
前言
当前Kubernetes(K8S)已经成为事实上的容器编排标准,大家关注的重点也不再是最新发布的功能、稳定性提升等,正如Kubernetes项目创始人和维护者谈到,Kubernetes已经不再是buzzword,当我们谈起它的时候,变得越发的boring,它作为成熟项目已经走向了IT基础设施的中台,为适应更大规模的生产环境和更多场景的应用不断延展迭代。
而现在我们更加专注于如何利用K8S平台进行CICD、发布管理、监控、日志管理、安全、审计等等。本期我们将介绍如何利用K8S中的Audit事件日志来对平台进行安全监控和审计分析。
IT设施/系统是当今每个互联网公司最为重要的资产之一,除了成本外,这里承载了所有的用户访问,同时保存了非常多的用户、订单、交易、身份等敏感信息。因此每个公司都有必要确保IT设施/系统是可靠、安全、未泄漏的。其中必不可少的环节是审计,通过审计我们可以知道系统在任一时间段内发生的事件以及对应关联的内外部人员、系统,在损失发生后能够立即知道具体是谁、在哪个时间对系统做了什么事,同时基于审计事件的实时分析和告警,能够提前发现问题并及时止损。
Kubernetes审计日志概览
Kubernetes作为容器编排领域的领导者、未来PAAS平台的标准基座,在IT领域有着举足轻重的影响,因此审计功能也是Kubernetes比不可少的安全功能之一。
Kubernetes在1.7版本中发布了审计(Audit)日志功能,审计(Audit)提供了安全相关的时序操作记录(包括时间、来源、操作结果、发起操作的用户、操作的资源以及请求/响应的详细信息等),通过审计日志,我们能够非常清晰的知道K8S集群到底发生了什么事情,包括但不限于:
- 当前/历史上集群发生了哪些变更事件。
- 这些变更操作者是谁,是系统组件还是用户,是哪个系统组件/用户。
- 重要变更事件的详细内容是什么,比如修改了POD中的哪个参数。
- 事件的结果是什么,成功还是失败。
- 操作用户来自哪里,集群内还是集群外。

日志格式与策略
K8S中的审计日志是标准的JSON格式,APIServer会根据具体的日志策略将对应的审计日志保存本地,并可以设置最大保存周期、时间、轮转策略等。
关于审计日志格式和策略的详细介绍,可以参考Audit官方文档。
日志记录阶段
审计日志根据日志策略可以选择在事件执行的某个阶段记录,目前支持的事件阶段有:
RequestReceived- 接收到事件且在分配给对应handler前记录。ResponseStarted- 开始响应数据的Header但在响应数据Body发送前记录,这种一般应用在持续很长的操作事件,例如watch操作。ResponseComplete- 事件响应完毕后记录。Panic- 内部出现panic时记录。
日志记录等级
审计日志根据日志策略可以选择事件保存的等级,根据等级不同,APIServer记录日志的详细程度也不同。目前支持的事件等级有:
None- 不记录日志.Metadata- 只记录Request的一些metadata (例如user, timestamp, resource, verb等),但不记录Request或Response的body。Request- 记录Request的metadata和body。RequestResponse- 最全记录方式,会记录所有的metadata、Request和Response的Body。
日志记录策略
APIServer支持对每类不同的资源设置不同的审计日志策略,包括日志记录阶段以及日志记录等级,目前官方以及很多云厂商都会提供日志策略,一般都遵循以下原则:
- 在收到请求后不立即记录日志,当返回体header发送后才开始记录。
- 对于大量冗余的kube-proxy watch请求,kubelet和system:nodes对于node的get请求,kube组件在kube-system下对于endpoint的操作,以及apiserver对于namespaces的get请求等不作审计。
- 对于/healthz_,/version_, /swagger*等只读url不作审计。
- 对于可能包含敏感信息或二进制文件的secrets,configmaps,tokenreviews接口的日志等级设为metadata,该level只记录请求事件的用户、时间戳、请求资源和动作,而不包含请求体和返回体。
- 对于一些如authenticatioin、rbac、certificates、autoscaling、storage等敏感接口,根据读写记录相应的请求体和返回体。
审计日志分析
审计日志分析现状
目前对于K8S上的APIServer审计日志的支持,大部分厂商还停留在策略设置或日志采集的阶段,最多只支持将数据采集到日志中心,配合索引进行关键词查询。
下图是一个Level为Metadata的审计日志记录,各类字段有20多个,如果是Level为Request或RequestResponse的日志字段会更多,可能达到上百个。要实现审计日志分析,必须理解这些字段的含义,此外还需理解每个字段的取值范围以及每种取值对应的含义,学习代价非常之大。
