
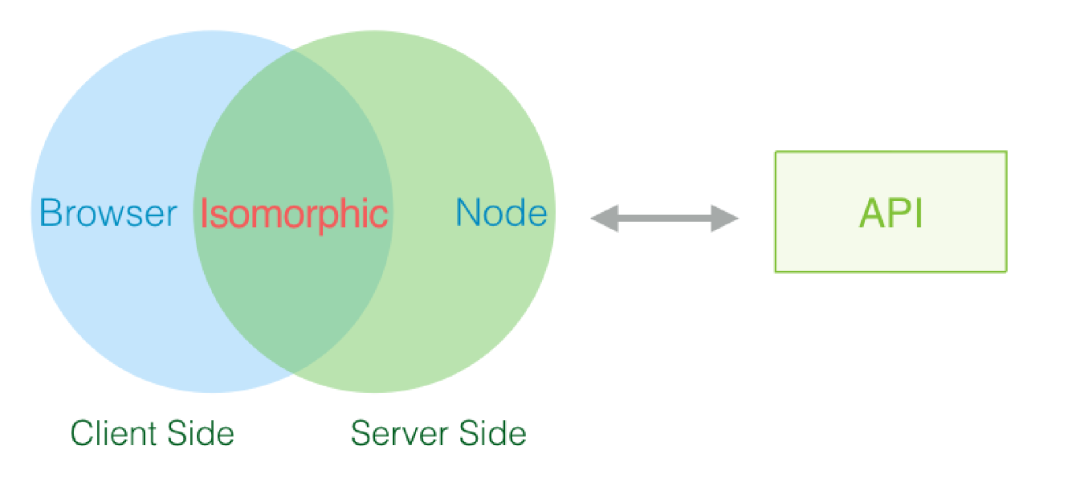
1、相关概念
CSR:客户端渲染(Client Side Render)。渲染过程全部交给浏览器进行处理,服务器不参与任何渲染。页面初始加载的HTML文档中无内容,需要下载执行JS文件,由浏览器动态生成页面,并通过JS进行页面交互事件与状态管理。
SSR:服务端渲染(Server Side Render)。DOM树在服务端生成,而后返回给前端。即当前页面的内容是服务器生成好一次性给到浏览器的进行渲染的。
同构:客户端渲染和服务器端渲染的结合,在服务器端执行一次,用于实现服务器端渲染(首屏直出),在客户端再执行一次,用于接管页面交互(绑定事件),核心解决SEO和首屏渲染慢的问题。采用同构思想的框架:
Nuxt.js(基于Vue)、Next.js(基于React)。
2、ssr(服务端渲染)实现方案
使用next.js/nuxt.js的服务端渲染方案
使用node+vue-server-renderer实现vue项目的服务端渲染
使用node+React renderToStaticMarkup/renderToString实现react项目的服务端渲染
使用模板引擎来实现ssr(比如ejs, jade, pug等)
我所在的部门采用得基于vue的Nuxt框架来实现ssr同构渲染,但是Nuxt并未提供相应的降级策略。当node服务端请求出现偶发性错误(非接口服务挂掉),本来应该在首屏渲染的模块会因无数据而显示空白,双十一等高流量情况下,出现人肉“运维”的无奈,想象一下其他小伙伴陪着对象,吃着火锅、唱着歌,你在电脑前抱着忐忑不安的心情盯着监控系统....我们需要一个降级方案以备不时之需。
3、vue-ssr实现流程
在我们开始降级方案之前,我们必须先对ssr的原理有一定的认知。接下来我们以vue(同理)为例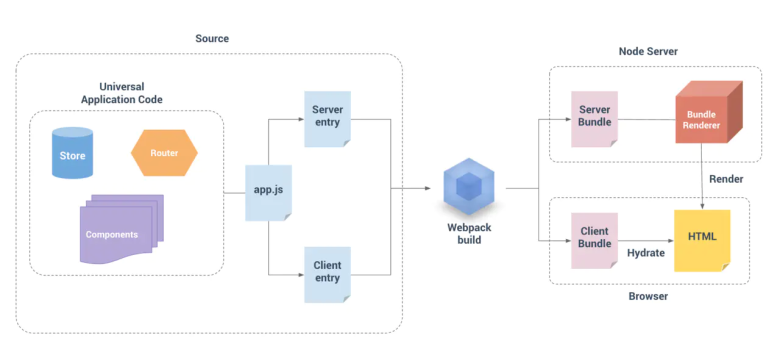 如上图所示有两个入口文件Server entry和Client entry,分别经webpack打包成服务端用的Server Bundle和客户端用的Client Bundle。服务端:当Node Server收到来自客户端的请求后, BundleRenderer 会读取Server Bundle,并且执行它,而 Server Bundle实现了数据预取并将填充数据的Vue实例挂载在HTML模版上,接下来BundleRenderer将HTML 渲染为字符串,最后将完整的HTML返回给客户端。客户端:浏览器收到HTML后,客户端加载了Client Bundle,通过
如上图所示有两个入口文件Server entry和Client entry,分别经webpack打包成服务端用的Server Bundle和客户端用的Client Bundle。服务端:当Node Server收到来自客户端的请求后, BundleRenderer 会读取Server Bundle,并且执行它,而 Server Bundle实现了数据预取并将填充数据的Vue实例挂载在HTML模版上,接下来BundleRenderer将HTML 渲染为字符串,最后将完整的HTML返回给客户端。客户端:浏览器收到HTML后,客户端加载了Client Bundle,通过app.$mount('#app')的方式将Vue实例挂载在服务端返回的静态HTML上。如:
<div id="app" data-server-rendered="true">
data-server-rendered 特殊属性,让客户端 Vue 知道这部分 HTML 是由 Vue 在服务端渲染的,并且应该以激活模式(Hydration:https://ssr.vuejs.org/zh/hydration.html)进行挂载。
4、性能优化
降级的目的是为了预防node服务器压力过大时造成的风险,那么在这之前,也可以通过代码实现来做一定的优化,下面简单介绍下几个常规优化方法
- 减少服务端渲染DOM数
当页面特别长的时候,譬如我们的常见的首页、商品详情页,底部会有推荐商品流、评价、商品介绍等并不会出现在首屏的模块,也不需要在服务端的时候执行渲染,这个时候可以结合vue的插槽系统、内置component组件的is,利用vue ssr服务端只会执行beforeCreate和created生命周期的特性,封装 自定义组件,被该组件在mounted的时候将包裹的组件挂载到component组件的is属性上
通过vue高级异步组件封装延迟加载方法,只有当模块到达指定可视区域时再加载
function asyncComponent({componentFactory, loading = 'div', loadingData = 'loading', errorComponent, rootMargin = '0px',retry= 2}) { let resolveComponent; return () => ({ component: new Promise(resolve => resolveComponent = resolve), loading: { mounted() { const observer = new IntersectionObserver(([entries]) => { if (!entries.isIntersecting) return; observer.unobserve(this.