
Fourinone4.0版新特性:一个高性能的数据库引擎CoolHash(酷哈嘻)
一、前言:如何写一个数据库
如果将操作系统和业务应用之间的软件都统称中间件的话,那么最重要的软件无疑是数据库,它比web应用服务器市场更大,几乎所有的业务系统都需要数据库,所有的企业都会购买数据库。无论是早期的商业智能也好,数据分析挖掘也好,近年的分布式存储也好,大数据也好...围绕数据变着花样的新理念新技术再多,都是“乱花渐欲迷人眼,浅草才能没马蹄”,其实最核心的还是数据库技术。
就像华为想进军软件市场已经很久了,我脑海里一直惦记着数据库技术,几年来不断收集数据库实现技术,但是一直不得要领,几欲放弃,没有碰到一个白胡子老头传授秘籍,国内也几乎没有这方面的书籍,找了几本国外的教材,要么翻译的不好,要么英文啃起来费劲,书里更多是讲数据库相关的基础知识,但是不会告诉你怎么做,好比是你想学变脸,但是总在教你唱戏,其实你只想知道变脸是用线拉的就行了。行业技术机密都是避而不谈的,感觉从书本上是学不到的。
去年给一个银行技术老总讲解大数据方案,他突然问到,你们能不能不用别人的,自己写个ORACLE这样的数据库出来,我们每年花在license和服务费非常昂贵,升级也很痛苦,但是也没有办法。我承诺可以抽业余时间研究一下,不过他马上又说,就算有也不会马上用,可以先开源出来,可以看出他无比纠结的心态,也许他对太多架构师说过这样的话,可能现在都忘了,但是这件事再次给了我触动,言语之间能感受到客户寄托出的一种期望,希望中国企业能成长为ORACLE、IBM这样的角色。
要实现一个数据库,首先不能不谈起数据库引擎。数据库引擎和数据库产品的关系,就像汽车发动机和汽车的关系,有了发动机,剩下的只是装配工作。知名的数据库引擎有“ISAM、MyISAM、InnoDB、PostgreSQL、BerkeleyDB等”,另外也有些产品模糊在“数据库引擎、数据库server、数据库管理系统”之间的,如近几年的redis,还有JDK6.0起自带一个java编写的只有2m大的关系数据库Derby(由IBM捐献),另外值得一提的还有SQLite,一个很轻量级嵌入式的数据库(3万c代码,250k大小),但是功能齐全,实现了ACID和SQL标准,目前广泛应用于苹果的Mac操作系统和Android移动操作系统中,缺点是多用户高并发承受能力较弱。
世界上大部分的数据库产品都是围绕部分数据库引擎扩充出来的,比如大家熟悉的Mysql,它的数据库引擎叫MyISAM,MyISAM是在ISAM发展而来,ISAM也是一个知名的数据库引擎,最初被IBM开发,它读的性能大于写,但是索引功能和事务处理缺乏,MyISAM相对于ISAM做了很多改进,优化了表锁和并发操作,但是由于继承的原因,仍然倾向于多读少写操作。ISAM系列引擎的大致设计原理:采用B树设计,分成表元数据、表数据、表索引3部分存储,读的快是因为维持大量的索引结构指向数据存储位置,但是由于删除更新容易导致大量数据碎片和空间浪费,常常需要执行“OPTIMIZE TABLE”,从而又导致索引常常需要重新计算。Mysql5.5以后默认采用InnoDB引擎,还可以使用BerkeleyDB,InnoDB和BerkeleyDB包括了对事务处理和外键的支持,这是ISAM系列引擎所没有的特性,另外InnoDB的锁设计的要精明一点,锁到少数行的数据块上,而不是整表锁。
关于ISAM系列的发展有很多,IBM开发了VSAM代替ISAM,VSAM被IBM一个数据库产品所使用 ,就是大名鼎鼎的DB2。虽然MySql的数据库引擎换成了InnoDB,但是MySql的作者迈克尔(Michael Widenius)从MySql旧版本发展了另一个分支,并以自己的小女儿名字命名为MariaDB(玛丽亚),MariaDB的数据库引擎叫做Aria,但实际上还是MyISAM,只是增加了些key缓存改进(Segmented Key Cache),MariaDB数据库得到了google等企业的大力支持,普通的观点认为oralce收购Mysql的最终目的是想其慢慢死亡,而不是想着如何把它发展更好。
