大家好,我是皮皮。
一、前言
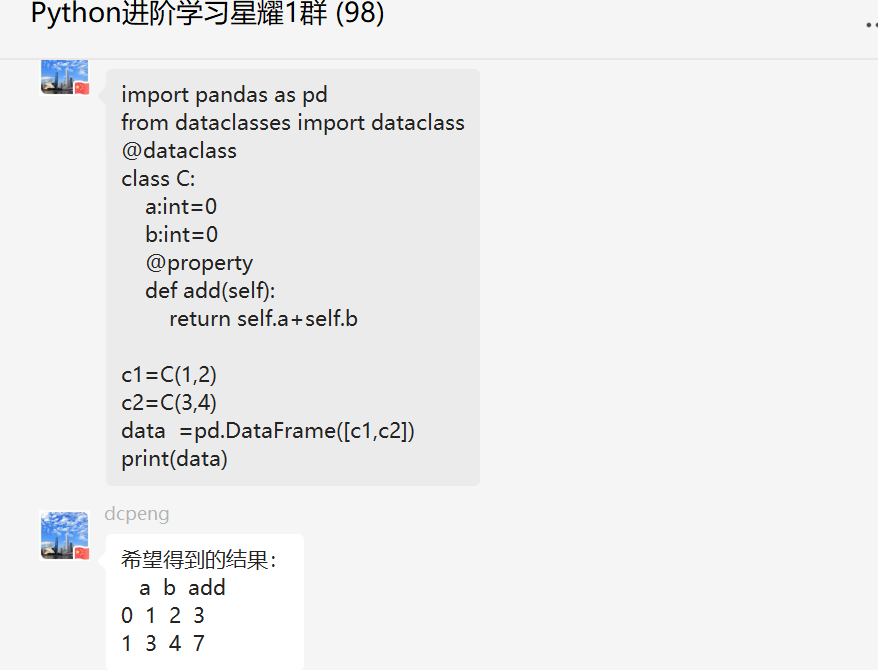
前几天在Python白银交流群【上海新年人】问了一个Pandas基础的问题。问题如下:大佬们,这里面的dtype,能直接改成str格式?我一开始认为只能这么看print(df.dtypes),传统的做法我一直认为是这样子df['数学'] = df['数学'].astype(str),不明白,上面这部,跟这部df['数学'].str.replace()是不是要同时做。
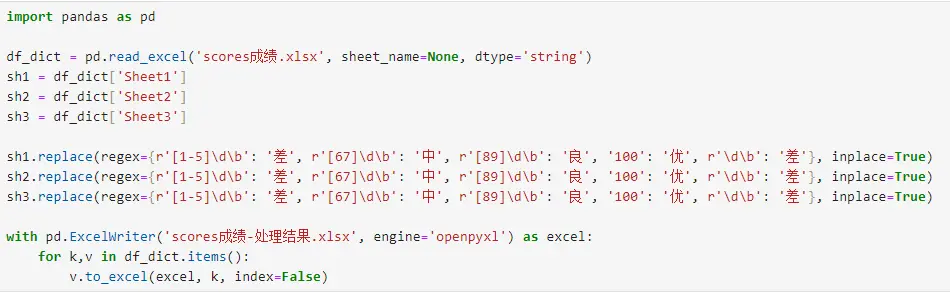
印象中这部df['数学'].str我一直认为是直接转字符串格式str了,上面df['数学'] = df['数学'].astype(str)是多余的了?还有一个疑问,是草莓大哥,在里面做了一个replace(regex={:}),但我记得用正则的时候应该是replace(****,regex=True),是不是草莓大哥做这题时又超纲了?