{
"kind": "Event",
"apiVersion": "audit.k8s.io/v1beta1",
"metadata": {
"creationTimestamp": "2019-01-14T07:48:38Z"
},
"level": "Metadata",
"timestamp": "2019-01-14T07:48:38Z",
"auditID": "cf2915c0-0b43-4e1d-9d66-fbae481a0e0a",
"stage": "ResponseComplete",
"requestURI": "/apis/authentication.k8s.io/v1beta1?timeout=32s",
"verb": "get",
"user": {
"username": "system:serviceaccount:kube-system:generic-garbage-collector",
"uid": "cd3fbe04-0508-11e9-965f-00163e0c7cbe",
"groups": [
"system:serviceaccounts",
"system:serviceaccounts:kube-system",
"system:authenticated"
]
},
"sourceIPs": [
"192.168.0.249"
],
"responseStatus": {
"metadata": {},
"code": 200
},
"requestReceivedTimestamp": "2019-01-14T07:48:38.214979Z",
"stageTimestamp": "2019-01-14T07:48:38.215102Z",
"annotations": {
"authorization.k8s.io/decision": "allow",
"authorization.k8s.io/reason": "RBAC: allowed by ClusterRoleBinding \"system:discovery\" of ClusterRole \"system:discovery\" to Group \"system:authenticated\""
}
}
阿里云Kubernetes审计日志方案
为尽可能减少用户对于审计日志的分析代价,阿里云容器服务将Kubernetes审计日志与日志服务SLS打通,推出了一站式的Kubernetes审计日志方案,让每个用户都能够以图形化报表的方式进行集群的审计分析。
- 为尽可能保证集群安全性,阿里云容器服务Kubernetes默认为用户打开了APIServer审计日志并设置了较为安全且通用的审计日志策略,所有(符合审计策略)用户、组件对APIServer的访问都会被记录下来;
- Kubernetes集群中预置的日志组件Logtail会将APIServer的审计日志自动采集到阿里云日志服务;
- 日志服务默认会为APIServer的审计日志创建索引、报表等;
- 容器服务控制台已经和日志服务打通,集群管理员可以直接在控制台上查看审计日志的各项报表以及指标;
- 若集群管理员还有设置告警、自定义分析等需求,可直接登录日志服务控制台进行操作。
得益于阿里云日志服务的强大功能,该方案不仅大大降低了K8S审计日志分析的门槛,从分析能力、可视化、交互方式、性能等各方面都具有很强的优势:
审计日志方案概览
审计报表
我们默认为Kubernetes集群创建了3个报表,分别是审计中心概览、资源操作概览和资源详细操作列表:
审计中心概览展示Kubernetes集群中的事件整体概览信息以及重要事件(公网访问、命令执行、删除资源、访问保密字典等)的详细信息。
资源操作概览展示Kubernetes集群中常见的计算资源、网络资源以及存储资源的操作统计信息,操作包括创建、更新、删除、访问。其中
- 计算资源包括:Deployment、StatefulSet、CronJob、DaemonSet、Job、Pod;
- 网络资源包括:Service、Ingress;
- 存储资源包括:ConfigMap、Secret、PersistentVolumeClaim。
资源详细操作列表用于展示Kubernetes集群中某类资源的详细操作列表,通过选择或输入指定的资源类型进行实时查询,该表报会显示:资源操作各类事件的总数、namespace分布、成功率、时序趋势以及详细操作列表等。
所有的报表均支持设置时间范围、子账号ID、Namespace等进行自定义过滤并实时刷新,通过这些报表,集群管理员只用点击鼠标就可以获取到:
- 最近任一时间段内创建/删除/修改了哪些资源;
- 事件的时序趋势如何;
- 具体是哪个子账号操作了资源;
- 操作的IP源是否为公网、地域分布如何、来源IP是否高危;
- 具体操作的事件ID、时间、结果、涉及的资源等详细日志;
- 哪个子账号登录了容器或访问了保密字典...
