

对于 MySQL,要记住、或者要放在你随时可以找到的地方的两张图,一张是 MySQL 架构图,另一张则是 InnoDB 架构图:
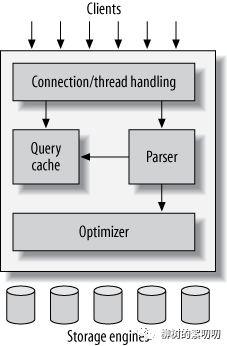
遇到问题,或者学习到新知识点时,就往里套,想一想,这是对应这两张图的哪个模块、是属于具体哪个成员的能力。
这其中,第一张图的最底下的存储引擎层(Storage Engines),它决定了 MySQL 会怎样存储数据,怎样读取和写入数据,也在很大程度上决定了 MySQL 的读写性能和数据可靠性。
对于这么重要的一层能力,MySQL 提供了极强的扩展性,你可以定义自己要使用什么样的存储引擎:InnoDB、MyISAM、MEMORY、CSV,甚至可以自己开发一个存储引擎然后使用它。
我一直觉得 MySQL 的设计,是教科书式的,高内聚松耦合,边界明确,职责清晰。学习 MySQL,学的不只是如何更好的使用 MySQL,更是学习如何更好的进行系统设计。
通常我们说 Mysql 高性能高可靠,都是指基于 InnoDB 存储引擎的 Mysql,所以,这一讲,先让我们来看看,除了 redo log,InnoDB 里还有哪些成员,他们都有什么能力,承担了什么样的角色,他们之间又是怎么配合的?
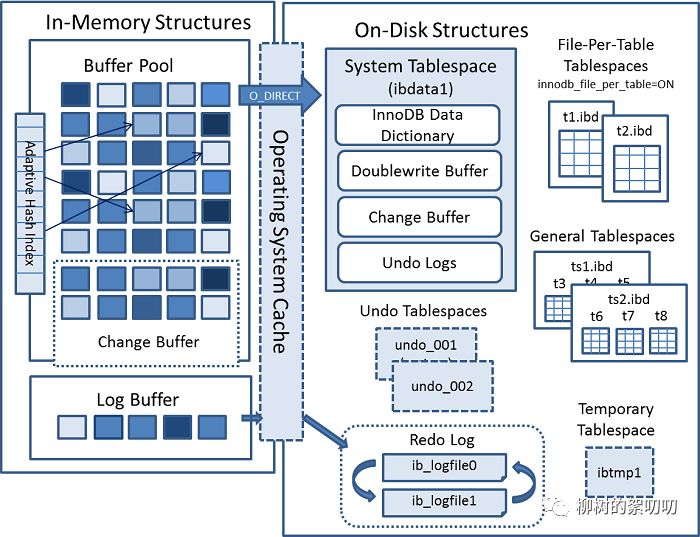
InnoDB 内存架构
从上面第二张图可以看到,InnoDB 主要分为两大块:
InnoDB In-Memory Structures
InnoDB On-Disk Structures
内存和磁盘,让我们先从内存开始。
1、Buffer Pool
The buffer pool is an area in main memory where InnoDB caches table and index data as it is accessed.
正如之前提到的,MySQL 不会直接去修改磁盘的数据,因为这样做太慢了,MySQL 会先改内存,然后记录 redo log,等有空了再刷磁盘,如果内存里没有数据,就去磁盘 load。
而这些数据存放的地方,就是 Buffer Pool。
我们平时开发时,会用 redis 来做缓存,缓解数据库压力,其实 MySQL 自己也做了一层类似缓存的东西。
MySQL 是以「页」(page)为单位从磁盘读取数据的,Buffer Pool 里的数据也是如此,实际上,Buffer Pool 是a linked list of pages,一个以页为元素的链表。
为什么是链表?因为和缓存一样,它也需要一套淘汰算法来管理数据。
Buffer Pool 采用基于 LRU(least recently used) 的算法来管理内存:
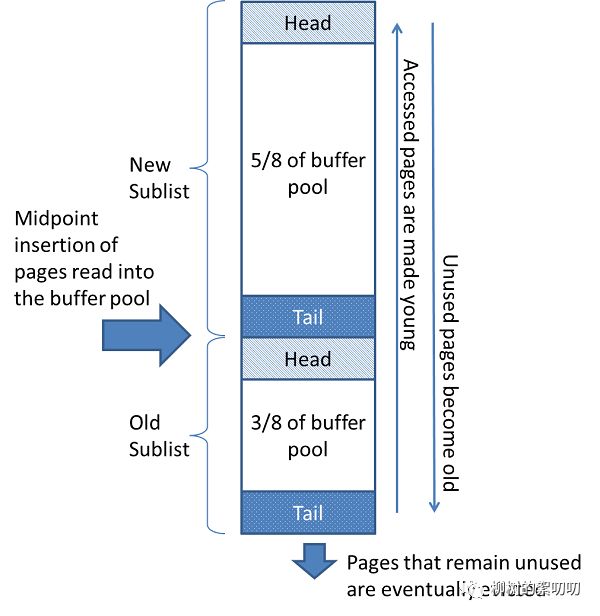
关于 Buffer Pool 的更多知识,诸如如何配置大小、如何监控等等:Buffer Pool
2、Change Buffer
上面提到过,如果内存里没有对应「页」的数据,MySQL 就会去把数据从磁盘里 load 出来,如果每次需要的「页」都不同,或者不是相邻的「页」,那么每次 MySQL 都要去 load,这样就很慢了。
