
我也不想标题党,可它们就是好萌啊!看看下面这些你认识多少?
我是憨憨,一个不会画画的设计师。过去半年里,AI绘画曾经多次引爆公众讨论,网络上那些精致的二次元同人插画、堪比真人的AI穿搭博主、打破次元壁的赛博Coser……背后都有一个“幕后黑手” —— Stable Diffusion,其背后的技术便是人们常说的扩散模型(扩散模型这个概念源自热力学,在图像生成问题中得以应用)。
想知道上面这些精致的插画是如何实现的吗?接下来,我将结合这个案例带你走进 Stable Diffusion 的世界,帮你系统性地了解并掌握这神奇AI绘画魔法。


虽然我们把这个过程称之为AI绘画,但实际上它并不是像人类画图一样打草稿、构线描边,再去上色、对细节加工……这样按部就班地去完成一幅画作的,它采取了一个人类不曾设想的路径 —— Diffusion(扩散)。
一、Diffusion:眼一闭一睁,一张图画好了
有一个非常形象的方式,来解释 Diffusion 的原理。
这是我家的傻狗,你可以将自己的角色带入到执行绘画指令的AI中,现在让你把这幅画用宫崎骏风格重新绘制一遍,你做得到吗?你可以尝试着把眼睛眯成一条缝去看它(如果你近视可以摘掉自己的眼镜),它是不是变得模糊了?保持这个状态,想象着它正在逐渐变成动漫里的样子,随后慢慢睁开眼睛……

这就是一个扩散模型工作的基本流程了。
在这个过程中,AI会将图片通过增加噪声的方式进行“扩散”,使它变得模糊,就像是眯起眼睛的你一样,当内容模糊了以后,你就有更充分的空间去从它原本的形态抽离,并且想象它是否能变成其他模样。AI通过深度学习的方式,将很多不同的图像都转换成了这样的抽象内容,并逐渐开始理解了这个“扩散”的过程,每学一张图,它就会通过一些方式提取图像里的信息特征,并和它的原图建立关联。
在刚才的例子中,当提到宫崎骏风格的时候,你的脑海里肯定也会跳出跟这类作品相关的风格特质来,因为你看过并且记得,这个时候,我们开始去想象它变成动画片里的样子,并且用一个动漫的方式“睁开眼睛”,让图片恢复清晰,这就是在对图像进行逆向的扩散,也就是去噪。这幅画,就已经被你脑海里关于宫崎骏的想象重新绘制一遍了。

这一原理,为我们在AI绘画中的操作提供了理论基础和指导思想。当然,这只是一个简单的比喻,在真实的AI图像生成过程中要远复杂得多,我们只需要知道,在SD里面我们能接触到的各种提示词、模型、controlNet 等,其实控制的都只是AI的学习、转化、去噪过程,而非它一笔一画的动作。
二、一副AI绘画作品 = 提示词 + 参数设置 + 模型
这是 Stable Diffusion webUI,我们所有的操作都是在这里完成的。webUI其实只是一个执行的程序,用来屏蔽掉 Stable Diffusion 复杂的模型和代码操作。当你在浏览器里打开了这个webUI以后,就可以利用它开始作画了。
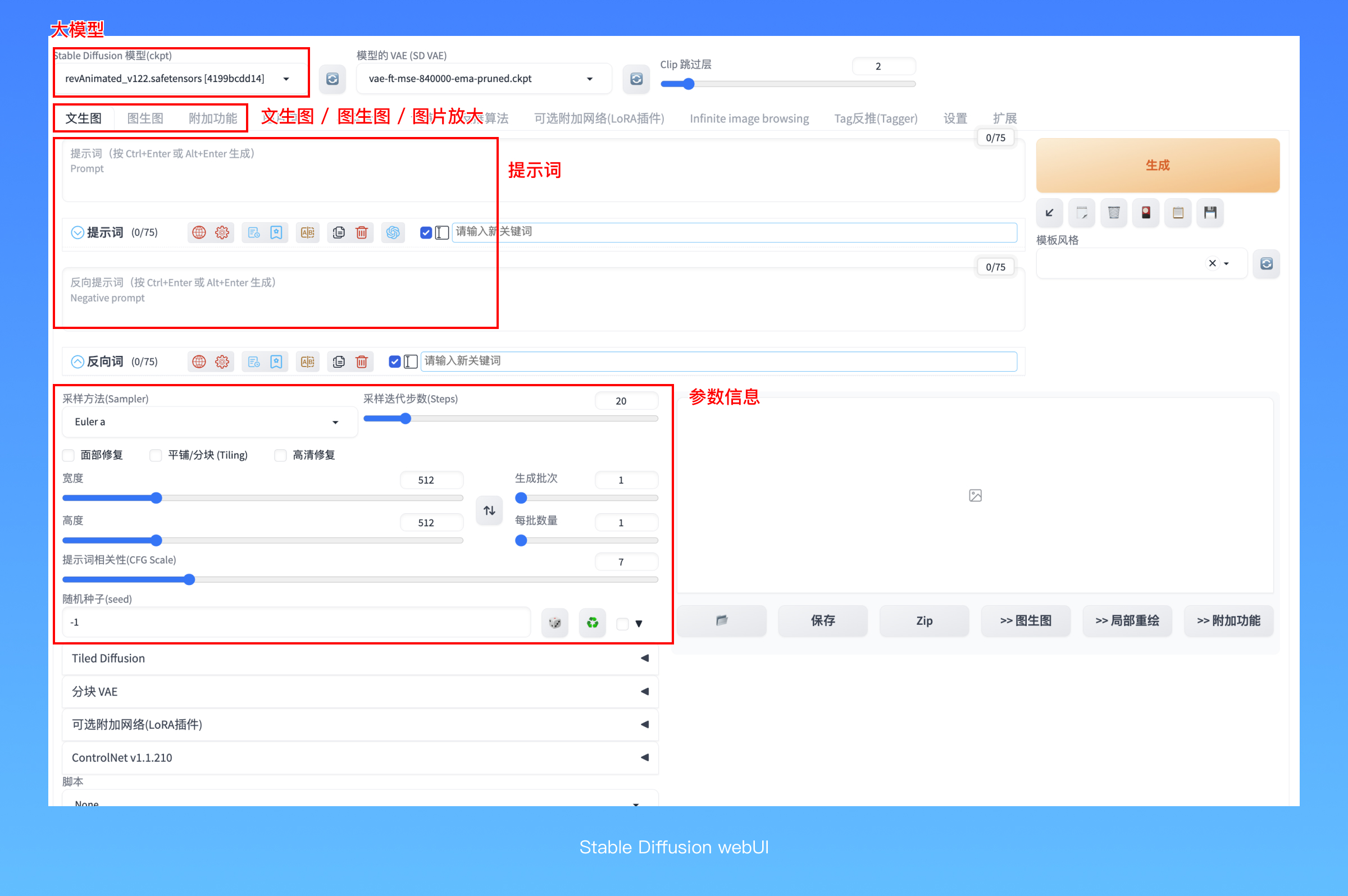
WebUI 上面一整排标签栏对应了不同的功能,做图最常用的是前两个:文生图与图生图,它代表的是两种绘制的基本方式,第三个标签的更多主要用于对图片进行AI放大处理,它可以让你生成更清晰的大图。
