
OrientDB的分布式架构绝对不是第一天就规划成这样的,它也是通过版本迭代慢慢演进出现在的这些高大上特性,本文提到的若干知识点其实与其他数据库的分布式特性有相通之处,有经验的读者可以自行比对。

Multi - Master Replication
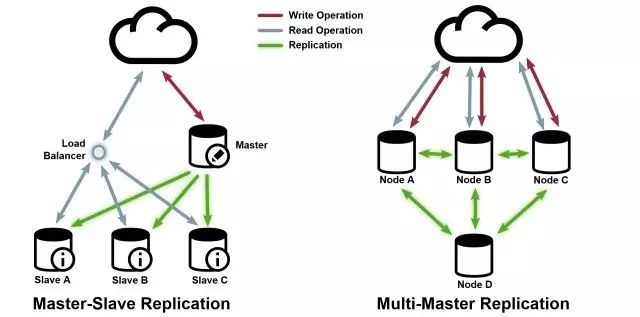
在理解Multi-Master架构之前,我们先简单说下常见的Master-Slave模型。
首先我们要知道这两者在数据库领域一般都是指 Replication数据复制 方面的架构模型。M-S架构也就是常说的一主多从,Slave节点从Master复制数据,只接受客户端的读请求,而所有写请求和“事务中的读请求”只能由Master处理。所以M-S模型有这么几个特点,
Slave可以分担读请求的压力,备份冗余数据降低风险,Slave可以支持backup, ETL等操作,而不会对Master的写操作造成中断影响;
随之而来的问题是,Master单点瓶颈;Master挂掉之后的Slave提升或者等待Master重启,期间可能造成数据丢失;另外多个Slave节点与Master的异步复制仍然会对Master造成压力;只要是复制就存在时差,Slave的数据与Master写入的数据存在时差内的不一致,无法满足ACID。
然后我们再说一下M-M的多主架构(MySQL领域常见的多主一备说法),对比M-S架构M-M的特点也是更加清晰了,就是为了避免Master单点瓶颈,我们就整多个Master,然后多个Master之间复制数据,每个Master都可以接受客户端的读写请求,而且所有请求可以在多个Master之间负载均衡。那么Multi-Master还有什么优劣呢?
优点比较明显,多个Master可以承载读/写请求,不再有单点依赖;快速的Failover, 一个Master挂了,其他的Master可以迅速接管;
M-M解决了一些问题,但是带来的问题也比较棘手。由于多个Master都可写,那数据一致性是个更大的问题,ACID更加难以满足;多个Master之间的复制需要的及时性更高,多主复制延迟会更加严重;若加上了writeQuorum类似的配置,每个请求的同一份数据要在多个点上保存成功方能响应,拉长了响应时间,降低了应用吞吐量。

Master-Slave
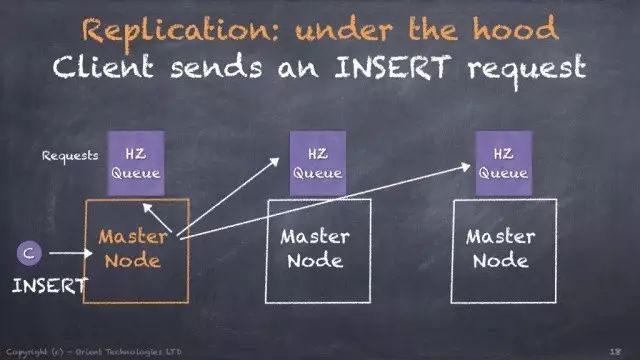
OrientDB的复制就是基于Multi-Master模型,如下图,客户端发来一个Insert请求,这个请求(或者发送二进制数据?官方没详细描述。)会同时发给其他节点进行数据同步。若设置了WriteQuorum = 2表示必须至少2个节点写成功,才会真正的返回成功应答给客户端。
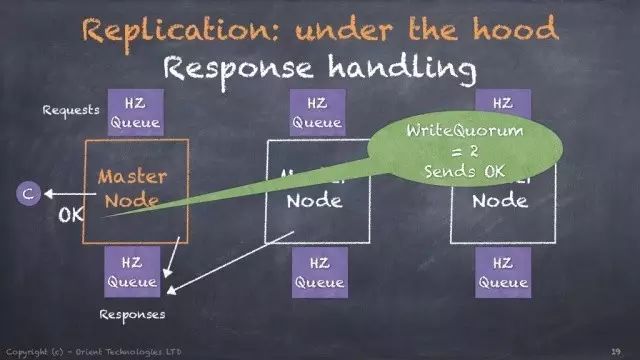
重要: 从 v2.2 开始, OrientDB 使用内部的二进制协议来复制数据,不再使用 Hazelcast ueue实现。图示都是来自老的文档,只当参考。
Server Roles 角色
OrientDB的服务器集群的节点角色除了上面提到的Master,从2.1之后,支持了一个全新的角色“REPLICA”, 即备份冗余节点,它们永远是只读模式,只接受幂等的命令如查询读;
从2.2开始,冗余节点的最大优势是这些节点不会出现在writeQuorum中,即冗余节点没有写投票权。所以你完全可以有3个Master节点用来接受写请求,100个冗余节点接受读请求,但是写请求仍旧只需写成功2台Master即视作最终的成功,100个冗余节点随后异步复制这个写请求对应的数据。
