
背景
由于公司目前的主要产品使用的注册中心是consul,consul需要用集群来保证高可用,传统的方式(Nginx/HAProxy)会有单点故障问题,为了解决该问题,我开始研究如何只依赖consul做集群的注册的方式,经过一天的折腾,总算验证了可以通过集群版ConsulClient来进行集群注册,在部署实施过程中也遇到了一些问题,特此记录分享,希望能对有需要的同学有帮助。
主机版集群和docker版集群对比
client+server转发模式的集群部署涉及到两种选择,第一种是直接主机模式部署,2个client+3个server,每个consul实例部署一台主机(适合土豪使用),此种模式的好处就是简单暴力,而且运维相对简单。此种模式的架构部署图如下: 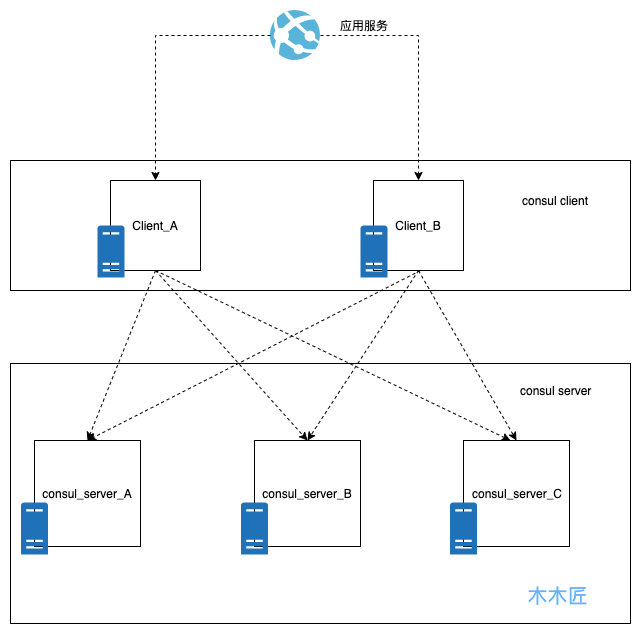
我们选择的是另外一种经济节约模式,docker化部署,好处就是节约资源,劣势就是要管理许多docker镜像,在有引入k8s这些容器管理平台之前,后续docker的运维会比较麻烦,这种模式的架构部署图如下:
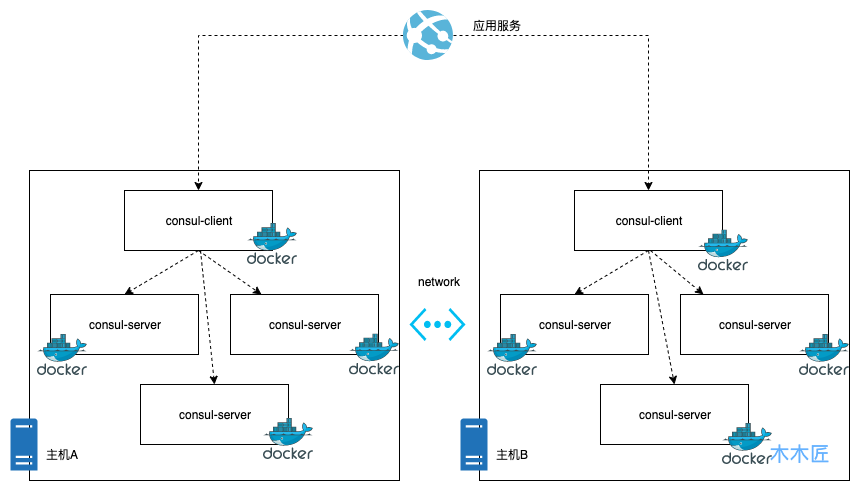
通过以上两种模式的架构图我们很清楚的就能知道主机部署模式是最简单直接的,而docker的模式虽然节省了资源,但是加大了复杂性,增加了运维的难度。但是这种模式应该是在目前容器化的环境下很好的选择,原因很简单,因为充分的利用了资源,容器的运维可以交给容器运维平台去完成,比如k8s等。下面我们来实践下如何进行容器化的consul集群部署。
环境准备
这里准备了两台虚拟主机,由于是虚拟的主机,对外ip是一样的,所以我们以端口区分。
主机A:192.168.23.222:10385 内网ip:192.168.236.3
主机B:192.168.23.222:10585 内网ip:192.168.236.5
部署配置
步骤一:主机安装Docker环境(以Centos为例)
yum install docker
步骤二:拉取Consul镜像进行部署
docker pull consul
步骤三:给主机Docker分配ip段,防止多主机ip重复
在主机A编辑
docker的/etc/docker/daemon.json文件,添加下面的内容"bip": "172.17.1.252/24"
在主机B编辑
docker的/etc/docker/daemon.json文件,添加下面的内容"bip": "172.17.2.252/24"
这里的配置是给主机的docker实例分配ip,因为后续docker会进行跨主机注册,如果默认注册的话,docker是用的主机内网,从而导致ip重复,所以这里手动进行ip分配,当然上述的ip配置你可以自定义。
步骤四:在主机A部署Consul
Node1:
docker run -d --name=node_31 --restart=always \
-e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt": true}' \
-p 11300:8300 \
-p 11301:8301 \
-p 11301:8301/udp \
-p 11302:8302/udp \
-p 11302:8302 \
-p 11400:8400 \
-p 11500:8500 \
-p 11600:8600 \
consul agent -server -join=172.17.1.1 -bootstrap-expect=3 -node=node31 \
-data-dir=/consul/data/ -client 0.0.0.0 -ui
这里重点说明几个参数:
--name:是docker容器的名字,每个容器实例不一样
-node:是consul节点的名字,每个节点不一样
-bootstrap-expect:是启动集群期望至少多少个节点,这里设置是3个。
-data-dir:是consul的数据中心的目录,必须给与consul读写权限,否则启动会报错。