于是如果 MySQL 发现你要修改的页,不在内存里,就把你要对页的修改,先记到一个叫 Change Buffer 的地方,同时记录 redo log,然后再慢慢把数据 load 到内存,load 过来后,再把 Change Buffer 里记录的修改,应用到内存(Buffer Pool)中,这个动作叫做 merge;而把内存数据刷到磁盘的动作,叫 purge:
merge:Change Buffer -> Buffer Pool
purge:Buffer Pool -> Disk
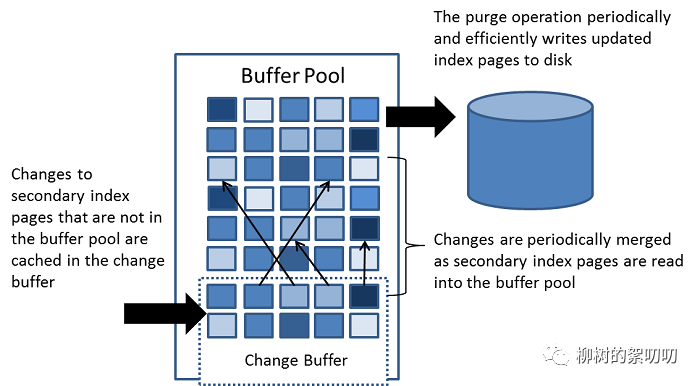
The change buffer is a special data structure that caches changes to secondary index pages when those pages are not in the buffer pool. The buffered changes, which may result from INSERT, UPDATE, or DELETE operations (DML), are merged later when the pages are loaded into the buffer pool by other read operations.
上面是 MySQL 官网对 Change Buffer 的定义,仔细看的话,你会发现里面提到:Change Buffer 只在操作「二级索引」(secondary index)时才使用,原因是「聚簇索引」(clustered indexes)必须是「唯一」的,也就意味着每次插入、更新,都需要检查是否已经有相同的字段存在,也就没有必要使用 Change Buffer 了;另外,「聚簇索引」操作的随机性比较小,通常在相邻的「页」进行操作,比如使用了自增主键的「聚簇索引」,那么 insert 时就是递增、有序的,不像「二级索引」,访问非常随机。
如果想深入理解 Change Buffer 的原理,除了 MySQL 官网的介绍:Change Buffer,还可以阅读下《MySQL技术内幕》的「2.6.1 - 插入缓冲」章节,里面会从 Change Buffer 的前身 —— Insert Buffer 开始讲起,很透彻。
3、Adaptive Hash Index
MySQL 索引,不管是在磁盘里,还是被 load 到内存后,都是 B+ 树,B+ 树的查找次数取决于树的深度。你看,数据都已经放到内存了,还不能“一下子”就找到它,还要“几下子”,这空间牺牲的是不是不太值得?
尤其是那些频繁被访问的数据,每次过来都要走 B+ 树来查询,这时就会想到,我用一个指针把数据的位置记录下来不就好了?
这就是「自适应哈希索引」(Adaptive Hash Index)。自适应,顾名思义,MySQL 会自动评估使用自适应索引是否值得,如果观察到建立哈希索引可以提升速度,则建立。
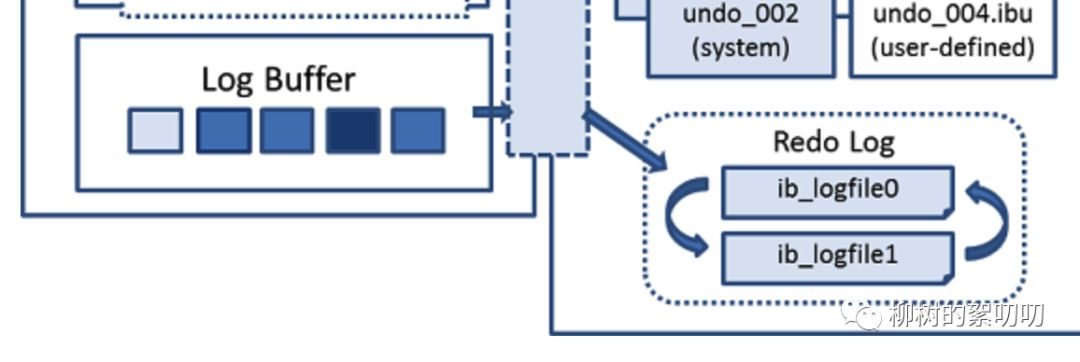
4、Log Buffer
The log buffer is the memory area that holds data to be written to the log files on disk.