看过《哈利波特》的影迷一定会记得,在霍格沃滋的魔法世界里,一个魔咒想要成功施展,不仅需要集中精神念对咒语,还需要一根魔杖,以及正确地挥动魔杖的手势,任何一个步骤出现错误,都有可能导致魔咒发动的失败,极端情况甚至会被反噬,在AI绘画的魔法世界里也是类似。

1、提示词:指挥AI作图的咒语
WebUI 中被我们输入进去的描述文字或图像信息,就是 Prompts (提示词):用于生成图像的文字输入,需要使用英文输入,但你也可以通过探索 Extensions 来实现中文输入。提示词的涵盖范围很广,可以包括:主体、风格、颜色、质感特点等一些具体要素。
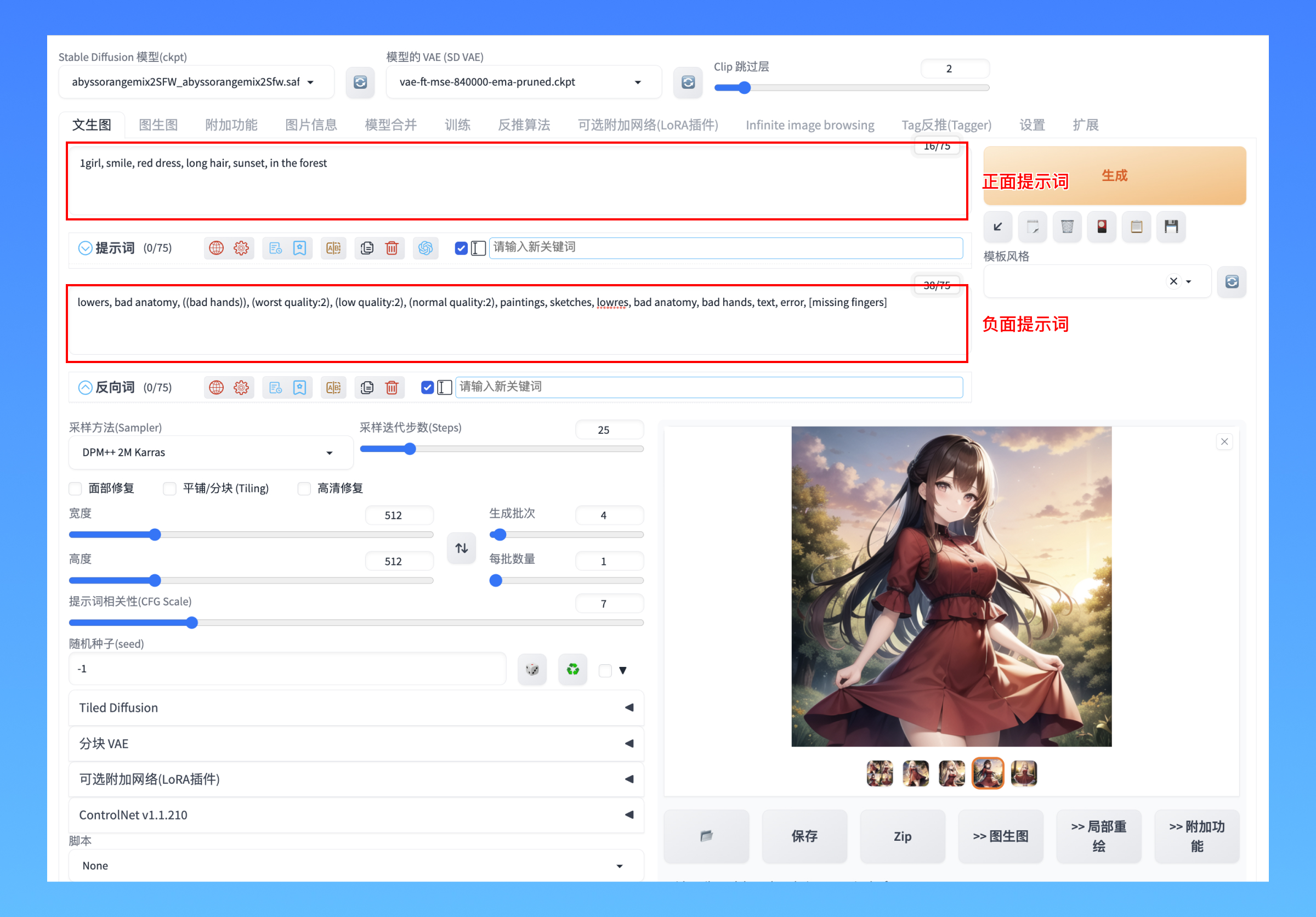
提示词分成两部分,一部分是正向的提示词,另一部分是反向提示词,分别用来控制你想要在画面里出现的、想排除在外的内容。
AI 生成出来的东西是具有随机性的,每次生成出来的东西都会不太一样,这个过程就像是在“抽卡”:想出好的图片,得靠运气来抽。 比如:一个女孩在林中漫步,这其实只是一个非常概括的描述,这个女孩长什么样子、森林里有什么、时间是早上还是晚上、天气如何……这些AI都不知道,提示词太过于笼统,那AI就只能瞎蒙、抽卡了。我们可以把自己想象成一个无情的甲方,向AI沟通你的需求、AI需要改进的地方。我们对AI提的要求其实就是提示词 Prompts ,如果AI没有达到想要的效果,就不断补充、说明,多试几次总有一次可以抽到想要的效果~
虽说AI是人工智能,但它和人类智慧还是有一定差距的,有时候你会发现即使提示词已经给了很多,自己依然很难向AI表达清楚自己的需求。其实在现实生活里,这种对于需求的传递偏差与错误解读其实也普遍存在着,比如:总是干架的产品经理和程序员、甲方客户与设计师。拿我熟悉的设计举例,假如你是需求方,除了不断对着设计师一遍又一遍的咆哮需求以外,还有什么办法让他快速开窍呢?

你可以拿着一张海报或者banner,告诉设计师我想要的感觉是这样的,那他就会更直观、具体的感受到你的想法。AI绘画也是一样,当你觉得提示词不足以表达你的想法,或者希望以一个更为简单清晰的方式传递一些要求的时候,那就再丢一张图片给他就好了。此时,图片的作用和文字是相当的,就是都作为一种信息输送到AI那里,让它拿来生成一张新的图片,这就是图生图。
2、参数设置:控制咒语施放的魔杖
这部分内容介绍一下在AI绘画过程中,webUI里面这些复杂的参数设置。
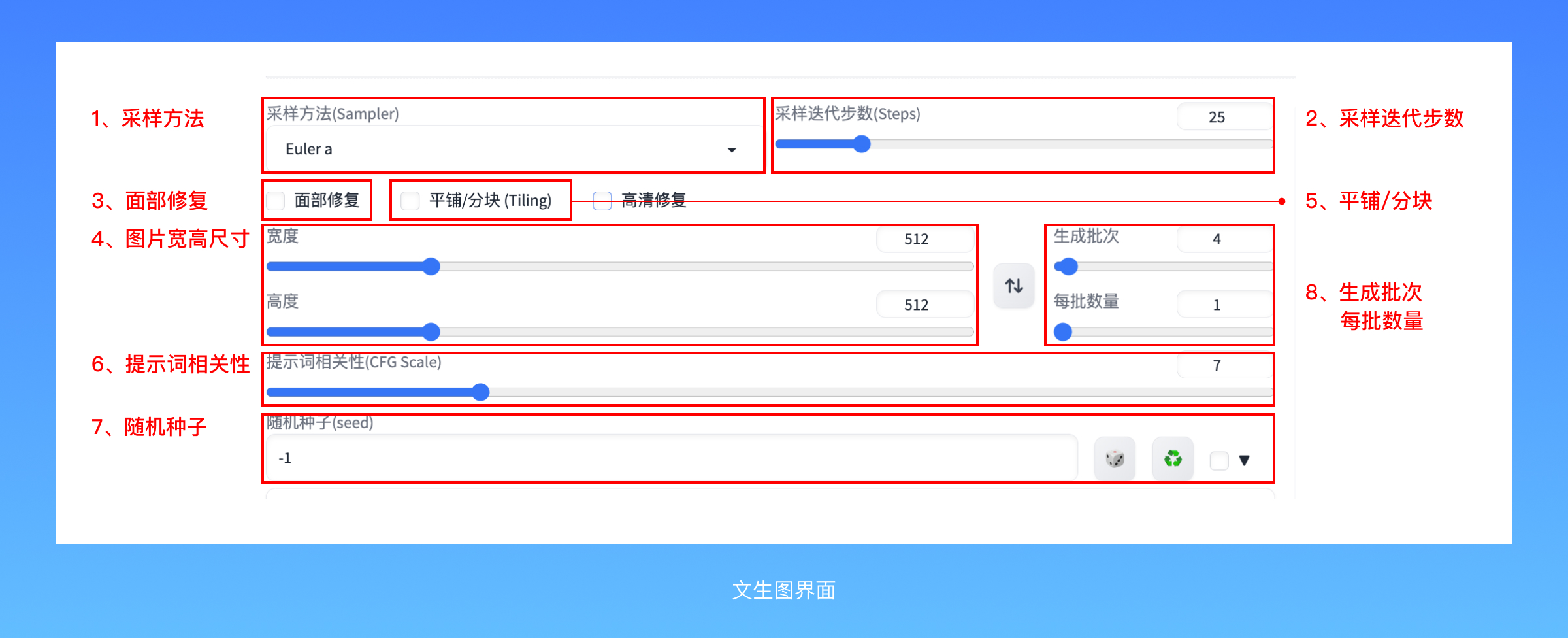
(1)采样算法(Sampler) 简单来说,通过这些采样算法,噪声图像可以逐渐变得更清晰。webUI提供的算法选项非常多,包括 Euler a、DPM、DDIM 等。我分享几个我们经常会用到的:
•想使用快速、新颖且质量不错的算法,可以尝试 DPM++ 2M Karras,设置 20~30 步;
•想要高质量的图像,那么可以考虑使用 DPM++ SDE Karras,设置 1015 步(计算较慢的采样器)、或者使用 DDIM 求解器,设置 1015 步;