启动成功后,执行命令查看consul的节点。
docker exec -t node_31 consul members
显示结果如下:
Node Address Status Type Build Protocol DC Segment
node31 172.17.1.1:8301 alive server 1.6.2 2 dc1 <all>
这说明第一个节点正常启动了,接下来正常启动主机A剩下的节点。
Node2:
docker run -d --name=node_32 --restart=always \
-e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt": true}' \
-p 9300:8300 \
-p 9301:8301 \
-p 9301:8301/udp \
-p 9302:8302/udp \
-p 9302:8302 \
-p 9400:8400 \
-p 9500:8500 \
-p 9600:8600 \
consul agent -server -join=172.17.1.1 -bootstrap-expect=3 -node=node32 \
-data-dir=/consul/data/ -client 0.0.0.0 -ui
Node3:
docker run -d --name=node_33 --restart=always \
-e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt": true}' \
-p 10300:8300 \
-p 10301:8301 \
-p 10301:8301/udp \
-p 10302:8302/udp \
-p 10302:8302 \
-p 10400:8400 \
-p 10500:8500 \
-p 10600:8600 \
consul agent -server -join=172.17.1.1 -bootstrap-expect=3 -node=node33 \
-data-dir=/consul/data/ -client 0.0.0.0 -ui
三个节点启动完毕后,执行命令,查看节点的状态:
docker exec -t node_31 consul operator raft list-peers
结果如下:
Node ID Address State Voter RaftProtocol
node32 ee186aef-5f8a-976b-2a33-b20bf79e7da9 172.17.1.2:8300 follower true 3
node33 d86b6b92-19e6-bb00-9437-f988b6dac4b2 172.17.1.3:8300 follower true 3
node31 0ab60093-bed5-be77-f551-6051da7fe790 172.17.1.1:8300 leader true 3
这里已经显示,三个server的节点已经完成了集群部署,并且选举了node_31作为主节点。最后给该主机集群部署一个client就大功告成了。
Node4(client节点)
docker run -d --name=node_34 --restart=always \
-e 'CONSUL_LOCAL_CONFIG={"leave_on_terminate": true}' \
-p 8300:8300 \
-p 8301:8301 \
-p 8301:8301/udp \
-p 8302:8302/udp \
-p 8302:8302 \
-p 8400:8400 \
-p 8500:8500 \
-p 8600:8600 \
consul agent -retry-join=172.17.1.1 \
-node-id=$(uuidgen | awk '{print tolower($0)}') \
-node=node34 -client 0.0.0.0 -ui