$el); let p = Promise.reject(); for (let i = 0; i < retry; i++) { p = p.catch(componentFactory); } p.then(resolveComponent).catch(e => console.error(e)); }, { root: null, rootMargin, threshold: [0] }); observer.observe(this.$el); }, render(h) { return h(loading, loadingData); }, }, error: errorComponent, delay: 200 });}export default { install: (Vue, option) => { Vue.prototype.$loadComponent = componentFactory => { return asyncComponent(Object.assign(option, { componentFactory })) } }}
- 开启多进程
Node.js 是单进程,单线程模型,其基于事件驱动、异步非阻塞模式,可以应用于高并发场景,避免了线程创建、线程之间上下文切换所产生的资源开销。但是遇到大量计算,CPU 耗时的操作,则无法通过开启线程利用 CPU 多核资源,但是可以通过开启多进程的方式,来利用服务器的多核资源。
单个 Node.js 实例运行在单个线程中。为了充分利用多核系统,有时需要启用一组 Node.js 进程去处理负载任务,cluster 管理多进程的方式为 主-从 模式,master 进程负责开启、调度 worker 进程,worker 进程负责处理请求和其他逻辑。
const cluster = require('cluster');const http = require('http');const numCPUs = require('os').cpus().length;if (cluster.isMaster) { console.log(
主进程 ${process.pid} 正在运行); for (let i = 0; i < numCPUs; i++) { cluster.fork(); } cluster.on('exit', (worker, code, signal) => { console.log(工作进程 ${worker.process.pid} 已退出); });} else { http.createServer((req, res) => { res.writeHead(200); res.end('Hello, Bug Star'); }).listen(8000); console.log(工作进程 ${process.pid} 已启动);}生产环境一般采用pm2来维护node项目
如果控制各进程之间的通信,让每个进程分别处理自己的逻辑,采用编写node脚本的方式启动cluster,从健壮性的角度上讲pm2的方式要好一些
- 开启缓存
页面级缓存:在创建 render 实例时利用LRU-Cache来缓存当前请求的资源。
组件级缓存:需缓存的组件必须定义一个唯一的 name 选项。通过使用唯一的名称,每个缓存键 (cache key) 对应一个组件。如果 renderer 在组件渲染过程中进行缓存命中,那么它将直接重新使用整个子树的缓存结果。
分布式缓存:SSR应用程序部署在多服务、多进程下,进程下的缓存并不是共享的,造成缓存命中效率低下,可以采用如Redis,用以实现多进程间对缓存的共享
5、项目降级改造
业务逻辑的迁移,以及各种MV*框架的服务端渲染模型的出现,让基于Node的前端SSR策略更依赖服务器性能。首屏直出性能以及Node服务的稳定性,直接关系影响着用户体验。Node作为服务端语言,相比于Java和PHP这种老服务端语言来说,对于整体性能的调控还是不够完善。虽然有sentry这种报警平台来及时通知发生的错误,既然是个node服务,那么对于服务也要有相应的容灾方案,不然怎么放心将大流量交给它。那么要实现SSR的降级为CSR,可以理解为需要打包出2份html,一份用来给服务端渲染插件createBundleRenderer当作模版传入输出渲染好的html片段,另外一份是作为客户端渲染的静态模版使用,当服务端渲染失败或者触发降级操作时,客户端代码要重新执行组件的async方法来预取数据
webpack.base.js在公共打包配置中,需要配置打包出的文件位置、使用到的 Loader 以及公共使用的 Plugin
