
学了大概一个月Scrapy,自己写了些东东,遇到很多问题,这几天心情也不大好,小媳妇人也不舒服,休假了,自己研究了很久,有些眉目了
利用scrapy 框架爬取慕课网的一些信息
步骤一:新建项目
scrapy startproject muke
进入muke
scrapy genspider mukewang imooc.com #mukewang 为爬虫名,imooc.com 是域名,爬虫爬取的范围
步骤二:编写ITEM,定义需要爬取的字段,此处只定义两个字段吧(初学)

步骤三:编写Spider主题,暂时先只爬取title,有些名词用的比较low,莫怪
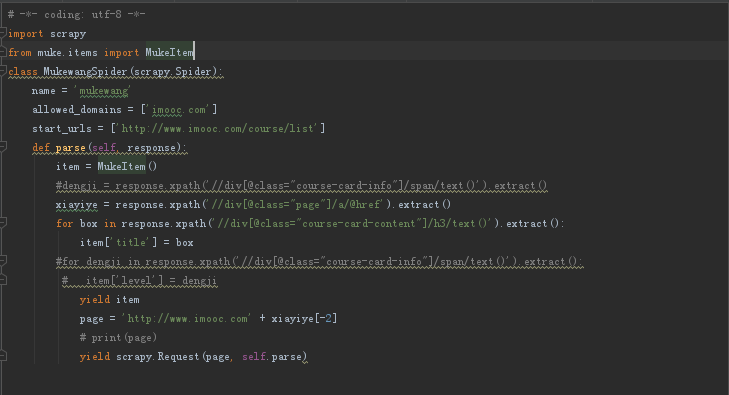
以上基本的东西就写完了
步骤四:运行爬虫 scrapy crwal mukewang 查看结果 爬取结果较多就不一一列举了
期间遇到一点点问题问题,就是我的爬取结果只限制在第一页,收到一个DEUBG信息:
2018-09-27 12:07:09 [scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to 'www.imooc.com': <GET http://www.imooc.com/course/list?page=2>
2018-09-27 12:07:09 [scrapy.core.engine] INFO: Closing spider (finished)
2018-09-27 12:07:09 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
原来是我的allowed_domains出现问题 将allowed_domains=['www.imooc.com/'\]改为allowed\_domains=\['imooc.com'\]即可实现全部爬取
本次算是初学爬虫,自己写了点东西,但是远远没有达到要求,比如储存到数据库,路漫漫其修远兮,吾将上下而求索!!