PostgreSQL和BerkeleyDB都是来源于加州伯克利分校,一个面向关系数据,一个面向k/v数据,虽然知名和流行程度不如Mysql,但是也各有优势,PostgreSQL的关系数据库功能实现的比较完整,包括了很多高级特性,并且采用BSD/MIT开源协议,因此比较适合用来封装成数据库产品,这种协议允许任何人使用修改代码,但是要保留版权声明,BerkeleyDB提供了一个高并发访问的k/v数据库引擎,但不是一个数据库server,不提供网络访问,不支持sql,但可以支持函数式操作,数据库产品HyperTable和MemcacheDB内部都使用了BerkeleyDB。
综上所述,我们可以看出:
1、大部分数据库产品都是都是近亲结婚,由少数数据库引擎(如ISAM、PostgreSQL、BerkeleyDB等)发展而来。(但是oracle和sqlserver的数据库引擎是内置的,鲜有人知)
2、你会惊奇的发现,MyISAM、BerkeleyDB、InnoDB等大部分数据库引擎的vendor都是oracle,oracle公司一直处心积虑的收购着市场上有竞争力的数据库引擎,用来捍卫自己的垄断地位,
3、几乎所有的数据库引擎都是GPL协议,擅自闭源用于商业将承担法律责任。
因此,要写一个数据库,首先要从实现数据库引擎入手,掌握数据库引擎技术有重要意义,因为无论是“关系数据库还是K/V数据库,SQL数据库还是NOSQL数据库,分布式数据库还是并行数据库,列数据库还是对象数据库...”,存储引擎部分都有着相似的实现原理,掌握了数据库引擎技术后,只要公司愿意投资,就可以长足拓展到任何数据库领域,一切只是工作量问题,数据库引擎一经研发成功,就值得长期放养,哪怕是5年10年。同时对个人职业意义来说,对一个玩了一辈子软件技术的架构师,没有写过数据库是一种遗憾,就跟喜欢女优的工程师没有见过真人一样。
二、CoolHash是个什么样的数据库
1、CoolHash是一个数据库引擎
CoolHash只做数据库最基础核心的引擎部分,支持大部分数据类型的“插入、获取、更新、删除、批量插入、批量获取、批量更新、批量删除、高效查询(精确查、模糊查、按树节点查、按key查、按value查)、分页,排序、and操作、or操作、事务处理、key指针插入和查询、缓存持久互转”等操作和远程操作。
其他的“监控、管理、安全、备份、命令行操作、运维工具”等外围特性都剥离出去不做,开发者可以根据自己需求扩充这些功能,CoolHash也不做自动扩容,CoolHash认为分布式集群特性也可以在外围通过“分库分表”或者“分布式扩容”等中间件技术去做,目前国内很多企业都具备基于开源软件做外围中间件的能力,这样,CoolHash只维持一个高性能又轻量级的最小存储引擎。
CoolHash高度产品化,易用性强,容易嵌入使用和复制传播(200k大小),采用apache2.0开源协议,使用java实现(jdk1.7),对外提供java接口,同时支持windows和linux(unix-like),由于依赖底层操作系统,windows和linux的实现稍有不同。
2、CoolHash是一个k/v数据库
实现数据库存储结构索引有多种方法,有比较平衡减少深入的b树、b+树系列,结合内存再合并的LSM-tree系列(bigTable),借鉴字典索引技术的Trie树(前缀树、三叉树)等,不过对于key/value结构,感觉最合适的还是Hash,不过java里的Hash算法是实现在内存组件里,无法持久化,只能快速读写,但是无法模糊查询,传统的Hash不是一个“cool”的Hash,需要进行改进。
CoolHash改进后的Hash算法是一个完整的key树结构,我们知道传统Hash的key和key之间没有关系,互相独立,但是在CoolHash里,key可以表示为“user.001.name”的用“.”分开的树层次结构,如“user.001.age”和“user.001.name”都属于“user.001.*”分支,既可独立获取,也可以从父节点查询,还可以“user.*.name”方式只查询所有子节点。