Sharding 分片
数据分片也是分布式存储里面的一个常见手段,OrientDB 需要提高分布计算能力,这个技术当然无法避开。在真正将Sharding讲明白之前先把数据库常用的几个概念过一遍,因为就我所知很多人都是混淆的。
Partitioning - 更多的是一个通用逻辑概念,一般指跨库或者跨表进行的数据分割。而对应的中文说法一般是如下三种:
分库:指将一个巨型的数据库拆分成多个相对逻辑独立/数据内聚的小数据库。比如,将一个庞大的App后台单体应用,按照微服务方式拆分成了User, Order, Credit等, 相应的,单体数据库也据此切割成不同的库;
分表:分表本身有好多种意思也有好多种方法,举个栗子,把User按照userId HASH成了若干张表,这样用户登录查询信息只需要查某一张小表,而且索引速度肯定很快;订单Order按照年份甚至月份分割成不同的小表,如此按照订单号Id查询(前提订单号中有日期),就可以直接定位到小表中查询。
还有一种分表其实可以称作 Vertical Partition , 垂直拆分,继续举例,一个User有很多的家属名字或者联系电话,如果都放在User表里那数据量不用想肯定很大,可以把 家属和联系电话都拆分成不同的表,这也叫分表。
当然MySQL还有些集群分表,Merge引擎分表方案,不详细展开。
分区:关系型数据库的常见概念,表名只有一个,即逻辑上还是一张表,但是背后的物理存储是分区的,不同的分区可以是不同的磁盘也可以是不同的机器。与前面“分表”要达到的效果基本一致,只是分区可能对于开发来说相对要减低一些复杂度,因为对外逻辑上就是一张表而已。
Sharding - 终于讲到我们的分片了,分片的定义就是一种特殊的Partition, “Horizontal Partition 水平切分”。这和上面的分区其实更加接近,只是Sharding更倾向于分布式的玩法,所有的分片均匀的分布在不同的点上,然后查询的时候可以使用类似于大数据中的MapReduce方式,通过并行处理来提高数据处理能力。
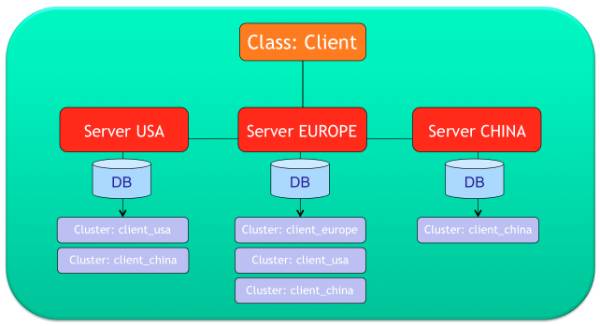
OrientDB的Sharding是通过Cluster来实现的。如上图,Client类有三个Cluster, 按照地域分别是 [ client_usa, client_europe, client_china ], 每个Cluster可以分布在一个或者多个Server Node上,只需要修改配置Json即可。
基础篇我们讲过,所有的RID实际上就是由 Cluster Id + Cluster Position 拼装而成,即是通过Cluster Id找到Cluster, 然后通过Cluster中的配置找到具体的记录。
Sharding分片也是有技巧的,绝对不是分的越散越好,否则你做个简单查询要跨好几个Node, 这种网络IO和磁盘IO成本都会极高。所以随之而来就会有一个“Locality 局部性/本地性”概念,就是尽量把相关内聚的数据分片到同一个Node, 保证大部分的数据操作都可以限定在同一个本地Node, 而不需要跨多个Node进行数据聚合。
几个知识点:
分片后每个服务器节点只有自己本地的索引,所以唯一索引分片后并不能保证仍旧是唯一的。