•喜欢稳定、可重现的图像,请避免使用任何原始采样器(SDE 类采样器);
•Euler、Euler a 比较适合插画风格,出图比较朴素;
(2)采样迭代步数(Steps) 与采样算法配合使用,表示生成图像的步数。步数越大,需要等待的时间越长。通常 20-30 步就足够了。默认的采样步数一般都是20。如果你的算力充足且想追求更高的细致度,就设置为30-40,最低不要低于10,不然你可能会被你自己产出的作品吓到。
(3)面部修复 在画人物的时候需要勾选上,他可以改善细节、纠正不准确的特征,让生成的人脸显得更加自然和美观,类似美图秀秀的一键美颜。
(4)宽度 & 高度 生成图像的宽度和高度分辨率。默认的分辨率是 512 x 512, 但这个分辨率下的图片,哪怕是细节再丰富,看起来也很模糊,所以设备允许的情况下,我们一般把它提到1000左右。相同的提示词用更高的分辨率跑出来,质感完全都不一样。当然,分辨率设置的太高也会有问题,显卡显存扛不住,出现 “CUDA out of memory”的提示。为了让我的AI绘画有强悍的性能,保证我的出图效率和体验,我使用了京东云GPU云主机,它拥有超强的并行计算能力,在深度学习、科学计算、图形图像处理、视频编解码等场景广泛使用,可以提供触手可得的算力,有效缓解计算压力,让我在高清出图时不再有“爆显存”的烦恼。
(5)平铺/分块(Tiling)用来生成无缝贴满整个屏幕的、纹理性图片的,如果没有需要慎重勾选哦,它会让你的画面变得很奇怪。
(6)提示词相关性(SFG Scale)CFG Scale 的范围是 1-30,默认值为 7。我们可以通过调整不同的 Scale 值来观察图像的变化。它的数值越高,AI绘画忠实地反应你提示词的程度就越高,7~12之间是比较安全的数值,数值太高则容易引起图片变形。
(7)随机种子(Seed)生成图像的随机种子,类似于抽奖的幸运种子,会影响生成的图像结果,是我们用来控制画面内容一致性的重要参数。如果我们想要画面保持一样的风格,就可以使用同一个随机种子。在这个随机种子里面,有2个功能按钮,点击右侧的骰子,可以把随机参数设置成-1,每一次都抽一张新的卡;点击中间的循环按钮,就会把种子设置成上一张图片抽出来的数字。
(8)生成批次、每批数量 每批、每次次生成的图像数量,如果显存不够大,建议调小数值。因为AI绘画的不确定性,即使是同一组提示词,也需要反复试验。这个试验过程有时候会很漫长,如果你想让AI一直不断地按照同一组提示词和参数出图,可以尝试批次数调高,绘制的过程则会不断重复地进行。所以完全可以让它一口气来上个几十次甚至上百次,自己去吃个饭、睡一觉,让显卡默默地在这里打黑工。增大 [每批数量] 可以让每批次绘制的图像数量增多,理论上效率会更高,但它同一批绘制的方法是:把这些图片拼在一起看作一张更大的图片,所以如果你的设备不好,非常容易爆显存。
🎉🎉感谢认真的你已经阅读完4218个字了,如果读到了这里,说明你对这类话题感兴趣,也对我的科普比较认可,文末有 交流群 可以加入🎉🎉
3、模型:要施展的魔法种类
