
“Hadoop能做什么?” ,概括如下:
1)搜索引擎:这也正是Doug Cutting设计Hadoop的初衷,为了针对大规模的网页快速建立索引;
2)大数据存储:利用Hadoop的分布式存储能力,例如数据备份、数据仓库等;
3)大数据处理:利用Hadoop的分布式处理能力,例如数据挖掘、数据分析等;
4)科学研究:Hadoop是一种分布式的开源框架,对于分布式系统有很大程度地参考价值。
Hadoop有三种不同的模式操作,分别为单机模式、伪分布模式和全分布模式。每种模式的详细介绍以及单机模式的安装请阅读我之前的博客:[Hadoop] 在Ubuntu系统上一步步搭建Hadoop(单机模式),伪分布式模式和全分布式模式的
Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)是Hadoop的核心模块之一,它主要解决Hadoop的大数据存储问题,其思想来源与Google的文件系统GFS。HDFS的主要特点:
- 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
- 运行在廉价的机器上。
- 适合大数据的处理。HDFS默认会将文件分割成block,64M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。
HDFS中的两个重要角色:
[Namenode]
1)管理文件系统的命名空间。
2)记录 每个文件数据快在各个Datanode上的位置和副本信息。
3)协调客户端对文件的访问。
4)记录命名空间内的改动或者空间本省属性的改动。
5)Namenode 使用事务日志记录HDFS元数据的变化。使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等。
从社会学来看,Namenode是HDFS里面的管理者,发挥者管理、协调、操控的作用。
[Datanode]
1)负责所在物理节点的存储管理。
2)一次写入,多次读取(不修改)。
3)文件由数据库组成,一般情况下,数据块的大小为64MB。
4)数据尽量散步到各个节点。
从社会学的角度来看,Datanode是HDFS的工作者,发挥按着Namenode的命令干活,并且把干活的进展和问题反馈到Namenode的作用。
客户端如何访问HDFS中一个文件呢?具体流程如下:
1)首先从Namenode获得组成这个文件的数据块位置列表。
2)接下来根据位置列表知道存储数据块的Datanode。
3)最后访问Datanode获取数据。
注意:Namenode并不参与数据实际传输。
数据存储系统,数据存储的可靠性至关重要。HDFS是如何保证其可靠性呢?它主要采用如下机理:
1)冗余副本策略,即所有数据都有副本,副本的数目可以在hdfs-site.xml中设置相应的复制因子。
2)机架策略,即HDFS的“机架感知”,一般在本机架存放一个副本,在其它机架再存放别的副本,这样可以防止机架失效时丢失数据,也可以提供带宽利用率。
3)心跳机制,即Namenode周期性从Datanode接受心跳信号和快报告,没有按时发送心跳的Datanode会被标记为宕机,不会再给任何I/O请求,若是Datanode失效造成副本数量下降,并且低于预先设置的阈值,Namenode会检测出这些数据块,并在合适的时机进行重新复制。
4)安全模式,Namenode启动时会先经过一个“安全模式”阶段。
5)校验和,客户端获取数据通过检查校验和,发现数据块是否损坏,从而确定是否要读取副本。
6)回收站,删除文件,会先到回收站/trash,其里面文件可以快速回复。
7)元数据保护,映像文件和事务日志是Namenode的核心数据,可以配置为拥有多个副本。
8)快照,支持存储某个时间点的映像,需要时可以使数据重返这个时间点的状态。
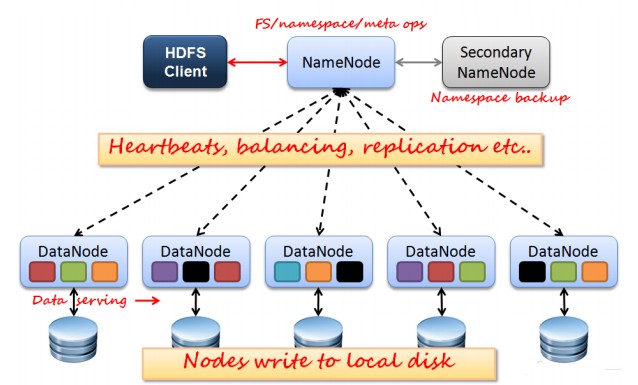
如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。














