
参考文章:
https://blog.csdn.net/tiantianw/article/details/53334566
http://www.cnblogs.com/luyucheng/p/6265594.html
网上开启慢查询:
在[my.ini]中添加如下信息:
[mysqld]
log-slow-queries="C:/ProgramFiles/MySQL/MySQL Server 5.5/log/mysql-slow.log"
long_query_time = 4
log-queries-not-using-indexes
解释:
log-slow-queries:代表MYSQL慢查询的日志存储目录,此目录文件一定要有写权限;
Windows下需要写绝对路径,如:log-slow-queries="C:/Program Files/MySQL/MySQL Server5.5/log/mysql-slow.log"
long_query_time: 最长执行时间 (查询的最长时间,超过了这个时间则记录到日志中) .
log-queries-not-using-indexes:没有使用到索引的查询也将被记录在日志中
配置好以后重新启动MYSQL服务.
个人尝试:
1.获取当前变量信息,命令是
show variables like 'slow_query%';

slow_query_log on即表示开启记录慢sql
slow_query_log_file文件位置
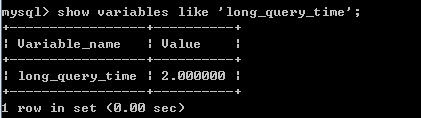
long_query_time总执行时间2.更改配置信息
set global slow_query_log='ON'; //开启记录慢sql
set global slow_query_log_file='D:/php_dev/MySQL/MySQL Server 5.5/log/slow_query.log'; //win操作系统,这个参数需要绝对路径
set global long_query_time=1; //设置慢查询时间为1秒3.如果有超出指定时间的sql,就会把sql相关信息写入
D:/php_dev/MySQL/MySQL Server 5.5/log/slow_query.log这个文件4.文件格式如下:
# Time: 190429 16:42:25
# User@Host: root[root] @ localhost [127.0.0.1]
# Query_time: 0.062400 Lock_time: 0.000000 Rows_sent: 1003 Rows_examined: 1003
SET timestamp=1556527345;
SELECT * FROM TEACHING_SYSTEM_STUDENT;
执行计划:
直接命令执行
explain
select * from student;
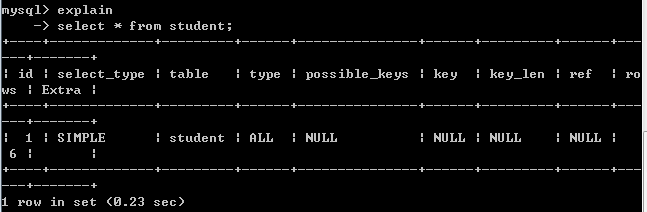
字段key判断是否使用到了索引