提出key指针的概念:CoolHash的key可以是一个指针,指向其他树的key,这样能将两棵key树连起来,这样的设计能避免大量join操作,如果两棵key树没有直接关系,需要动态join将会非常耗时,但有了key指针可以很好的描述数据之间“1对1、1对多、多对多”的关联关系。key指针也不同于数据库外健,它可以模糊指,比如只模糊指向一个key前缀“user.001”,再补充需要获取的属性形成一个完整key;还能连续指,比如一个key指针指向另一个key指针再指向其他key指针,连续指可以将更多的树联系起来形成一个大的数据森林。CoolHash能很好的控制key指针最终值返回、key指针死循环、读写死锁等问题。
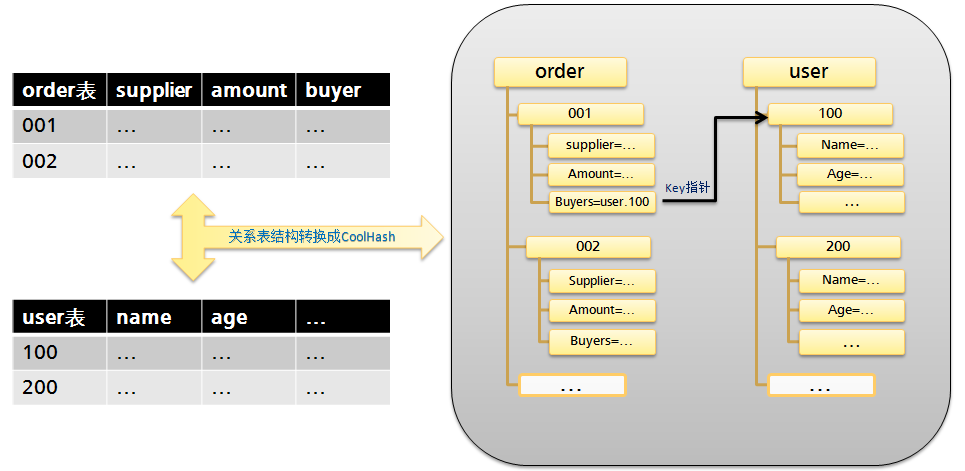
我们知道关系数据库的数据表是一个行列的二维矩阵的数据结构,表和表之间没有层次感,一个表不会是另一个表的父子节点,这就导致需要大量关联,从一个表获取另一个表的数据需要通过join操作,同时由于表和表之间彼此独立,又导致数据量大后join性能不好,多个矩阵需要动态的“求并”“求或”获取主健,再返回所有属性。很多朋友是开发业务系统出身,复杂一点的业务逻辑通常需要关联7-8个数据库表甚至更多,是相当头疼的事情。
这种矩阵行列式结构还有个不好,就是一加全加,一减全减,一行加了一列属性,所有行都要跟着加,假如有个“子女”属性,有的人有1个子女,有的人有2-3个子女,这个属性应该有时是1列,有时是3列,有时没有才好。CoolHash的父节点下的key值可以任意添加和减少,或者再任意向下扩充叶子结点,也可以任意查询,能够非常灵活,比如“子女”属性可以这样表示第一个小孩:“user.001.children.001”。
关系数据库还容易产生数据碎片,需要经常执行“OPTIMIZE TABLE”或者“压缩数据库”等操作回收空间,CoolHash对此做了设计和算法改进,对于大量数据频繁写入和删除能很好重复利用存储空间。
key和value的数据格式:CoolHash的key只能是字符串,默认最大长度为256字节。value能支持非常广泛的数据类型,基本数据类型“String(变长字符)、short(短整形)、int(整型)、long(长整形)、 double(双精度浮点型)、 float(浮点型)、Date(日期型)”,高级数据类型的大部分的java集合都能支持(List、Map、Set等),以及任意可序列化的自定义java类型,底层数据类型也可以支持二进制型。基本数据类型的value可支持按内容查询,高级数据类型和二进制类型不支持按内容查询。所有类型的value默认最大长度为2M,默认配置保证一对key/value长度不会太大,能够容易加载到内存进行处理,但是key和value的最大长度、以及region大小都是可以根据计算机性能进行配置。
CoolHash还支持HashMap缓存和持久化的统一和互相转换,并共用一套API,可以将数据放入CoolHashMap,也可以放入持久化,可以将CoolHashMap对象转成持久化,也可以从持久化数据里直接获取CoolHashMap对象。
3、CoolHash是一个并行数据库(mpp)
前几年有篇文章,国外的数据库大牛猛烈抨击map/reduce,让重复造轮子的人应该去学习一下关系数据库几十年的理论和实践积累,一个借助蛮力而不善于设计索引的数据库系统是愚蠢和低效的。这一方面说明了map/reduce技术已经侵犯到了传统数据库领域的核心利益,另一方面也暴露了分布式存储技术的某些不足。
这里的蛮力就是并行计算,在CoolHash的底层,会维持一个数据工人进程组,根据计算机性能少则几个多则上百个,对于数据库的每种操作,数据工人们像演奏交响乐一样,时而独奏,时而合奏,统一调度,紧密协作的完成任务,CoolHash从一开始就是高度并行化的设计,数据库引擎本质就是在寻求cpu、内存、硬盘的充分利用和均衡利用,“一力胜十巧”,在大量数据的读写和查询中并行计算的效果犹为明显。