AI之所以能满足你的各种奇奇怪怪的需求,其实来源于它对很多其他画作的深度学习,我们把拿图片给AI学的这个过程,叫做喂图。学习的内容不仅包括对具体事物的形象描绘,还包括对他们的呈现方式,说通俗一点,就是“画风”。如果我们喂给AI的图片都是二次元风格的,那他的世界就是二次元的;如果你喂给AI的图片都是真实世界里的照片,那它就画不出“画”来。我们“喂”给AI图片以及AI学习的这个过程,会被打包、整合到一个文件里面,他们就是AI绘画中的“模型”:使用不同风格的模型,就能做出不同风格的作品。
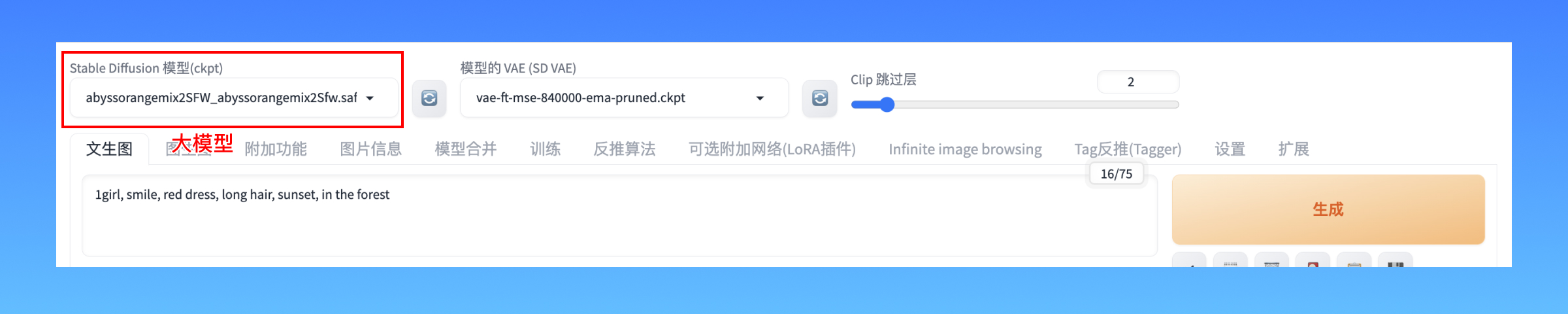
大模型: 在webUI左上角的内容就是我们常说的大模型,也叫做基础模型,比如sd-v1.5.ckpt,sd官方自带的基础模型。这类模型都是由dreambooth技术,经过大量数据训练,可以生成各类常见元素的图片,一个全能工具,不可缺少,否则sd不能启动,文中的很多图片来自不同的大模型,感兴趣的可以留言或者文末加入我们的交流群一起讨论。
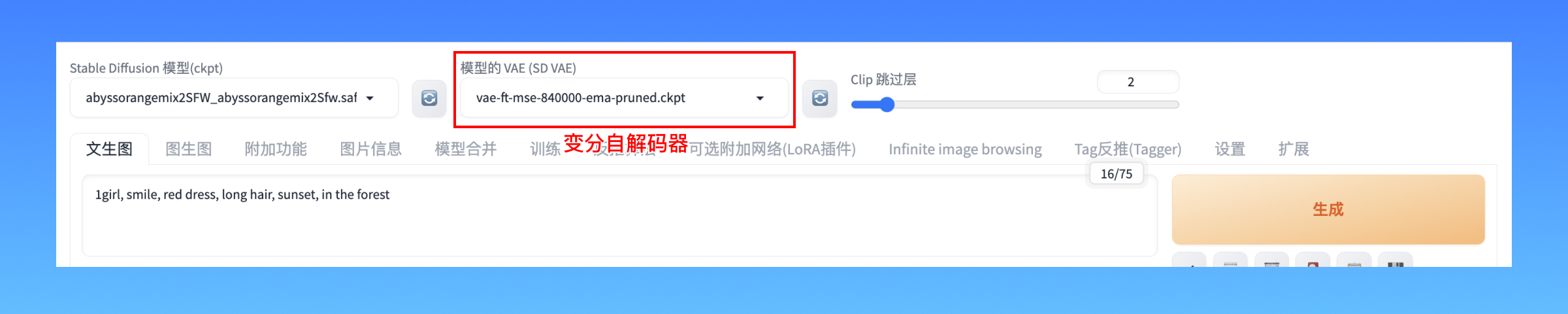
VAE模型:变分自解码器(Variational Auto Encoder),vae的作用是增强模型的色彩、光照等表现效果,相当于给模型加了美颜滤镜。所以如果你发现你的模型做的图发灰,检查一下vae文件是否勾选。目前多数比较新的模型,其实都已经把VAE整合进大模型文件里了,多数模型作者都会推荐他们认为合适的VAE,也有一些普遍适用于大多数模型的VAE,例如 kf-f8-anime。
下载渠道:一个是HuggingFace,它是一个允许用户共享AI学习模型和数据集的平台,包含的内容非常广,不仅有AI绘画,也包括很多其他AI领域的内容,因此呈现出了比较高的专业门槛;另一个是Civitai,俗称C站,它是一个专业的AI绘画模型分享平台,在这里看到的各种模型展示是非常图像化、具体化的,并且在C站浏览、下载模型均不需要注册。
实际上模型不止Checkpoint一种,接下来再为你介绍3种用来微调主模型的"小模型"。
(1)Lora 模型:最近最火爆的模型,最大的特点就是几乎图像上的信息它都可以训练,并且还原度非常高。现在网络上流行的很多Ai真人绘图软件基本都是用的Lora模型。Lora模型主要用于固定图片风格,因为这类模型具备容易训练、对电脑配置要求低等特点,因此使用Lora训练的人更多。
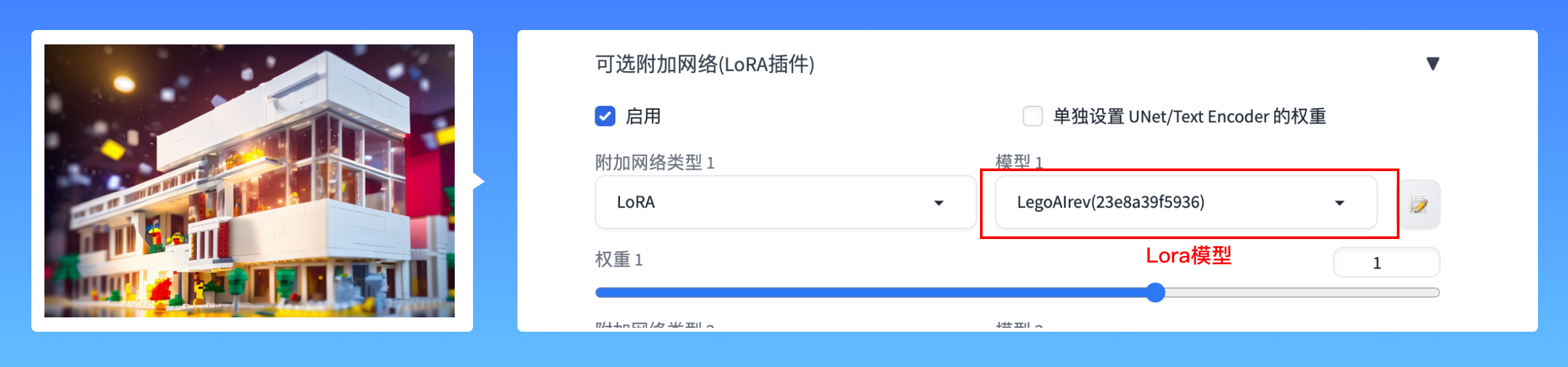
比如上面这张图,使用的lora模型是LegoAlrev,它可以让我们的总部大楼呈现出乐高积木的风格。
目前LoRa主要应用特点是各种游戏、动漫角色的二次创作构建,因为训练LoRa需要针对一个对象的各个方面的素材,如果是人物,那就需要不同姿势、不同表情、甚至是不同画风的东西,来帮助AI固定里面的特征。一些热门的ACG角色往往拥有充分的素材可供训练,出来的效果是非常不错的。
(2)Embeddings模型:又叫Textual Inversion模型,需要和主模型一起搭配使用,可以简单理解为提词打包模型,体积一般只有几十kb。可以生成特定角色的特征、风格或者画风。