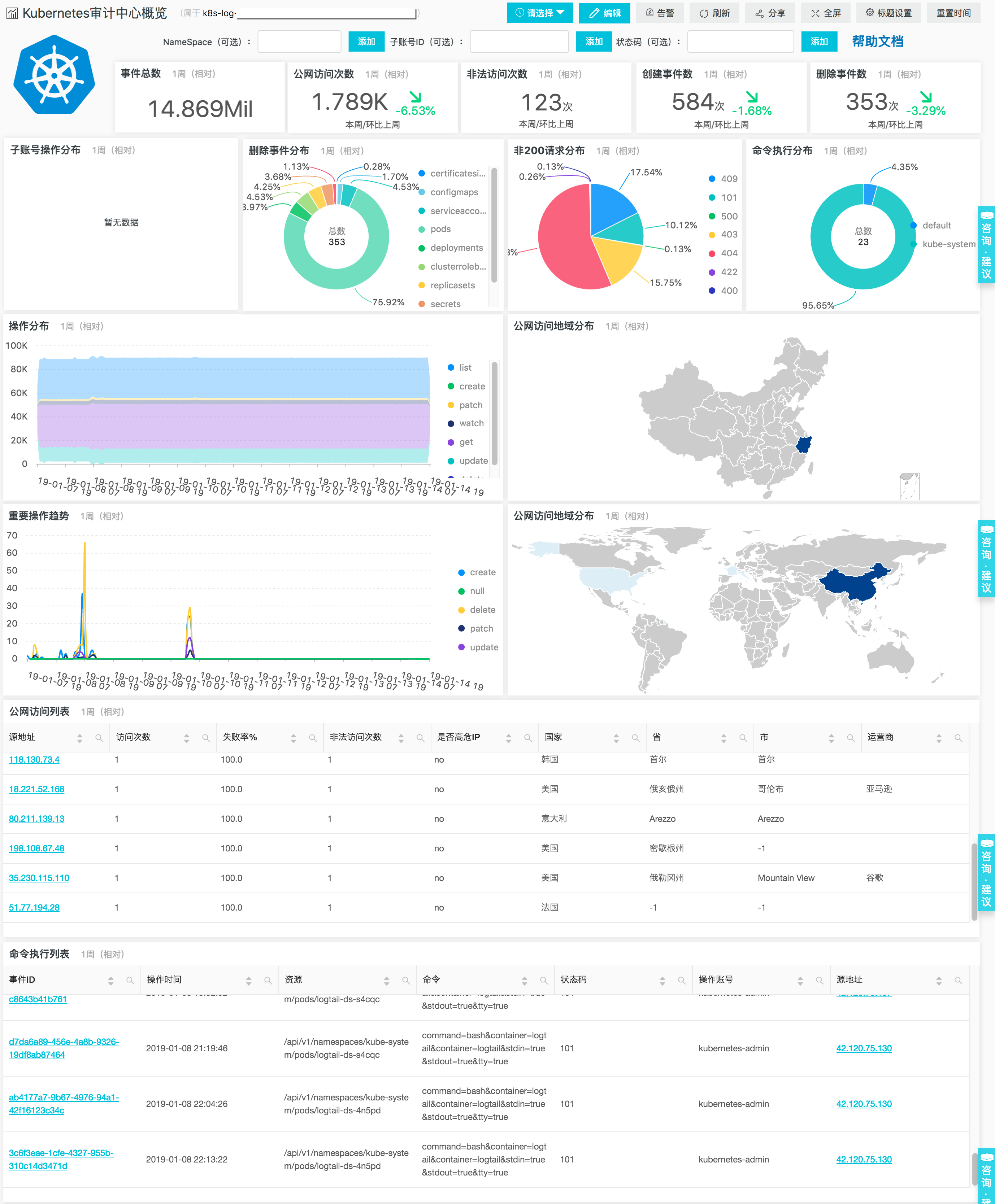

这里我们选择一个图标做详细说明:上图是Kubernetes资源操作列表,这个报表完全是交互式的,用户可以指定一种资源(比如Deployment、Ingress、Secret等),表报会自动渲染出关于这个资源的所有操作,功能包括:
- 左上角会显示对这个资源操作的用户数、涉及Namespace数、涉及方法数、请求成功率等概览信息;
- 每种不同操作(增、删、改、查)的数量以及Namespace分布,用来确定涉及的Namespace;
- 各类操作的时序分布(按小时),数量较多的点一般都是发布或系统被攻击的时间点;
- 各类操作的详细列表,包括:事件ID、操作事件、操作资源、操作结果、账号、地址;
- 图表中所有的事件ID都可以点击并跳转到原始的日志,查看具体和这个事件ID关联的详细日志;
- 图表中所有的IP地址都可以点击并跳转到外部的IP查询库,查询该IP对应的地理位置、运营商等信息;