同时一个好的数据库引擎应该是蛮力和技巧的结合,Hbase的一个重要启示,就是可以灵活设计它的key达到近似索引的效果,CoolHash将此特性发挥的更深入,树型结构的key本身就是最好的索引,除外CoolHash几乎不需要另外再建立索引,只需要按照业务数据特点设计好你的key。并行计算和索引的结合会得到一个很好的互补,让你的索引结构不需要维持的太精准而节省开销,举个例子:我们从一个城市找一个人,一种方法是我们有精确的索引,知道他在哪个区哪个楼那个房间,另一种是我们只大致知道他在哪栋楼,但是我们有几百个工人可以每间房同时去找,这样也能很快找到。
4、CoolHash是一个nosql数据库
nosql不等于没有sql的功能,关系数据库的sql仍然是非常方便的交互语言,而且有专门的标准,CoolHash通过函数方式实现大部分sql的功能,如果需要扩充sql支持,在外围用正则表达式做一个sql解析,然后调用CoolHash的函数支持即可。
由于CoolHash没有关系数据库的“db、table、row、col”等概念,使用树型key取代了,所以sql create语句功能就不需要了。
“put()函数”对应于“sql insert、update”语句
“remove()函数”对应于“sql delete...where”语句
“put(map)函数”对应于“sql insert/update into...select...”语句
“get()函数”对应于“sql select...where id=?”语句
“get(map)”函数对应于“sql select *...”语句
“find(*,filter)”函数对于于“sql select * where col=%x%”语句
“and()函数”对应于“sql and”语句
“or()函数”对应于“sql or”语句
“sort(comp)函数”对应于“sql desc/group”语句
5、CoolHash实现了事务处理
CoolHash实现了ACID事务属性,对写入、更新、删除的基本操作提供事务处理,在程序里调用begin()、commit()、rollback()等事务方法。
原子性(Atomic):事务内操作要么提交全部生效,要么回滚全部撤消。
一致性(Consistent):事务操作前后的数据状态保持一致,一致性跟原子性密切相关,比如银行转账前后,两个账户累加总和保持一致。
隔离性(Isolated):多个事务操作时,互相不能有影响,保持隔离。
持续性(Durable) :事务提交后需要持久化生效。
另外,对于多个事务并发操作数据的情况,JDBC规范归纳出“脏读(dirty read)、不可重复读(non-repeatable read) 、幻读(phantom read) ”三种问题,并提出了4种事务隔离级让软件制造商去实现,按照不同等级去容忍这三个问题,其实这种逐级容忍大部分都不实用,一个事务操作未提交时,按照事务隔离级,其他访问应该是读取到该事务开始前的数据,而不应该把事情搞复杂,CoolHash实现的是“TRANSACTION_SERIALIZABLE”,禁止容忍三种读取问题。
6、CoolHash是一个数据库Server
CoolHash支持远程网络访问,服务端发布一个IP和监听端口,客户端连接该IP端口即可进行远程操作,CoolHash可承受多用户高并发的网络连接访问,来源于服务端设计的相似之处,大家知道Apache HTTP Server是一个多进程模型+共享内存方式实现,在前面讲到的CoolHash会维持一个数据工人的进程组,数据工人不仅是并行计算的执行者,同时也是网络请求的响应者,数据工人身兼多职能很好的将服务端设计统一起来,避免重复设计,因此CoolHash也是一个很好的网络Server.