如果说checkpoint是一本大字典,那Embeddings就像是字典里面的一片小书签,它能够精准的指向个别字、词的含义,从而提供一个极其高效的索引。这种索引方式,除了能帮AI更好地画好字典里已经有的东西以外,有时候也可以帮我们实现特定形象的呈现。比如:我们想让AI画一只“猫又”,字典里虽然没有直接记载猫又这种比较偏僻的概念,但它知道“猫”怎么画、知道“人”怎么画,也可能知道“妖怪”怎么画,那我们就在字典上记有这些概念的页面里,分别夹上一片醒目的书签,那AI一听到“猫又”,就直接翻到这几页,把里面的信息汇总到一起,就知道“猫又”是个什么东西了。

(3)Hypernetwork模型:同样需要搭配主模型一起使用,它最常用于画风、效果的转换,也可以用于生成指定的角色。相比 Embeddings 和 LoRa 来看,网上多数研究者对Hypernetwork在图像生成方面的评价并不好,并且它的作用其实是可以部分被LoRa取代的,现在也有不少优秀的LoRa通过对训练样本的把控实现了画风的塑造植入,我平时用的不多,所以这里就不过多介绍了。
三、高清放大-拒绝低质量的出图
在webUI里,有一系列功能是专门为乐优化产出图像质量,让我们获得更大、更高清的图片而存在的,例如高分辨率修复、Upscale脚本,以及附加功能中的图片放大算法,他们的本质都是把低分辨率的图片再拿去“图生图”一次,从而得到一张更大的图片。
在刚才的生成的图片中,它的画面看上去还挺精致,但因为分辨率低,导致了一些细节的缺失和混乱,这里我们使用 Upscale脚本来实现高清放大。

把它从图库浏览器加载至图生图,所有的生成参数会自动同步过来,为了取得和原图比较相似的效果,控制重绘幅度在0.4左右。在参数设置区域的最下方,有一个用于加载脚本的选项,选择放大脚本,缩放系数相当于放大倍数,放大算法决定了在将这个低分辨率的版本“打回重画”的时候AI如何操作。图块重叠的像素(Tile overlap)选择64,宽度和高度在原有基础上各加64,设置完成后点击生成就可以了。
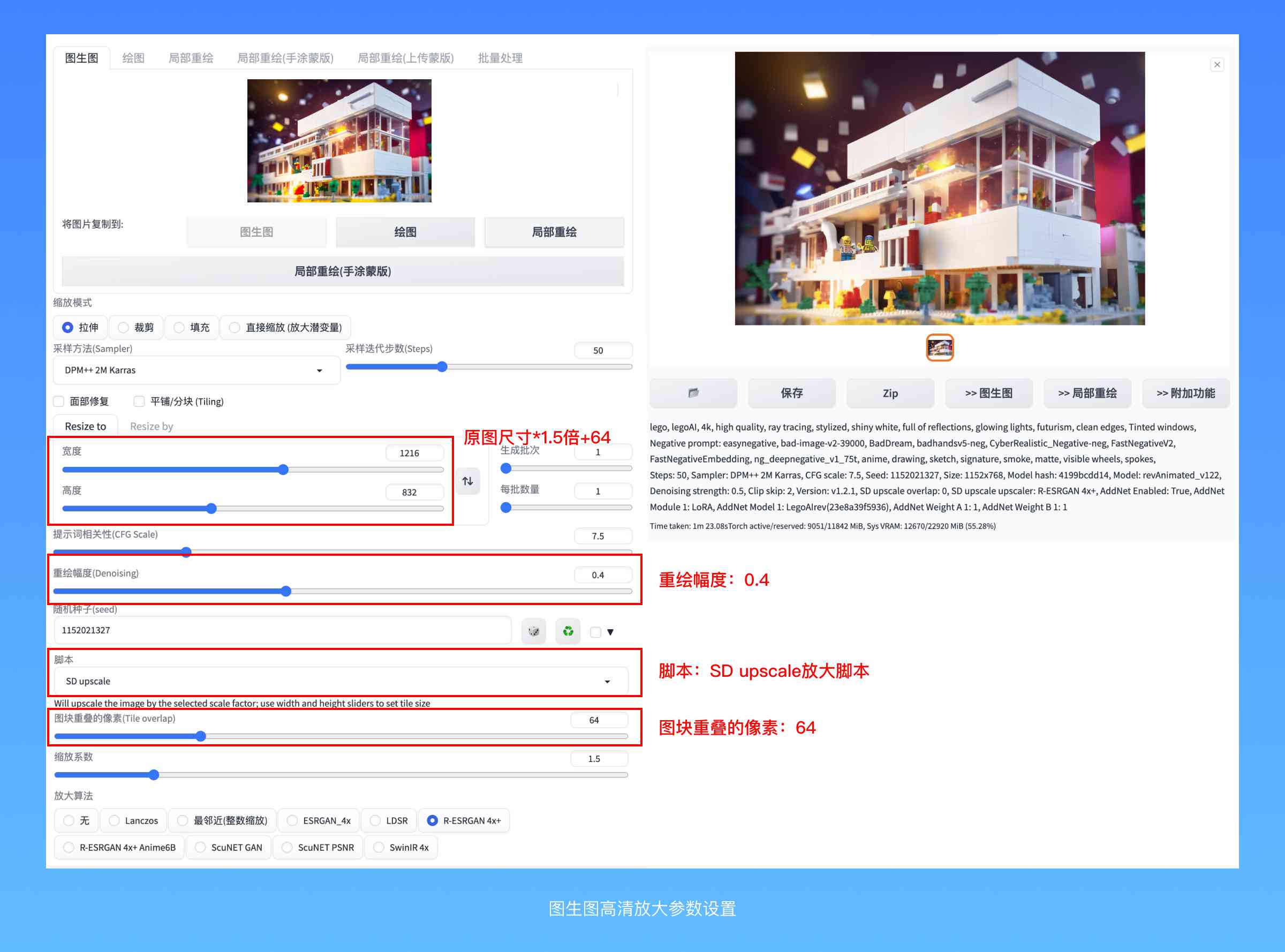
这个过程绘制方法很巧妙,它是通过把这张图均匀的切成4块去画的,画完以后再拼回到一起。如果只是机械地拼成4块,那相邻图块之间的接缝处肯定会出现非常生硬的过渡边缘,刚才设置的64像素重叠就是来解决这个问题的,它是一个缓冲带,可以让4块区域“拼合”的过程变得更加丝滑。

四、局部重绘-对画作的自由修改
扩散算法给图像生成带来了无限的可能性,却也有许多不可预估的问题,例如人物四肢的混乱、景观的错位等等。

我们抽取到一张盲盒风格的公司总部大楼,但是还想在这个基础上再做改进:草地上多一些花,我们可以借助关键词、并借助随机种子固定画面,但这样一定会碰到两个问题:首先,即使随机种子完全一致,当提示词发生变化时,这个新的随机过程也是相对不可控的,就可能会出现人换了姿势、画面大幅变化的情况;另一方面,如果图片已经经过了高清修复或者upscale放大,这意味着要重新画一张非常大的图,耗费时间就更长了。我们对这张图99%都是满意的,重画一张值得吗?我们试着把这1%单独拎出来处理一下,这时我们可以用局部重绘这个功能。