从上面架构图可以看到,Log Buffer 里的 redo log,会被刷到磁盘里:
Operating System Cache
在内存和磁盘之间,你看到 MySQL 画了一层叫做 Operating System Cache 的东西,其实这个不属于 InnoDB 的能力,而是操作系统为了提升性能,在磁盘前面加的一层高速缓存,这里不展开细讲,感兴趣的同学可以参考下维基百科:Page Cache
InnoDB 磁盘架构
磁盘里有什么呢?除了表结构定义和索引,还有一些为了高性能和高可靠而设计的角色,比如 redo log、undo log、Change Buffer,以及 Doublewrite Buffer 等等.
有同学会问,那表的数据呢?其实只要理解了 InnoDB 里的所有表数据,都以索引(聚簇索引+二级索引)的形式存储起来,就知道索引已经包含了表数据。
1、表空间(Tablespaces)
从架构图可以看到,Tablespaces 分为五种:
The System Tablespace
File-Per-Table Tablespaces
General Tablespace
Undo Tablespaces
Temporary Tablespaces
其中,我们平时创建的表的数据,可以存放到 The System Tablespace 、File-Per-Table Tablespaces、General Tablespace 三者中的任意一个地方,具体取决于你的配置和创建表时的 sql 语句。
这里同样不展开,如何选择不同的表空间存储数据?不同表空间各自的优势劣势等等,传送门:Tablespaces
2、Doublewrite Buffer
如果说 Change Buffer 是提升性能,那么 Doublewrite Buffer 就是保证数据页的可靠性。
怎么理解呢?
前面提到过,MySQL 以「页」为读取和写入单位,一个「页」里面有多行数据,写入数据时,MySQL 会先写内存中的页,然后再刷新到磁盘中的页。
这时问题来了,假设在某一次从内存刷新到磁盘的过程中,一个「页」刷了一半,突然操作系统或者 MySQL 进程奔溃了,这时候,内存里的页数据被清除了,而磁盘里的页数据,刷了一半,处于一个中间状态,不尴不尬,可以说是一个「不完整」,甚至是「坏掉的」的页。
有同学说,不是有 Redo Log 么?其实这个时候 Redo Log 也已经无力回天,Redo Log 是要在磁盘中的页数据是正常的、没有损坏的情况下,才能把磁盘里页数据 load 到内存,然后应用 Redo Log。而如果磁盘中的页数据已经损坏,是无法应用 Redo Log 的。
所以,MySQL 在刷数据到磁盘之前,要先把数据写到另外一个地方,也就是 Doublewrite Buffer,写完后,再开始写磁盘。Doublewrite Buffer 可以理解为是一个备份(recovery),万一真的发生 crash,就可以利用 Doublewrite Buffer 来修复磁盘里的数据。
留个问题,有了 Doublewrite Buffer 后,不就意味着 MySQL 要写两次磁盘?性能岂不是很差?
未完待续
让我们再来回顾一下这张图:
这篇文章,顺着这张图,给大家介绍了 InnoDB 里的每一个成员、成员各自扮演的角色、提供的能力。
当然,这张图里能表达的信息是有限的,我习惯称这种图为「架构图」,或者「模块图」。
用 DDD 的话来讲,这张图可以告诉你,MySQL 里有哪些「域」(子域、核心域、通用域、支撑域),配合文字介绍,可以知道这些「域」之间都有什么样的能力、行为,知道「域」之间一些简单的交互。
然而,这张图并没有告诉你具体某个业务中,这些成员之间要如何配合,来提供一个服务,或者说,如果你的技术方案里只有这张图,那你进入开发阶段后,最多最多,只能新建几个微服务应用,新建几个类和对象,而写不出这些个微服务、class 之间如何协作起来提供一个服务的代码。
所以,下一篇文章,将基于我们这篇文章以及上一篇文章的内容,画出一张足以描述具体业务流程的图。
什么样的图有这种描述力呢?
自然是 swim-lanes,也就是我们常说的「泳道图」。
在那之后,我们将深入到每一个细分领域,以及具体到一些实际问题中,来把 MySQL 彻底学透。
参考
The InnoDB Storage Engine
《MySQL技术内幕》
丁奇:MySQL实战45讲
本文分享自微信公众号 - 三太子敖丙(JavaAudition)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。













