大家好,我是皮皮。
一、前言
前几天在Python白银交流群【上海新年人】问了一个Pandas数据处理的问题,一起来看看吧。
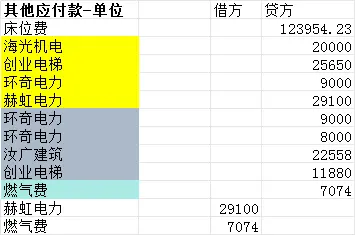
大佬们,如何把某一列中包含某个值的所在行给删除?比方说把包含电力这两个字的行给删除。
这里【FANG.J】指出:数据不多的话,可以在excel里直接ctrl f,查找“电力”查找全部,然后ctrl a选中所有,右键删除行。这个方法肯定是可行的,但是这里粉丝想要通过Python的方法进行解决,一起来看看该怎么处理吧。
二、实现过程
这里【莫生气】给了一个思路和代码:
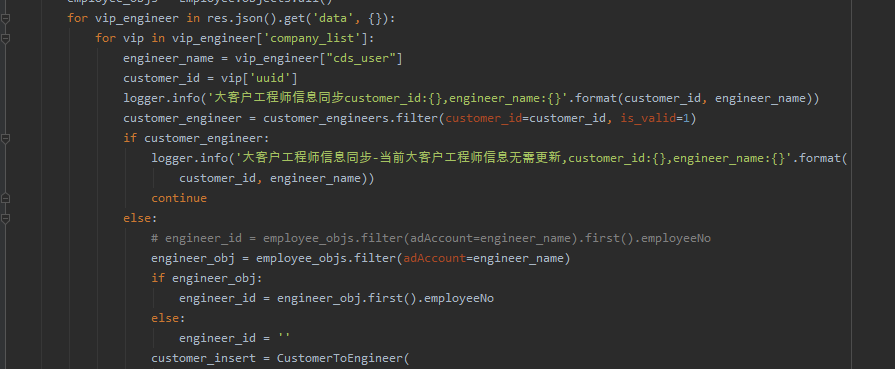
# 删除Column1中包含'cherry'的行
df = df[~df['Column1'].str.contains('电力')]经过点拨,顺利地解决了粉丝的问题。后来粉丝增加了难度,问题如下:但如果我同时要想删除包含电力与电梯,这两个关键的,又该怎么办呢?
这里【莫生气】和【FANG.J】继续给出了答案,可以看看上面的这个写法,中间加个&符号即可。代码如下:df = df[~df['col1'].str.contains('电力|电梯')]。
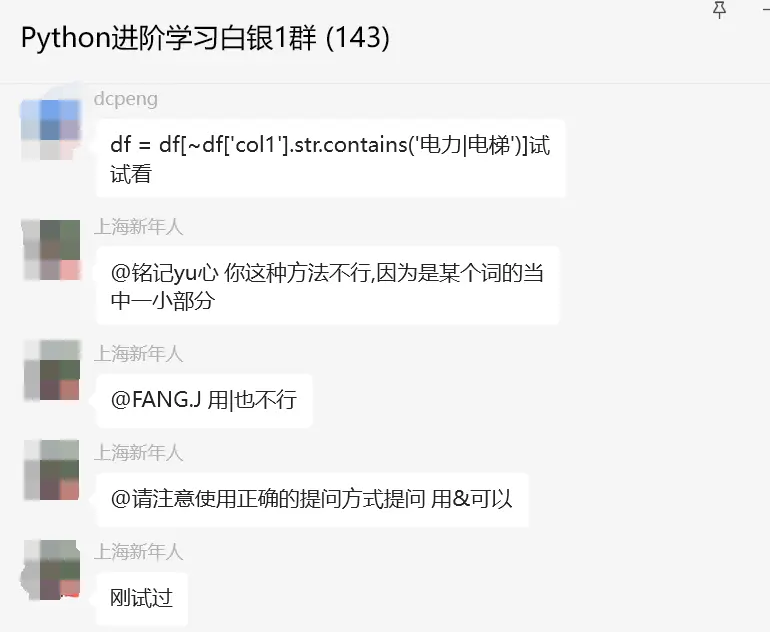
顺利地解决了粉丝的问题。
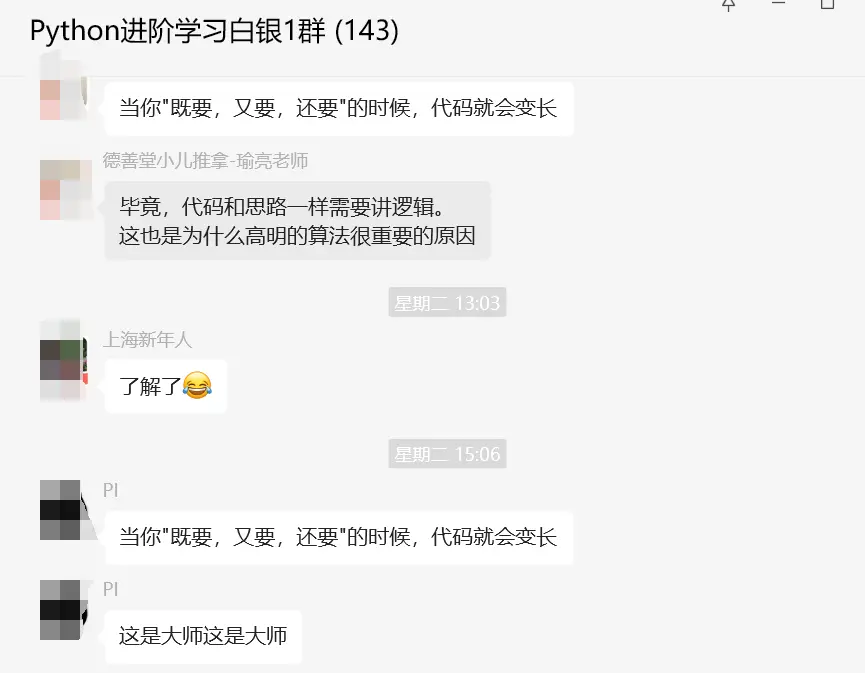
但是粉丝还有其他更加复杂的需求,其实本质上方法就是上面提及的,如果你想要更多的话,可以考虑下从逻辑 方面进行优化,如果没有的话,正向解决,那就是代码的堆积。这里给大家分享下【瑜亮老师】的金句:当你"既要,又要,还要"的时候,代码就会变长。
【Python自动化高效办公超入门】大家好,我是Python进阶者,很多粉丝有自动化办公的需求,在此我和【吴老板】、【月神】大佬合力共著一本Python自动化高效办公书籍,目前已经正式上市了,欢迎大家订阅,请大家多多支持,谢谢~
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas数据处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【上海新年人】提出的问题,感谢【莫生气】、【FANG.J】、【瑜亮老师】给出的思路,感谢【PI】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。