局部重绘就像我们写作业时使用的涂改液、修正带一样,它可以针对一张大图里的某一个区域覆盖重画,既能修正错误,又不至于把整张纸撕掉重画一遍。
将一张图拎出来进行局部重绘的方式有很多,最简单的就是在图库浏览器里直接点击右下角的局部重绘按钮,它会跳转到图生图,因为局部重绘属于图生图的一个下属分支功能。也可以通过图片区域上方的标签切换到局部重绘(inPaint),在这里除了可以加载用AI画出来的图以外,还可以使用电脑上的其他素材图片。
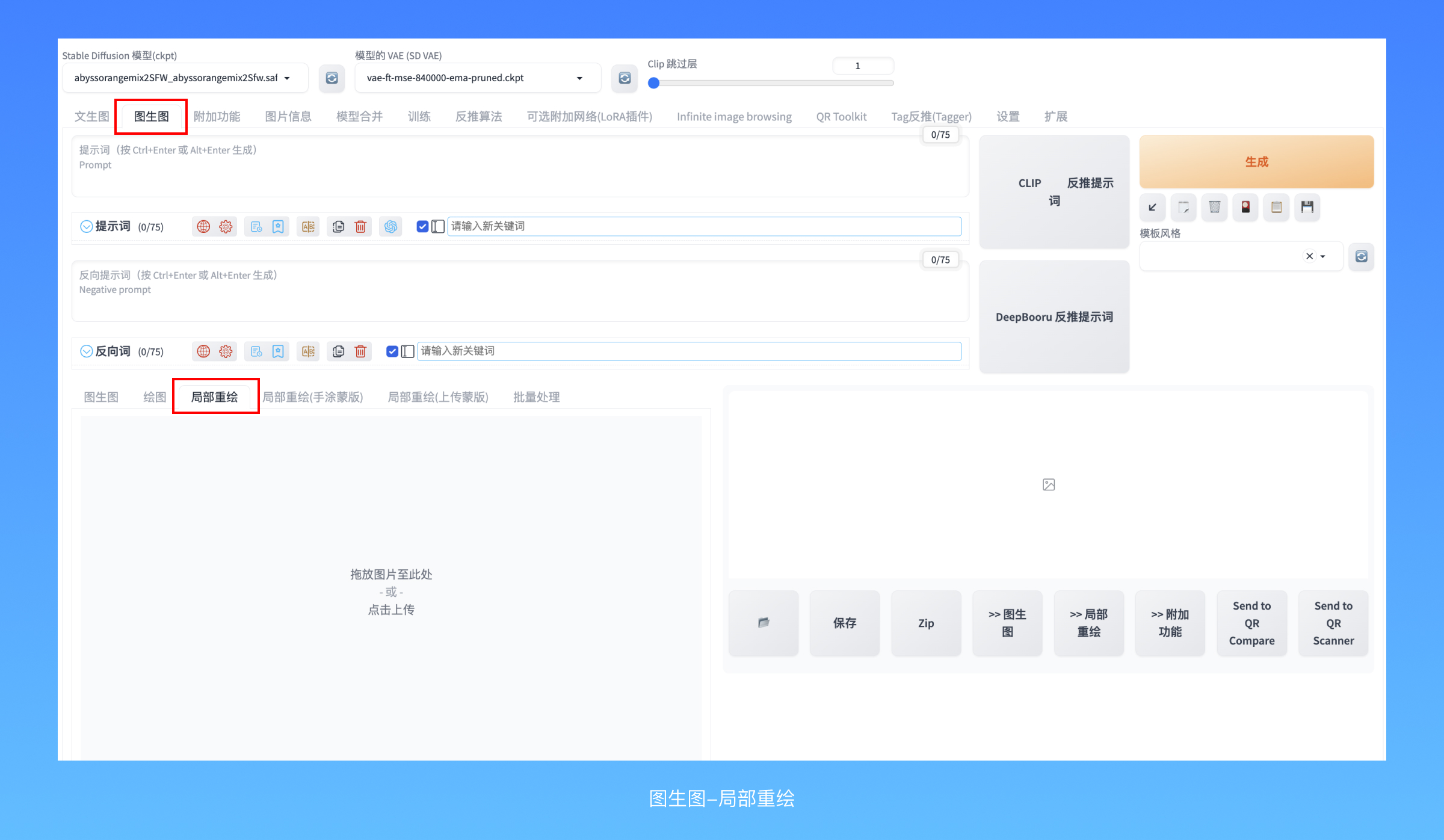
有一个小小的变化:当你把鼠标移动到图片区域上时,会出现一个画笔,使用它可以在图片上涂出黑色区域,覆盖住想要AI重画的地方。右上角有两个按钮,撤销、调节画笔的笔触大小。
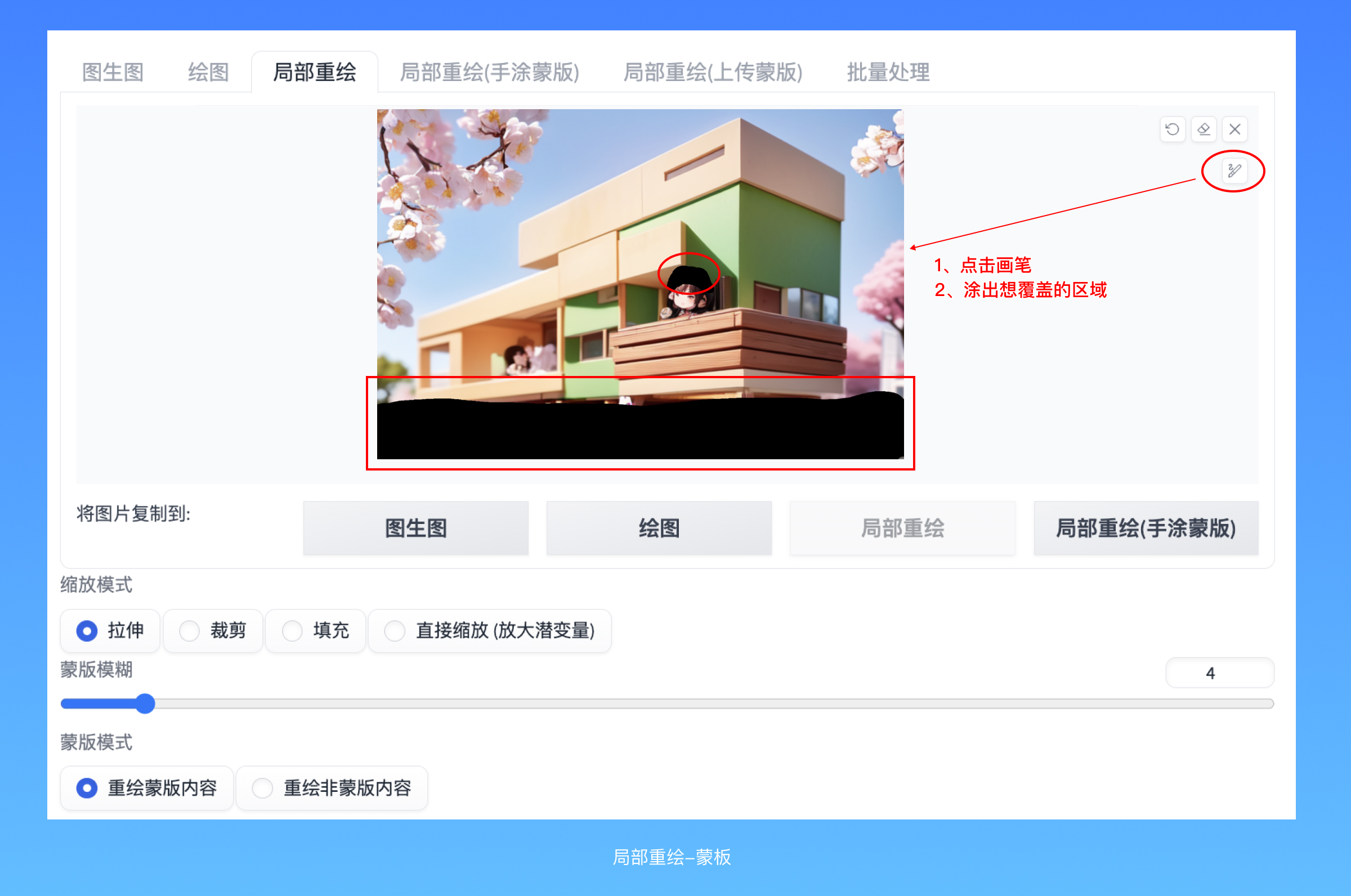
这里面有一个“蒙版”的概念,蒙版是图像处理领域的专业名词,泛指一些用以限定处理区域的范围对象,字面意义上理解就是一个蒙住了某些关键区域的版子,如果你学过PS,对这个概念一定不会陌生。在这里我们画笔涂出来的黑色,也是一个这样的蒙版。蒙版蒙住的内容,可以想像是把这一小块拿给AI图生图的时候,它接收到的信息。
在重绘的过程中,整张图片都经历了一个重新加噪并去噪的过程,相当于把这一块拿出来单独“图生图”一下,最后再拼回到原图里。用这种方式,就可以自由的指挥AI针对画面内部的各个区域做单独的修改了,而想要进一步的把控修改的细节,就需要调整局部重绘参数,他们会具体决定这个重绘过程的一些实现方式。
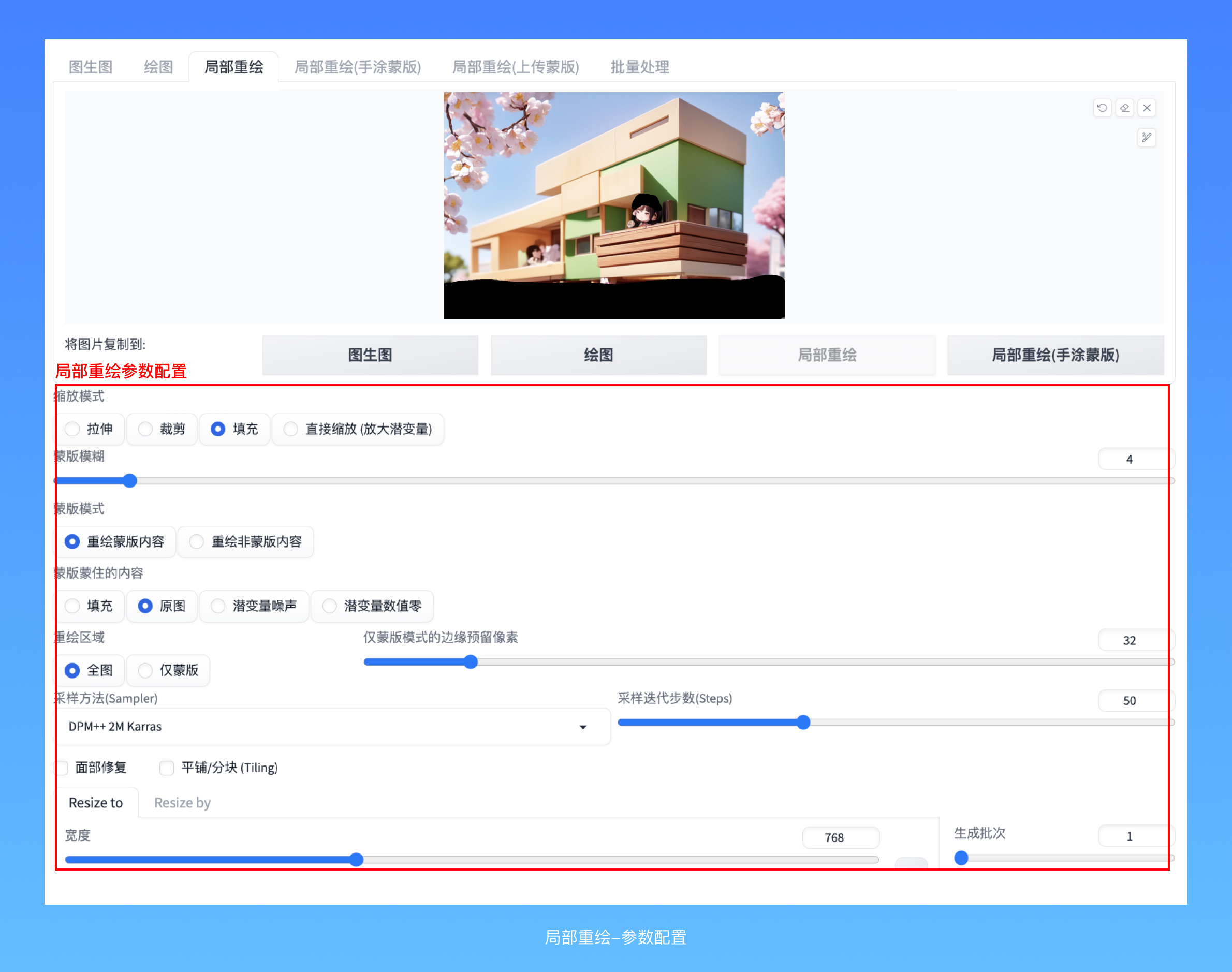
[原图] 就是原图的内容,而如果你想给AI多一点发挥空间,可以选填充,这样会把原图高度模糊以后再输入进去生成,后面两种涉及潜变量、潜空间的生成方式原理比较复杂,简单的说就是把这个图生图的过程进一步复杂化了,加入了加噪、去噪的过程,理论上对图像的改变会更显著,你可以试一下。
重绘区域的 [全图] 和 [仅蒙版] 是AI针对你的画面做处理时的一个逻辑,如果选全图,那么AI会基于你新的要求(提示词、参数)把整张图重新画一遍,但最后只保留画出来的这一块区域拼回去;如果选择的是仅蒙版,那画面画幅会缩小到蒙版区域附近,把这个区域当作一张完整的画面,然会再拼回去,这种方式涉及的区域小,绘制速度很快,但因为它没法读取图像全貌,所以经常出现拼上去以后变得奇奇怪怪的问题。因此,多数时候我都会建议你把“格局打开”。
这不是说 [仅蒙版] 的重绘就一点价值也没有,一些针对性强的修改反而会希望缩小图片画幅,但这个时候你需要降低重绘幅度避免变形,并且对提示词做净化处理。
仅蒙版模式的 [边缘预留像素],和上面放大时提到过的“拼合缓冲带”作用类似,这里不再赘述了。
[蒙版模糊] 决定了你的这个重绘区域边缘和其他部分是如何接触的,这个和PS里面“羽化”的概念非常像,一个10以内的模糊数值可以让重绘区域拼接进去的过程更加丝滑。
恭喜你!已经看完了90%的内容,可以的话给我个 一键三连 吧~
五、ControlNet-AI绘画的工业革命