二、实现过程
这里【瑜亮老师】给了一个详细解答:这里的replace可以传一个字典,把所有的key替换成对应的value。
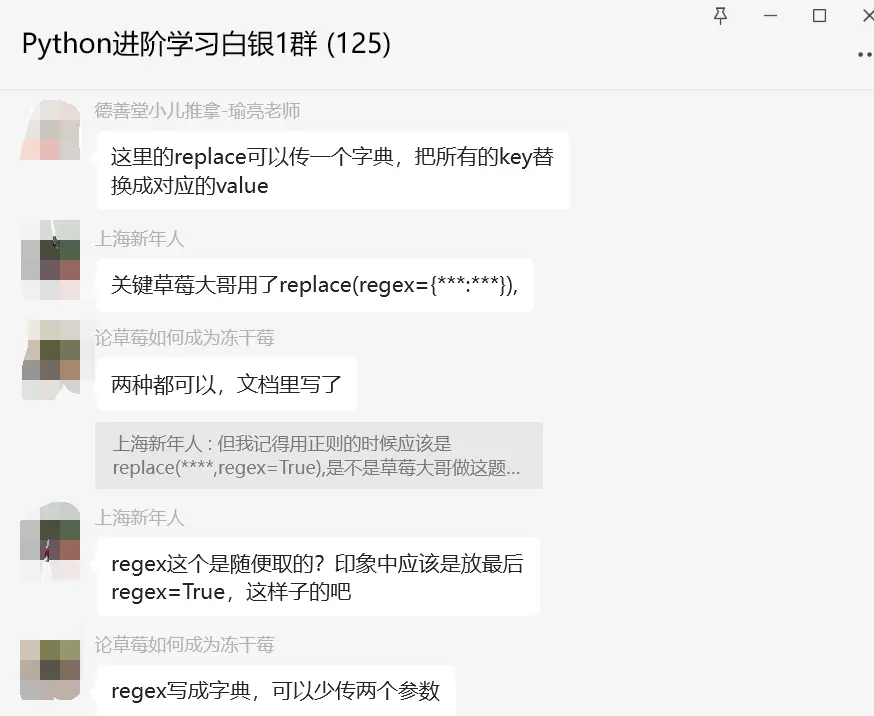
粉丝继续提问:还有我一直不太明白df[*].str.replace与直接写replace()有啥区别?这一步df[*].str是不是把某列转成str格式???。
后来【论草莓如何成为冻干莓】给了一个思路如下:.str是调用Series的str方法,直接用replace是用DataFrame的replace方法。
【瑜亮老师】给了一个思路如下:df.replace还能传2个列表,用列表1的元素替换列表2中的元素,也是11对应的。上面是多对多替换。还可以传1个列表,1个元素。这种是多对一替换。你只学了个一对一替换。
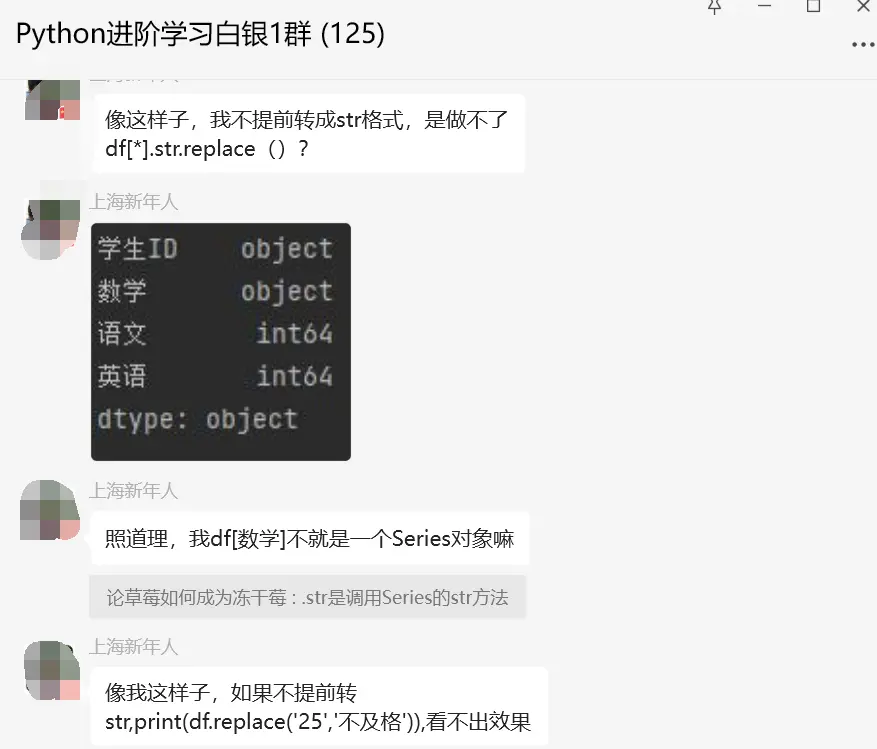
object是混合类型,里面的内容可能是数字,你是数字的25,又不是字符串的'25',因为原df中的25是int,你替换的是字符串25,根本找不到这个,所以不替换。