7、CoolHash的测试性能
有句话叫做“人生如白驹过隙”,用来形容性能就是一瞬间,数据库性能最好能接近缓存,或者直接可以当作缓存来用,能在瞬间完成读写和各种查询,这个瞬间就是秒。只有在几秒内完成操作才能做到实时交互没有等待感,否则就要离线交互。
CoolHash的单条写入和读取速度都在毫秒级别,写和读差别不大,读略快于写。
CoolHash的批量写入和读取速度都控制在秒级别,100万数据写入基准测试,普通台式机或者笔记本(4核4g)需要5-6秒,标准pc server(24核256g)需要2-3秒;批量读、批量删除和批量写入的速度差不多。
CoolHash写入缓存和写入持久的速度差别不大,100万数据写入缓存基准测试,普通台式机或者笔记本(4核4g)需要5秒左右,标准pc server(24核256g)需要2秒左右。如果是10万级别的数据读写,缓存和持久的速度大致接近等同。
CoolHash的查询速度控制在秒级别,100万数据的模糊查询(如like%str%)在没有构建索引情况下,普通台式机或者笔记本(4核4g)需要2-3秒,标准pc server(24核256g)需要1-2秒;如果是重复查询,由于CoolHash内部做了数据内存映射,第二次以后只需要毫秒级完成。
高并发多客户端的吞吐量总体速度要快于单客户端,但是受服务器cpu、内存、io等性能限制,会倾向于一个平衡值。
数据库引擎的性能通常也会受“key/value数据大小、数据类型、工人数量、硬件配置(内存大小、cpu核数、硬盘io、网络耗用)”等等因素影响。
比如同样数量但是单条key/value数据很大,整体速度要慢一些;
基本数据类型的读写速度要快过高级数据类型(如java集合类);
工人数量也有影响,对于单条写入读取单工人和多工人差不多,但是批量操作和查询多工人要好过单工人,普通台式机或者笔记本(4核4g)维持在8-10个工人可以打满cpu,标准pc server(24核256g)最大可以维持到100个左右工人,但是工人数量就算能打满cpu,也受限于后端硬盘io,到一定程度速度不再增长;
硬件配置对于性能的影响很大,普通笔记本的测试效果明显不如标准pc server,笔记本内存较小,硬盘io弱,不适合做数据库服务器。内存大的服务器测试效果好,加载数据和jvm垃圾回收速度会更快,目前测试采用的都是传统SAS/SATA硬盘,如果采用固态硬盘进行硬件升级,随机IO性能会得到进一步提升;
另外,由于存在网络耗用和序列化传送,远程网络操作的速度要比本地速度慢,但是局域网内速度会接近本地速度,这是因为远程网络操作涉及带宽接入限制和线路共享等复杂消耗,而局域网内主要取决于物理设备速度。
关于CoolHash性能的更多体验,欢迎有兴趣的朋友根据demo在各自的机器环境下,模拟各种极端条件下去压测。
三、如何使用CoolHash
ch追求极简的编程体验,不需要安排配置,服务端启动CoolHashServer,指定好ip和端口,
客户端大致编程步骤如下:
CoolHashClient chc = BeanContext.getCoolHashClient("localhost",2014);//连接CoolHashServer
chc.put("user.001.name","zhang");//写入字符
chc.put("user.001.age",20);//写入整数
chc.put("user.001.weight",50.55f);//写入浮点数
chc.put("user.001.pet",new ArrayList());//写入集合对象
String name = (String)chc.get("user.001.name");//读取字符
int age = (int)chc.get("user.001.age");//读取整数
float weight = (float)chc.get("user.001.weight");//读取浮点数
ArrayList pet = (ArrayList)chc.get("user.001.pet");//读取集合对象
chc.put("user.002.name","Li");
chc.put("user.002.age",25);
chc.put("user.002.weight",60.55f);
CoolKeyResult keyresult = chc.findKey("user.001.*");//查找用户001的所有属性
CoolKeySet ks = keyresult.nextBatchKey(4);//分页获取前4条结果
System.out.println(ks);//输出[user.001.weight, user.001.age, user.001.name, user.001.pet]
CoolHashResult mapresult = chc.find("user.*.age", ValueFilter.greater(18));//查找年龄大于18岁的用户
CoolHashMap hm = mapresult.nextBatch(10);
System.out.println(hm);//输出[user.001.age=20, user.002.age=25]
......