// build/webpack.base.jsconst path = require('path')const VueLoaderPlugin = require('vue-loader/lib/plugin')const resolve = dir => path.resolve(__dirname, dir)module.exports = { output: { filename: '[name].bundle.js', path: resolve('../dist') }, // 扩展名 resolve: { extensions: ['.js', '.vue', '.css', '.jsx'] }, module: { rules: [ { test: /.css$/, use: ['vue-style-loader', 'css-loader'] }, // ..... { test: /.js$/, use: { loader: 'babel-loader', options: { presets: ['@babel/preset-env'] } }, exclude: /node_modules/ }, { test: /.vue$/, use: 'vue-loader' }, ] }, plugins: [ new VueLoaderPlugin(), ]}
webpack.client.js
// build/webpack.client.jsconst webpack = require('webpack')const {merge} = require('webpack-merge');const HtmlWebpackPlugin = require('html-webpack-plugin')const VueSSRClientPlugin = require('vue-server-renderer/client-plugin')const path = require('path')const resolve = dir => path.resolve(__dirname, dir)const base = require('./webpack.base')const isProd = process.env.NODE_ENV === 'production'module.exports = merge(base, { entry: { client: resolve('../src/entry-client.js') }, plugins: [ new VueSSRClientPlugin(), new HtmlWebpackPlugin({ filename: 'index.csr.html', template: resolve('../public/index.csr.html') }) ]})
webpack.server.js
// build/webpack.server.jsconst {merge} = require('webpack-merge');const HtmlWebpackPlugin = require('html-webpack-plugin')const VueSSRServerPlugin = require('vue-server-renderer/server-plugin')const path = require('path')const resolve = dir => path.resolve(__dirname, dir)const base = require('./webpack.base')module.exports = merge(base, { entry: { server: resolve('../src/entry-server.js') }, target:'node', output:{ libraryTarget:'commonjs2' }, plugins: [ new VueSSRServerPlugin(), new HtmlWebpackPlugin({ filename: 'index.ssr.html', template: resolve('../public/index.ssr.html'), minify: false, excludeChunks: ['server'] }) ]})
server.js 部分代码
在该文件中,可以根据请求url参数、err异常错误、获取全局配置文件等方式,判断是否执行SSR的renderToString方法构建Html字符串,还是降级为CSR直接返回SPA Html
const app = express()const bundle = require('./dist/vue-ssr-server-bundle.json')// 引入由 vue-server-renderer/client-plugin 生成的客户端构建 manifest 对象。此对象包含了 webpack 整个构建过程的信息,从而可以让 bundle renderer 自动推导需要在 HTML 模板中注入的内容。const clientManifest = require('./dist/vue-ssr-client-manifest.json')// 分别读取构建好的ssr和csr的模版文件const ssrTemplate = fs.readFileSync(resolve('./dist/index.ssr.html'), 'utf-8')const csrTemplate = fs.readFileSync(resolve('./dist/index.csr.html'), 'utf-8')// 调用vue-server-renderer的createBundleRenderer方法创建渲染器,并设置HTML模板,之后将服务端预取的数据填充至模板中function createRenderer (bundle, options) { return