执行docker exec -t node_31 consul members命令,结果如下:
Node Address Status Type Build Protocol DC Segment
node31 172.17.1.1:8301 alive server 1.6.2 2 dc1 <all>
node32 172.17.1.2:8301 alive server 1.6.2 2 dc1 <all>
node33 172.17.1.3:8301 alive server 1.6.2 2 dc1 <all>
node34 172.17.1.4:8301 alive client 1.6.2 2 dc1 <default>
这里说明,主机A的consul节点全部启动完成,并且完成了集群部署,可以说这就是一个单主机版的consul集群,那么接下来我们要做的就是把主机B的consul加入到主机A的集群中即可。
步骤五:在主机B部署Consul
Node5
docker run -d --name=node_51 --restart=always \
-e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt": true}' \
-p 11300:8300 \
-p 11301:8301 \
-p 11301:8301/udp \
-p 11302:8302/udp \
-p 11302:8302 \
-p 11400:8400 \
-p 11500:8500 \
-p 11600:8600 \
consul agent -server -join=172.17.1.1 -bootstrap-expect=3 -node=node_51 \
-data-dir=/consul/data/ -client 0.0.0.0 -ui
Node6
docker run -d --name=node_52 --restart=always \
-e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt": true}' \
-p 9300:8300 \
-p 9301:8301 \
-p 9301:8301/udp \
-p 9302:8302/udp \
-p 9302:8302 \
-p 9400:8400 \
-p 9500:8500 \
-p 9600:8600 \
consul agent -server -join=172.17.1.1 -bootstrap-expect=3 -node=node_52 \
-data-dir=/consul/data/ -client 0.0.0.0 -ui
Node7
docker run -d --name=node_53 --restart=always \
-e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt": true}' \
-p 10300:8300 \
-p 10301:8301 \
-p 10301:8301/udp \
-p 10302:8302/udp \
-p 10302:8302 \
-p 10400:8400 \
-p 10500:8500 \
-p 10600:8600 \
consul agent -server -join=172.17.1.1 -bootstrap-expect=3 -node=node_53 \
-data-dir=/consul/data/ -client 0.0.0.0 -ui
主机B的三个server节点部署完成后,我们执行命令docker exec -t node_51 consul members查看下集群节点状态
Node Address Status Type Build Protocol DC Segment
node_51 172.17.2.1:8301 alive server 1.6.2 2 dc1 <all>
