大家好,我是皮皮。
一、前言
前几天在Python白银交流群有个叫【蛋蛋】的粉丝问了一个Pandas处理的问题,这里拿出来给大家分享下,一起学习下。

一开始我都没理解她的意思,以为只是简单的替换而已,之前【月神】给了一个代码,当时也写文章记录了,代码如下:
df['col2'] = df['col1'].map({1:"开心", 2:"悲伤", 3:"难过", 4:"泪目"})
df
不过很不巧,这个不是她想要的结果,她想要的结果是同样的几个都是1,然后其余的就是2,3,4,我还是没反应过来,不过【月神】一下子就get到她的意思了,真是太神了。
二、解决过程
这里【月神】给出了解答,使用pd.factorize(data['a'])[0]完美地解决了这个问题。

这个类似于onehot编码,对类型进行了数字编码,如果想要把nan也编码,加一个参数na_sentinel=None。
这样一来,就完美地解决了问题。
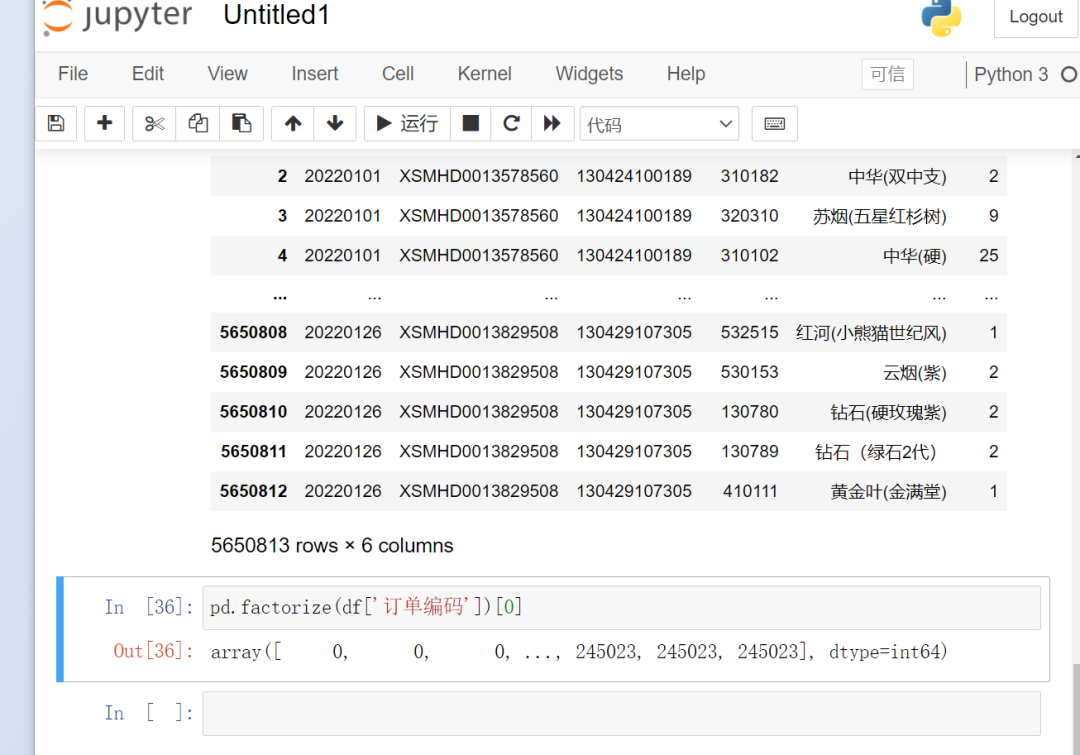
关于pd.factorize()函数的定义如下:
pandas.factorize(values, sort=False, order=None, na_sentinel=-1, size_hint=None) Encode input values as an enumerated type or categorical variable
简单来说,它可以实现将字符串特征转化为数字特征。
[图片上传失败...(image-bcfb44-1651146686981)]
三、总结
大家好,我是皮皮。这篇文章主要分享了Pandas中数据处理的问题,主要讲解了pd.factorize()函数的应用,它可以实现将字符串特征转化为数字特征,针对该问题给出了具体的解析和代码演示,帮助粉丝顺利解决了问题。

最后感谢粉丝【蛋蛋】提问,感谢【月神】和【皮皮】给出的具体解析和代码演示,感谢【dcpeng】、【冫马讠成】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。