如果你不把int转换为str数据类型,那么无论你用df[].str.replace('25', '不及格'),还是df[].str.replace(25, '不及格')都是不行的,.str.replace 是字符串的方法,并不是把df[]中的数据变成str。
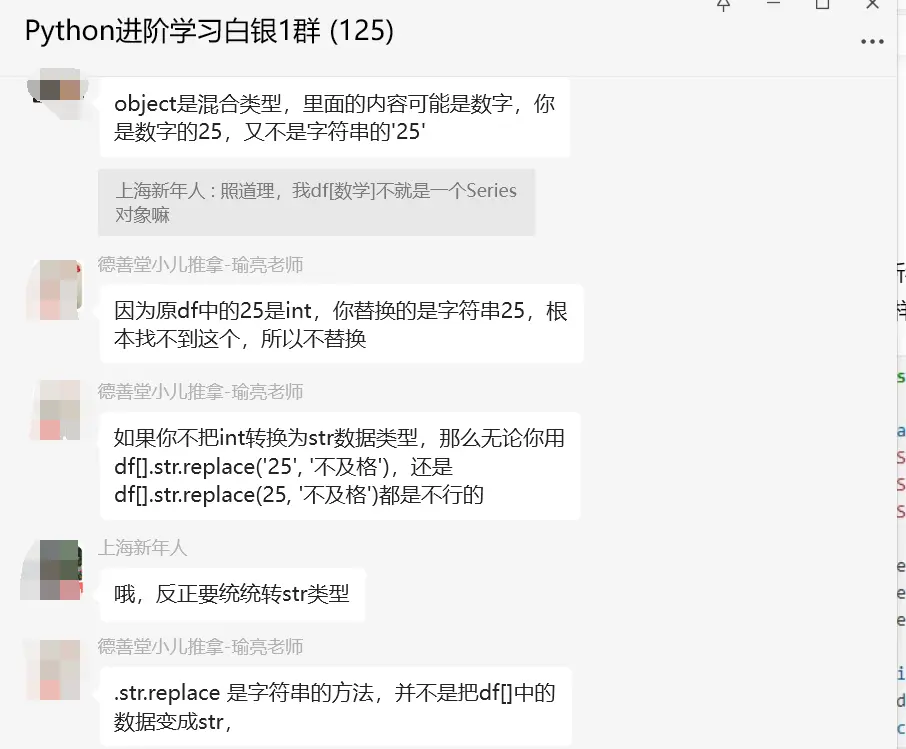
df[]中存的是str,这时候你用.str.replace可以实现替换效果,如果里面不是str你调用字符串的replace,怎么替换?这也是为什么有是会在这之前加个.astype(str)。
顺利地解决了粉丝的问题。
如果你也有类似这种数据分析的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas数据筛选的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【上海新年人】提出的问题,感谢【论草莓如何成为冻干莓】、【瑜亮老师】给出的思路,感谢【莫生气】、【冯诚】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。