createBundleRenderer(bundle, Object.assign(options, { template: ssrTemplate, basedir: resolve('./dist'), runInNewContext: false }))}// vue-server-renderer创建bundle渲染器并绑定server bundlelet renderer = createRenderer(bundle, { clientManifest})// 相关中间件 压缩响应文件 处理静态资源等app.use(...) // 设置缓存时间const microCache = LRU({ maxAge: 1000 * 60 * 1})function render (req, res) { const s = Date.now() res.setHeader('Content-Type', 'text/html') // 缓存命中相关代码,略... // 设置请求的url const context = { title: '', url: req.url, } if(/**与需要降级为ssr的相关 url参数、err异常错误、获取全局配置文件...条件*/){ res.end(csrTemplate) return } // 将Vue实例渲染为字符串,传入上下文对象。 renderer.renderToString(context, (err, html) => { if (err) { // 偶发性错误避免抛500错误 可以降级为csr的html文件 //打日志操作..... res.end(csrTemplate) return } res.end(html) })}// 启动一个服务并监听8080端口app.get('*', render)const port = process.env.PORT || 8080const server = http.createServer(app)server.listen(port, () => { console.log(`server started at localhost:${port}`)})
entry.server.js
import { createApp } from './app'export default context => { return new Promise((resolve, reject) => { const { app, router, store } = createApp() const { url, req } = context const fullPath = router.resolve(url).route.fullPath if (fullPath !== url) { return reject({ url: fullPath }) } // 切换路由到请求的url router.push(url) router.onReady(() => { const matchedComponents = router.getMatchedComponents() if (!matchedComponents.length) { reject({ code: 404 }) } // 执行匹配组件中的asyncData Promise.all(matchedComponents.map(({ asyncData }) => asyncData && asyncData({ store, route: router.currentRoute, req }))).then(() => { context.state = store.state if (router.currentRoute.meta) { context.title = router.currentRoute.meta.title } resolve(app) }).catch(reject) }, reject) })}
entry-client.js
import 'es6-promise/auto'import { createApp } from './app'const { app, router, store } = createApp()// 由于服务端渲染时,context.state 作为 window.INITIAL_STATE 状态,自动嵌入到最终的 HTML 中。在客户端,在挂载到应用程序之前,state为window._INITIAL_STATE__。if (window.INITIAL_STATE) { store.replaceState(window.INITIAL_STATE)}router.onReady(() => { router.beforeResolve((to, from, next) => { const matched = router.getMatchedComponents(to) const prevMatched = router.getMatchedComponents(from) let diffed = false const activated = matched.filter((c, i) => { return diffed || (diffed = prevMatched[i] !== c) }) const asyncDataHooks = activated.map(c => c.asyncData).filter( => _) if (!asyncDataHooks.length) { return next() } Promise.all(asyncDataHooks.map(hook => hook({ store, route: to }))) .then(() => { next() }) .catch(next) }) // 挂载在DOM上 app.$mount('#app')})