更多的功能使用请去参考开发包里的demo
四、Fourinone到底是什么?
Fourinone1.0是一个并行计算框架,2.0是一个分布式文件系统(Fttp),4.0是一个数据库引擎(CoolHash)...那么Fourinone到底是什么?
我们把Fourinone打开,其实就是纯java程序,除外什么都没有,通篇展示如何用最基础的java实现上面的功能。
其实不用关注Fourinone的产品定位究竟是什么,Fourinone就是四不象,虽然功能众多,跨度很大,但是仍然长自同一个身体,由同一个脑袋指挥,只要各项机理运行正常健康就好。
Fourinone就是俄罗斯套娃里最小的一个,2.0是1.0的应用,3.0是2.0的应用,4.0是3.0的应用,层层扩充没有止境,体现软件搭建精髓思想。
Fourinone只收集最核心的技术,hadoop的开发者去使用spark需要重新学习,反之亦然,因为他永远只是一个使用者,但是Fourinone可以从一个简单MQ演变成一个复杂数据库,只有掌握核心技术,才具备强大的变通能力。
Fourinone4.0虽然新增加了一个完整的数据库引擎,但是依然保持着苗条身材,整体大小只有220k,用不到1万行java代码实现,所有的设计都是原创和创新。
除外,4.0版本还增加了以下特性:
1、多进程多线程的无缝融合,同一套接口,改改参数,从多进程变为多线程,开发者无需改写程序逻辑;
2、提供高容错任务分配算法API:doTaskCompete(m工人,n任务),将n个任务分给m个工人并行完成,根据任务大小设置工人数量,工人间能者多劳,性能好的工人机器争抢干更多的任务,同时跟现实工作一样,如果有工人生病请假(故障),那么他的任务活由其余工人代干,除非所有工人出故障,否则就算只剩一个工人也应该加班把其他所有工人的活干完,对整体计算来说,部分工人故障对计算结果来说不受影响,只是计算时间会延长。
五、结束语:将技术做酷是一种生活态度
就像摇滚乐手骑行哈雷是一种生活态度一样,把技术和产品做酷也是一种生活态度。
用很多代码体积臃肿实现出来也可以,但是不够酷,用很少代码实现功能更强才酷;
用很多人花很多时间做出一个产品也可以,但是不够酷,用很少人花很少时间做出来才酷;
全靠整合依赖太多也可以,但是不够酷,没有任何依赖才酷;
最核心的组件都是用别人的也可以,但是不够酷,自己做的更好才酷;
产品只有专业人士会用也可以,但是不够酷,没文化的人都会用才酷;
跳水自由落水也可以,但是不够酷,翻几个跟头不冒一点水花才酷;
演死尸直接倒下也可以,但是不够酷,多晃悠几下再死才酷;
不玩创新也可以,那样的人生不够酷,玩创新挨整才酷。
基础软件也能像互联网产品余额宝、微信那样做到很酷,追求傻瓜式的客户体验和黏性,把草根程序员当做客户群体,做他们踮踮脚就能够的到的软件。基础软件相对于业务创新产品来说有一定技术门槛,不容易被复制,观察我们身边的互联网产品,“从网游到偷菜到手游到微博到微信...”或者是“从b2b到c2c到b2c到团购到o2o...”总在不断的进行业务模式创新,保鲜期不超过2年,而且容易遭到山寨,但是微软的操作系统和office、oracle的数据库卖了20多年,不需要什么创新好像也没有竞争对手。
很多毕业生踏入这个行业时最初的梦想也是想写一个很酷的操作系统或者数据库,但是无数次的现实磨灭了他的梦想,很多人最后变成一个在职场政治和项目扯皮中寻求着人生价值,并且总是把“技术不是问题”挂在嘴边,是否还记的你曾经的梦想,把技术做酷。
Fourinone4.0(CoolHash)开源地址:http://code.google.com/p/fourinone/
svn地址(浏览器可以直接下载):http://fourinone.googlecode.com/svn/trunk/
关于Fourinone的所有架构、指南、demo,可以参考《大规模分布式系统架构与设计实战》一书