为什么只有node_51这个单独的节点呢?是不是节点的问题?我们在主机B中查询同样查询一下,结果如下:
node31 172.17.1.1:8301 alive server 1.6.2 2 dc1 <all>
node32 172.17.1.2:8301 alive server 1.6.2 2 dc1 <all>
node33 172.17.1.3:8301 alive server 1.6.2 2 dc1 <all>
node34 172.17.1.4:8301 alive client 1.6.2 2 dc1 <default>
主机A的节点只有他们自己机器的节点,主机B中的节点全部未注册过来,这是为什么呢?原因就是consul绑定的ip是容器的内网ip,主机内部通讯是可以的,跨主机通讯是无法通过内网地址进行通讯的,那么我们怎么做呢?我们通过路由规则进行转发即可,把主机A请求主机B容器的内网地址转发到主机B即可,这里就体现出我们开始给容器分配ip的作用了。 我们在主机A执行如下命令:
route add -net 172.17.2.0 netmask 255.255.255.0 gw 192.168.236.5
这条命令的意思是,添加一个路由规则172.17.2.1~172.17.2.254范围的ip请求,全部转发到192.168.236.5地址下,也就是我们的主机B。 同理主机B也执行如下命令:
route add -net 172.17.1.0 netmask 255.255.255.0 gw 192.168.236.3
添加完成后,在执行docker exec -t node_53 consul members命令:
Node Address Status Type Build Protocol DC Segment
node31 172.17.1.1:8301 alive server 1.6.2 2 dc1 <all>
node32 172.17.1.2:8301 alive server 1.6.2 2 dc1 <all>
node33 172.17.1.3:8301 alive server 1.6.2 2 dc1 <all>
node_51 172.17.2.1:8301 alive server 1.6.2 2 dc1 <all>
node_52 172.17.2.2:8301 alive server 1.6.2 2 dc1 <all>
node_53 172.17.2.3:8301 alive server 1.6.2 2 dc1 <all>
node34 172.17.1.4:8301 alive client 1.6.2 2 dc1 <default>
集群加入就成功了,这就完成了跨主机的docker容器加入。 最后给主机B部署一个client
Node8(client节点)
docker run -d --name=node_54 --restart=always \
-e 'CONSUL_LOCAL_CONFIG={"leave_on_terminate": true}' \
-p 8300:8300 \
-p 8301:8301 \
-p 8301:8301/udp \
-p 8302:8302/udp \
-p 8302:8302 \
-p 8400:8400 \
-p 8500:8500 \
-p 8600:8600 \
consul agent -retry-join=172.17.1.1 \
-node-id=$(uuidgen | awk '{print tolower($0)}') \
-node=node54 -client 0.0.0.0 -ui
最后的集群节点全部加入成功了,结果如下:
node31 172.17.1.1:8301 alive server 1.6.2 2 dc1 <all>
node32 172.17.1.2:8301 alive server 1.6.2 2 dc1 <all>
node33 172.17.1.3:8301 alive server 1.6.2 2 dc1 <all>
