新时,则升级为X锁;
- U锁一直到事务结束时才能被释放。
4.锁的危害
当索引失效的时候,比如类型不匹配,行锁变表锁。
update student set remark = '3332' where id = '231'间隙锁的危害,在innodb上,叶子节点存储的数据是链表结构,而且依次递增的,当用范围查询的时候,导致间隙锁,中间的数据全部锁定。
select * from student where id > 1 and id <3; update student set remark = '123' where id =2;
三、乐观锁(Optimistic Lock)
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。而乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本( Version )记录机制实现。
版本号(version)
版本号(记为version):就是给数据增加一个版本标识,在数据库上就是表中增加一个version字段,每次更新把这个字段加1,读取数据的时候把version读出来,更新的时候比较version,如果还是开始读取的version就可以更新了,如果现在的version比老的version大,说明有其他事务更新了该数据,并增加了版本号,这时候得到一个无法更新的通知,用户自行根据这个通知来决定怎么处理,比如重新开始一遍。这里的关键是判断version和更新两个动作需要作为一个原子单元执行,否则在你判断可以更新以后正式更新之前有别的事务修改了version,这个时候你再去更新就可能会覆盖前一个事务做的更新,造成第二类丢失更新,所以你可以使用update … where … and version=”old version”这样的语句,根据返回结果是0还是非0来得到通知,如果是0说明更新没有成功,因为version被改了,如果返回非0说明更新成功。
时间戳(使用数据库服务器的时间戳)
时间戳(timestamp):和版本号基本一样,只是通过时间戳来判断而已,注意时间戳要使用数据库服务器的时间戳不能是业务系统的时间。
单机中数据库锁的概念,无外乎以上的锁的概念,在工作实践中,还需要对分布式锁和分布式事务作深入分析。