今年2月,一款名叫ControlNet的AI绘画插件横空出世,固定构图、定义姿势、描绘轮廓,单凭线稿就能生成一张丰满精致的插画。ControlNet 翻译过来就是“控制网”,开发者是一位叫做Lvmin Zhang的华裔,早在2017年,他就发表过一篇论文研究使用增强型残差U-Net与辅助分类器生成对抗网络来实现动漫素描的风格迁移。他第一篇关于ControlNet的研究论文发表在23年2月10号,几天后就将适配于webUI的ControlNet扩展开源在了GitHub上,一经公开就引发了重磅讨论。

上文说到,基于扩散模型的"AI绘画"是非常难以控制的,去扩散这张图片的过程充满了随机性,如果只是用于自娱自乐,那这种随机性并不会带来很大的困扰,画出来的内容和预想中有一点偏差也可以接受,但一些真正面对具体“需求”的时候,如果不能做到精确的“控制”,只能依赖“抽卡”式的反复尝试来得到想要的东西,那AI的产出水平是缺乏稳定性的,也绝对无法称之为一个真正的生产力。ControlNet以一种近乎降维打击的方式实现了很多前所未有的控制,我个人觉得,它的出现直接把SD提升到了可以大规模商用的高度,从而拉开了同 Midjourney 的差距。
在作用原理上,ControlNet和LoRA有许多相似之处,定位都是对大扩散模型做微调的额外网络,它的核心作用是基于一些额外输入给它的信息来给扩散模型的生成提供明确的指引,这个过程和图生图有点像,本质上都是在通过一些方式给AI提供额外的信息,但ControlNet记录的信息比图生图里的图片更为纯粹,排除了图片本身的元素——比如上面已有的颜色、线条的影响,那就不会对其他你想要通过提示词、LoRA等去输入的信息构成太多影响。
目前有很多做ControlNet的模型,这里结合一开始的案例介绍一下Canny。
Canny是一个最重要的模型,它来自于图像处理领域里的一种边缘检测算法,致力于识别并提取出图像里面的边缘特征。Canny几乎可以被应用在任何需要还原图像外形特征的场景里,比如画一只狗狗、一辆汽车,这些复杂形象通过它们的外形得到了识别,那Canny就会把这种外形特征使用线条勾勒出来,在生成的时候控制图像还原。如果你的图像里包含了一些需要精确表达的内容,例如文字、标识,使用Canny可以有效确保它不变形。
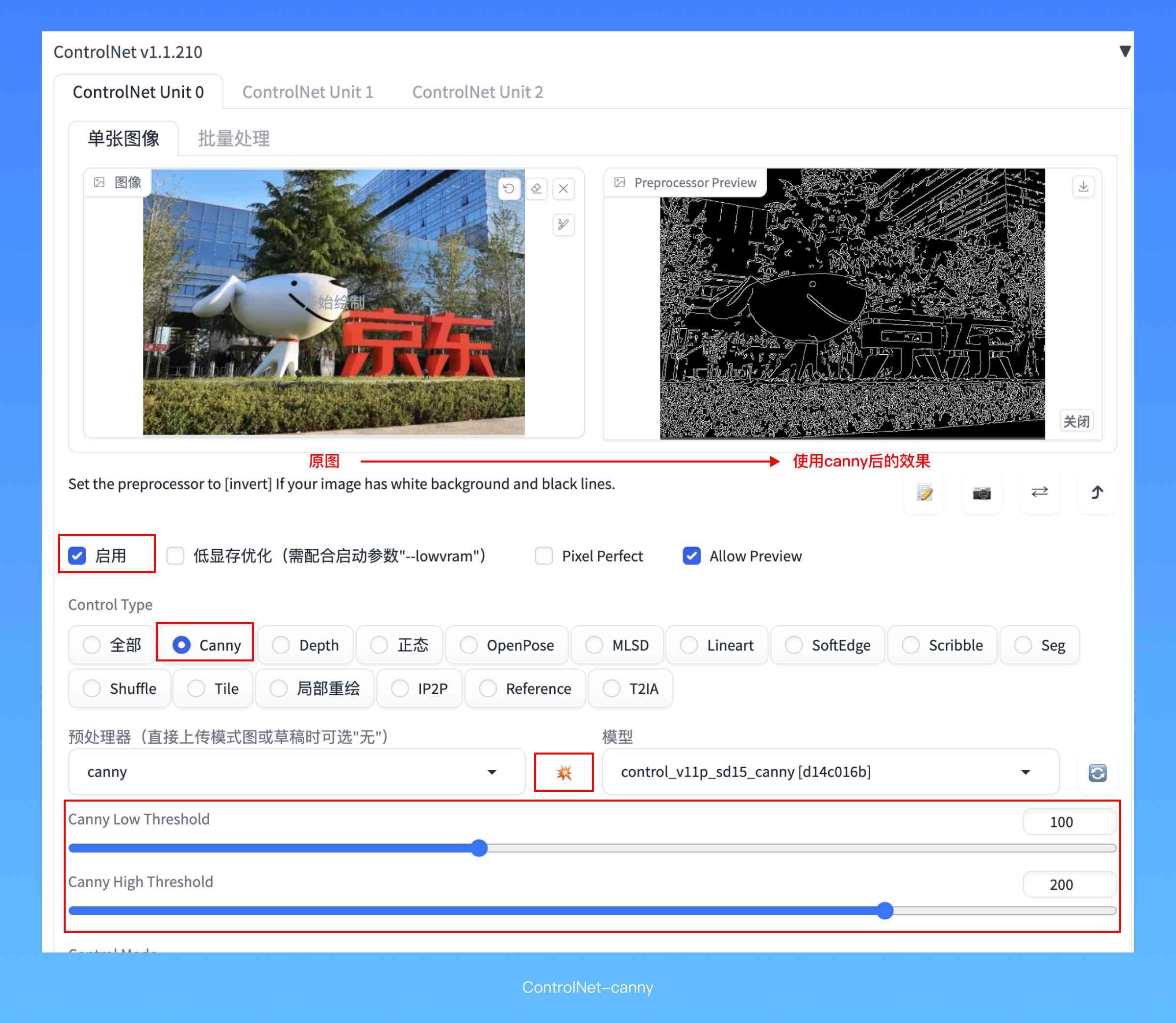
输入一张图片,选择Canny预处理器和模型,它只有一种处理手段,没有那么花里胡哨,点击“爆炸”,处理出来的线条图是这样一幅有点草膏味道的黑底白线线条图。使用Canny过程中,如果有些线条无法被识别出来,那可以考虑适当降低下面两个Threshold(阈值)的数值,它能将更多明暗差异不是那么明显的线条识别进来,从而让形体更加准确。但注意,线条也不能过于密集了,不然生成出来的图像可能会有很多无用的小细节,显得有点“脏”。
就像提示词不怕越加越多、多个LoRA模型可以按照不同权重一起使用,ControlNet也可以把几种不同的模型“混合”在一起,从而实现更加精准的控制。
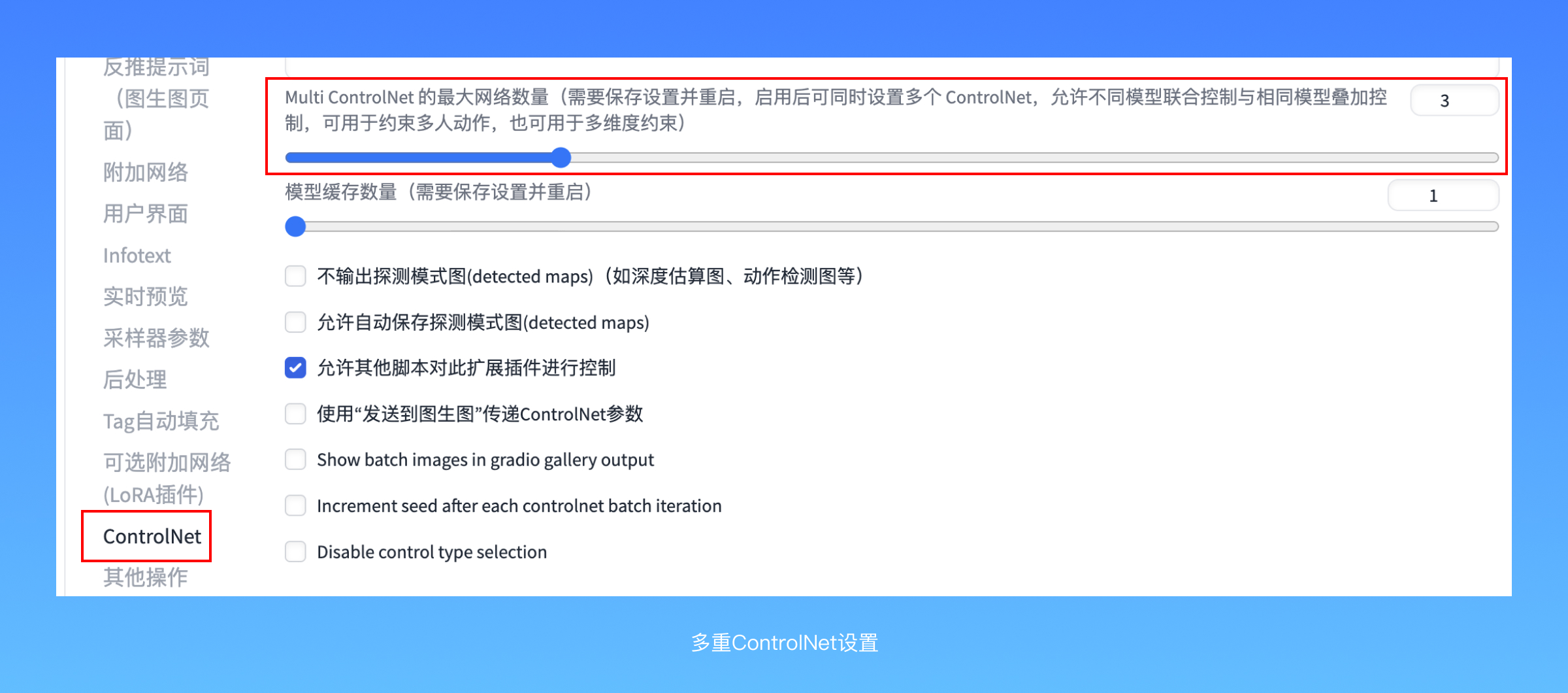