分布式运行的OrientDB是没办法指定Cluster选择策略的,因为所有节点都被自动指定了“Local"策略,即上方说的Cluster Locality局部化。
局部化还有一个体现就是自动创建的Cluster名字 = <class类名>_<node节点名>,比如client_usa。
更新、删除单条记录,需要通知这条记录存储所在Cluster的所有节点。比如我要更新记录RID #13:22,对应的 clusterId=13 假设Cluster是client_china,它是由三个Node一起管理的,所以,这个更新必须同时发送到china, usa, euro三个节点上。
例外情况,更新、删除不能在数据分片到不同节点的情况下运行。例如,删除命令delete from vertex Client,如果Client的所有数据被复制冗余在所有节点上,那么这个delete只要在一个节点上操作,这个可以运行。 但若这个删除操作需要在多个节点上运行才能删干净的话,就会抛出ODistributedOperationException异常了,原因是你的操作分布在多个节点上,非幂等且需要map-reduce。
这种分片情况下的更新/删除只能通过SELECT出所有的记录,然后遍历着一个一个运行了。
Cluster Ownership
继续参照上放的Sharding图说明一下Cluster所有权问题,如图:
client_usa, 分布在 ”usa" "europe" 节点上;
client_europe, 只分布在 ”europe" 节点上;
client_china, 分布在所有节点上;
实际上这个配置是有顺序的(图中上下排列,或者Json配置文件先后)。比如Server USA就对 client_usa 具有拥有权, EUROPE 对 client-europe 具有拥有权。什么意思呢? 举个例子,你现在要在USA节点上创建一个Client的顶点记录,那么这个顶点就会默认选择USA拥有的client_usa,RID=client_usa的id + position; 同理,在EURO节点上创建顶点返回的RID=client_euro的id + postion。
注意:
如果在USA节点上同一个类有client_usa1, client_usa2, client_usa3...等多个Cluster的话,OrientDB会自动选用 Round Robin 轮询的方式平衡请求。
在USA节点上创建新的Client记录, 因为client_usa是由“USA”和“EURO”两个节点管理的(但是只有USA具有拥有权),所以这个“创建”动作会同时发送给两个节点。实际上这时,你可以把USA当做client_usa的Owner, 而"EURO"当做一个Backup而已。
USA节点既然是client_usa Cluster的拥有者,那么若要在client_usa上创建记录,只能在USA节点上,其他节点操作INSERT INTO client_usa这种明显的对一个你不拥有的Cluster进行操作就会抛出异常!
总体而言,目前OrientDB的功能已经异常强大,可以满足大部分的分布式图数据需求,无可避免的,仍有一些限制和坑,后面的3.x肯定会升级和修复,直到更加地牛掰。
先说这么多
一点一点榨


本文分享自微信公众号 - 曲水流觞TechRill(TechRill)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