6、降级策略
Node来进行数据持久化相关的工作,那么I/O和磁盘是主要瓶颈,Node作为前端ssr服务的话,CPU、内存、网络是主要瓶颈,主要是服务器端负载。在 Node.js 中渲染基于vue/react完整的应用程序,大家不妨可以回顾一下,vue和react的渲染工作原理,显然会比仅仅提供静态文件的 server 更加大量占用 CPU 资源(CPU-intensive - CPU 密集)。
6.1Node服务器监控触发降级
CPU指标
由于进程阻塞在CPU上的原因不相同,对于CPU密集型任务来说,CPU利用率可以很好地表示当前CPU的工作情况,但是对于I/O密集型的任务来说,CPU空闲不代表CPU无事可做,可能是任务被挂起,去进行其他操作了。对于进行SSR的Node系统来说,渲染基本上可以理解为CPU密集型业务,所以这个指标在一定程度上可以体现出当前业务环境的CPU性能。
内存指标
内存是一个非常容易量化的指标。内存占用率是评判一个系统的内存瓶颈的常见指标。在 V8 中,所有的 JavaScript 对象都是通过堆来进行分配的。对于process.memoryUsage()拿到的值的定义:
heapTotal和heapUsed代表 V8 的内存使用情况。external代表 V8 管理的,绑定到 Javascript 的 C++ 对象的内存使用情况。rss是驻留集大小, 是给这个进程分配了多少物理内存(占总分配内存的一部分),包含所有的 C++ 和 JavaScript 对象与代码。使用Worker线程时,rss将会是一个对整个进程有效的值,而其他字段只指向当前线程arrayBuffers指分配给ArrayBuffer和SharedArrayBuffer的内存,包括所有的 Node.jsBuffer。这也包含在external值中。当 Node.js 用作嵌入式库时,此值可能为0,因为在这种情况下可能无法跟踪ArrayBuffer的分配。
首先需要关注的是内存堆栈,也就是堆内存的占用。在Node的单线程模式下,C++程序(V8引擎)会为Node申请一定的内存,来作为Node线程的内存资源heapTotal。而在我们Node的使用过程中,声明的新的变量都会使用这些内存来进行存储heapUsed。Node的分代式GC算法会在一定程度上浪费部分内存资源,所以当heapUsed达到heapTotal一半的时候,就可以强制触发GC操作了global.gc()。对于系统内存的监控处理,不能够仅仅像Node内存级别一样,进行GC操作就可以,而同样需要进行渲染降级。70% ~ 80%的内存占用就是非常危险的情况了。具体的数值需要根据环境所在的宿主机来确定。
const os = require('os')const sleep = ms => new Promise(resolve => setTimeout(resolve, ms))class OsUtils { /** * 获取某一时间段内的 CPU 利用率 * @param { Number } Options.ms 默认是 1000ms * @param { Boolean } Options.percentage true(以百分比结果返回)| false(小数返回) * @returns { Promise } CPU 利用率 */ async getCPULoadavg(options = {}) { const that = this; const { cpuUsageMS = 1000, percentage = false } = options const t1 = that._getCPUMetric() await sleep(cpuUsageMS) const t2 = that._getCPUMetric() const idle = t2.idle - t1.idle const total = t2.total - t1.total let usage = 1 - idle / total percentage && (usage = `${(usage * 100.0).toFixed(2)}%`) return usage } /** * 获取 内存 信息 * @param { Boolean } percentage true(以百分比结果返回)| false(小数返回) * @returns { Object } 内存 信息 */ getMemoryUsage(percentage = false) { const { rss, heapUsed, heapTotal } = process.memoryUsage() const sysFree = os.freemem() const sysTotal = os.totalmem(); return { sys: percentage ? `${(1 - sysFree / sysTotal).toFixed(2) * 100}%` : 1 - sysFree / sysTotal, heap: percentage ? `${(heapUsed / heapTotal).toFixed(2) * 100}%` : heapUsed / heapTotal, node: percentage ? `${(rss / sysTotal).toFixed(2) * 100}%` : rss / sysTotal } } /** * 获取 CPU 信息 * @returns { Object } CPU 信息 */ _getCPUMetric() { const cpus = os.cpus(); let user = 0, nice = 0, sys = 0, idle = 0, irq = 0, total = 0 for (let cpu in cpus) { const times = cpus[cpu].times user += times.user nice += times.nice sys += times.sys idle += times.idle irq += times.irq } total += user + nice + sys + idle + irq return { user, sys, idle, total, } }}const osUtils = new OsUtils()osUtils.getCPULoadavg({ percentage: true }).then(res => {console.log('当前CPU 利用率:', res)});console.log('当前内存信息:',osUtils.getMemoryUsage(true))

结合CPU利用率及内存指标,根据实际情况设定阈值,超过阈值将SSR降级为CSR。
6.2、Nigix配置降级
在nginx配置中,将ssr请求转发至Node渲染服务器,并开启响应状态码拦截;
若响应异常,将异常状态转为200响应,并指向新的重定向规则;
重定向规则去掉ssr目录后重定向地址,将请求转发至静态HTML文件服务器。
流程如下: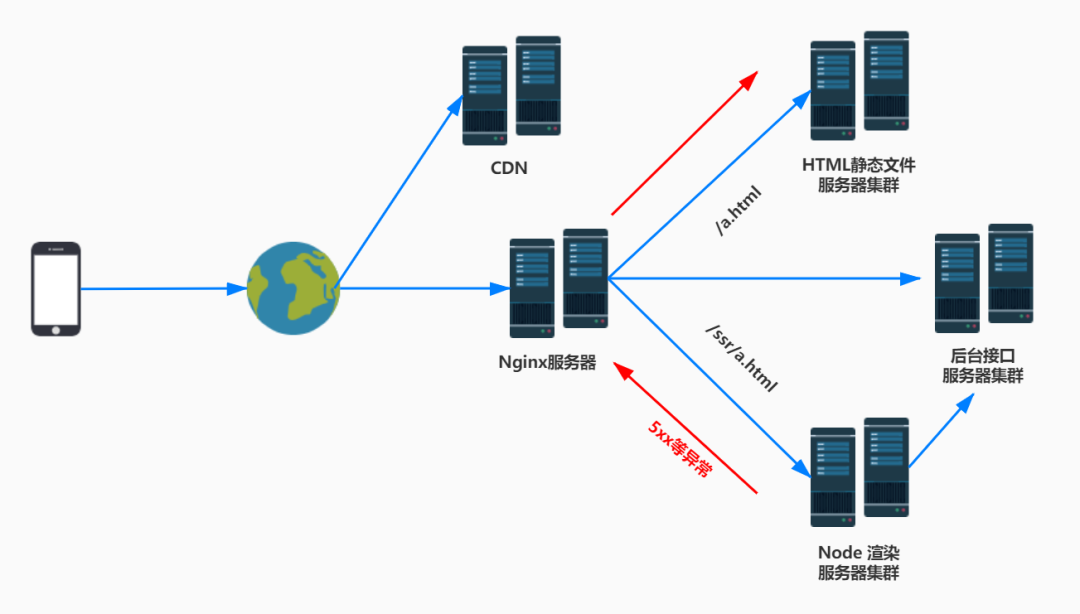 Nginx相关配置
Nginx相关配置
upstream static_env { server x.x.x.x:port1; //html静态文件服务器}upstream nodejs_env { server x.x.x.x:port2; //node渲染服务器}server { listen 80; server_name xxx; ... // 其他配置 location ^~ /zyindex/ { proxy_pass http://static_env; //将非ssr目录的请求转发到静态HTML文件服务器 } location ^~ /zyindex/ssr/ { proxy_pass http://nodejs_env; //将ssr目录的请求转发node渲染服务器 proxy_intercept_errors on; // 开启拦截响应状态码 error_page 403 404 408 500 501 502 503 504 = 200 @static_page; // 若响应异常,将这些异常状态码改为200响应,并指向下面的新规则@static_page } location @static_page { rewrite_log on; error_log logs/rewrite.log notice; rewrite /zyindex/ssr/(.*)$ /zyindex/$1 last; // 去掉ssr目录后重新定向地址,将请求Node渲染服务器转发到静态HTML文件服务器 }}
降级总结
偶发性降级 -- 偶发的服务端渲染失败降级为客户端渲染;
配置平台降级 -- 通过配置平台修改全局配置文件主动降级,比如双十一等大流量情况下,可提前通过配置平台将整个应用集群都降级为客户端渲染;
监控系统降级 -- 监控系统跑定时任务监控应用渲染集群状态,集群资源占用达到设定CPU/内存阈值将整个集群降级or扩容;
渲染服务集群宕机 -- ssr渲染可以理解为另外一种形式的BFF层,接口服务器与ssr渲染服务器是独立的,html的获取逻辑回溯到Nginx获取,此时触发客户端渲染。
参考文献
Node.js环境性能监控 -- https://juejin.im/post/6844903781889474567;
VueSSR高阶指南 -- https://juejin.im/post/6844903669922529287;
vue服务端渲染(SSR)实战 -- https://juejin.im/post/6844903630147944455
后记
以上就是胡哥今天给大家分享的内容,喜欢的小伙伴记得收藏、转发,点击在看推荐给更多的小伙伴。
胡哥有话说,专注于大前端技术领域,分享前端系统架构,框架实现原理,最新最高效的技术实践!
本文分享自微信公众号 - 胡哥有话说(hugeyouhuashuo)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