在设置里面,找到ControlNet的设置选项,在里面有一个多重ControlNet(MultiControlNet)的最大模型数量,默认值是1,你可以将它调大-保存-重启webUI,你的ControlNet就变得稍微不一样了:原来只有一组ControlNet选项,但现在上面冒出来几个新的“Unit”, 你可以在里面配置完全不同的预处理器和模型组,也可以使用完全不一样的图片作为输入信息:一个经典的组合是 lineart + brightness,实现创意字体效果,更多复杂的玩法,你可以自行尝试~也可以文末加入交流群,我们一起探索炼丹之术❤️
看到这里你应该开始慌了,ControlNet已经有了15种不同的控制模型,而他们光是两两组合,就会有超过100种实际应用,但其实,并不是随便2个凑一起就一定行的,这里面组合的关键就在于你需要让他们存在一定程度的“互补”,让一个网络帮另一个网络实现那些它做不到的事情。

ControlNet的发展很快,只凭记忆力去追赶它,如同骑着共享单车去追高铁一样望尘莫及,但无论是看起来一丝不苟的Onenpose、Depth,还是天马行空的HED、Scribble,又或者实现创新性局部重绘的inPaint模型、在放大工作流中用于增加细节的Tile模型,以及前不久刚发布用于固定特征的Reference Only……它们都是在某些方面帮助我们去对AI施加一些用语言、文字不是那么好传达的“控制”,而从严格到宽松,控制效应的强弱在变化,最终塑造图像的方式也会有差异。只要看清ControlNet的本质,预处理器和模型作用的根本关系,以及在这中间给AI施加“控制”的尺度,你就具备了自由去探索任何一种ControlNet的能力。
六、取代你的不是AI,而是比你更会用AI的人
在AI绘画诞生以来,围绕它的讨论和争议从来没有停止过,有人认为它会“取代”设计师,对行业造成冲击;有人不理解他的生成方式,认为它始终是一个“玩具”……随着AI的快速进化,AI绘画已经从一种试验性的新技术,变成了一个拥有无限潜力的新型生产力,并开始被行业普遍接受。网易、腾讯等大厂体验设计团队都已经开始使用AI提升工作效率,并不断探索新的可能性。
我知道此刻的你在担心什么,Stable Diffusion的架构如此复杂,让很多没有代码基础的小白望而却步。为了让大家更低门槛的体验在云端“快乐作画”,我为你制作了系统镜像,里面内置了 Stable Diffusion 及自动补全提示词等一系列好用的插件,还下载好了几款目前社区里比较火的模型,真正做到开箱即用。
购买方式非常简单,在京东云官网下单后买GPU标准型(12C48G P40),现在购买立项新人19.9元/7天的1折体验价。
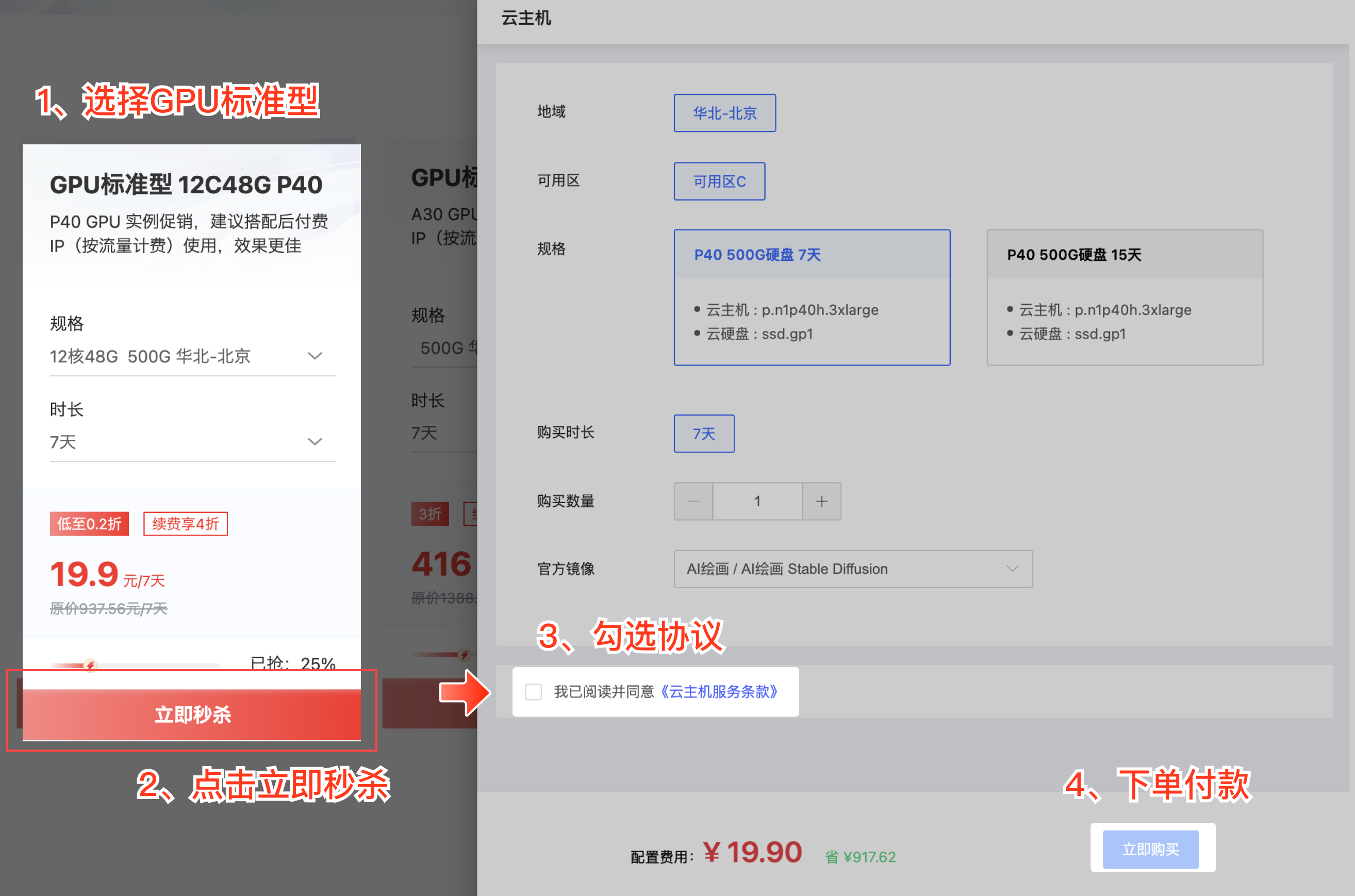
使用方法:1、开通时选择 [AI绘画 Stable Diffusion 镜像];2、公网IP申请及绑定 ;3、按照镜像使用说明 开启端口、启动服务,然后就可以在浏览器内访问 [IP+7860端口],即可进入SD的魔法世界。
来源:京东云开发者社区 转载请注明来源