node_51 172.17.2.1:8301 alive server 1.6.2 2 dc1 <all>
node_52 172.17.2.2:8301 alive server 1.6.2 2 dc1 <all>
node_53 172.17.2.3:8301 alive server 1.6.2 2 dc1 <all>
node34 172.17.1.4:8301 alive client 1.6.2 2 dc1 <default>
node54 172.17.2.4:8301 alive client 1.6.2 2 dc1 <default>
执行节点状态命令docker exec -t node_31 consul operator raft list-peers:
node32 ee186aef-5f8a-976b-2a33-b20bf79e7da9 172.17.1.2:8300 follower true 3
node33 d86b6b92-19e6-bb00-9437-f988b6dac4b2 172.17.1.3:8300 follower true 3
node31 0ab60093-bed5-be77-f551-6051da7fe790 172.17.1.1:8300 leader true 3
node_51 cfac3b67-fb47-8726-fa31-158516467792 172.17.2.1:8300 follower true 3
node_53 31679abe-923f-0eb7-9709-1ed09980ca9d 172.17.2.3:8300 follower true 3
node_52 207eeb6d-57f2-c65f-0be6-079c402f6afe 172.17.2.2:8300 follower true 3
这样一个包含6个server+2个client的consul容器化集群就部署完成了,我们查看consul的web面板如下: 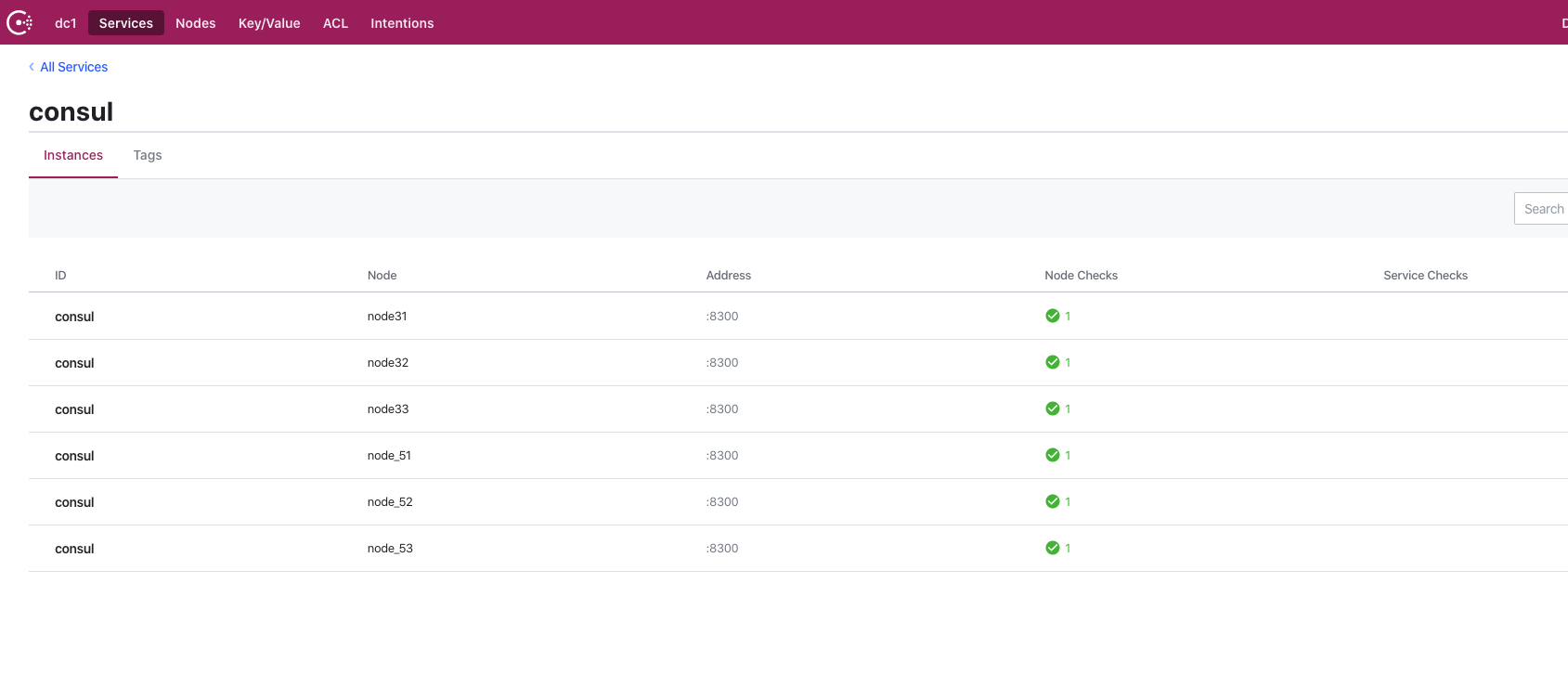
应用集成
集群版本的consul我们就部署好了,那么我们如何与应用集成呢?我们只要集成集群版本的consul注册客户端就行了。 首先加入依赖
<dependency>
<groupId>com.github.penggle</groupId>
<artifactId>spring-cloud-starter-consul-cluster</artifactId>
<version>2.1.0.RELEASE</version>
</dependency>
第二步在bootstrap.yml|properties中指定spring.cloud.consul.host为多节点,如下所示:
spring.cloud.consul.host=192.168.23.222:10385,192.168.23.222:10585
如果想输出注册的相关日志的话也可以在logback上加上日志配置
<logger name="org.springframework.cloud.consul" level="TRACE"/>
这样配置完成后启动成功就能看到我们的应用注册成功了,下图是我测试的注册成功的效果: 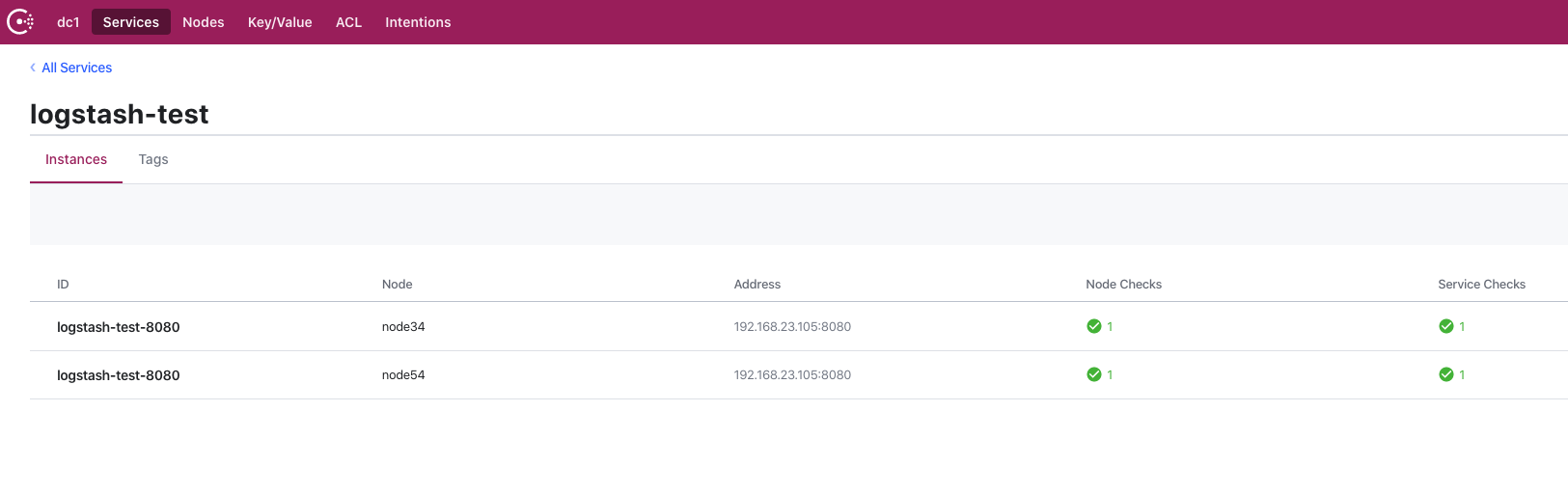
这里显示我的应用节点分别都注册到了集群的2个client上面,通过client的代理转发请求到健康的server,从而实现了consul的高可用。
总结
这篇文章没有研究什么技术干货,纯粹是工作经验分享,主要讲了consul集群部署的方式,传统模式可以通过HAProxy来完成集群的部署,但是这种方式的弊端很明显,通过虚拟ip还是可能会指向故障的节点,所以我们用consul的client+server模式的集群部署,通过docker化来充分利用了机器的资源,只需要2台机器就能完成集群的高可用效果。