- 图表还支持根据账号、namespace、请求码等过滤,比如对某个用户进行审计时,可以过滤子账号,只关心该用户的操作。
自定义告警
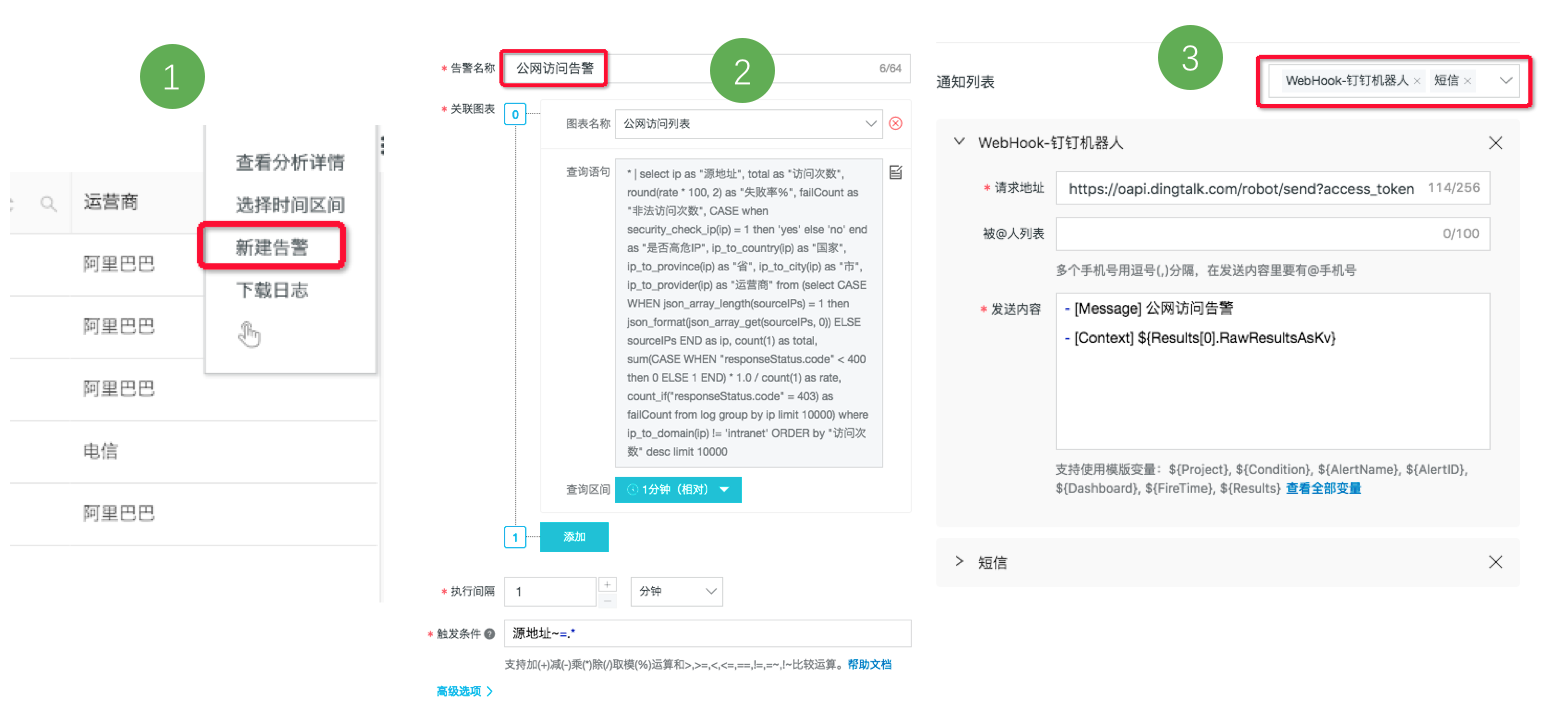
例如需要对公网访问设置告警策略:出现公网访问时立即告警,则只需3步就可完成设置:
- 在审计报表的公网访问图表中点击右上角高级选项-新建告警
- 填入告警名称、事件、判断条件
- 填入告警通知方式以及通知内容
自定义分析
如果容器服务Kubernetes版提供的默认报表无法满足您的分析需求,可以直接使用日志服务SQL、仪表盘等功能进行自定义的分析和可视化。
尝鲜
为了让大家可以体验Kubernetes审计日志功能,我们特别开通了体验中心,大家可以通过 https://promotion.aliyun.com/ntms/act/logdoclist.html 进入,该页面提供了非常多和Kubernetes相关的报表。












