
向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
一.DBnet
提出了 Differentiable Binarization (DB),它可以在分割网络中执行二值化过程,可以自适应地设置二值化阈值,不仅简化了后处理,而且提高了文本检测的性能。
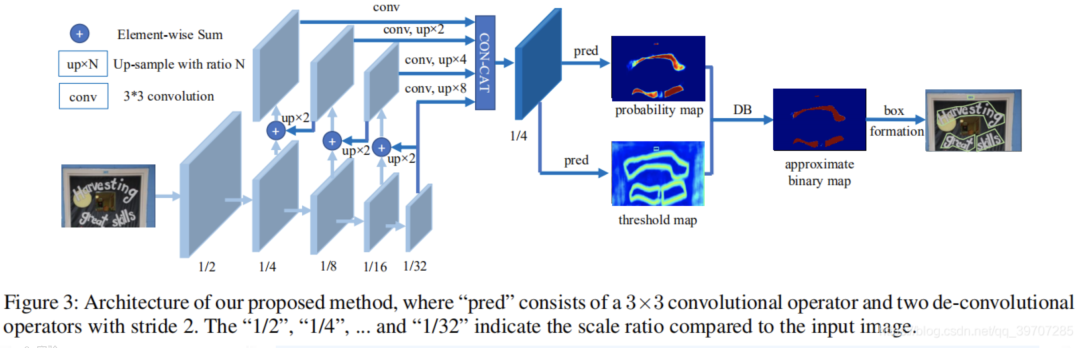

在训练阶段,对概率图、阈值图和近似二值图进行监督,其中概率图和近似二值图共用一个监督。在推理过程中,通过一个box公式化模块,可以很容易地从近似二值图或概率图中得到文本包围框。
可微分二值化

一般的分割模型都是对最终的输出结果取一个固定阈值进行二值化,本文创新点在于将二值化的阈值进行学习,如上图的(a)所示

加入可微分模块,就可以把阈值进行训练,能够更好区分前后景与粘连文本.
P:probability map
T:threshold map
B^:approximate binary map
Loss函数:

loss主要三部分:Ls是收缩之后文本实例的loss, Lb是二值化之后的收缩文本实例loss, Lt是二值化阈值map的loss, Ls和Lb都使用带OHEM的bceloss, Lt使用L1loss。
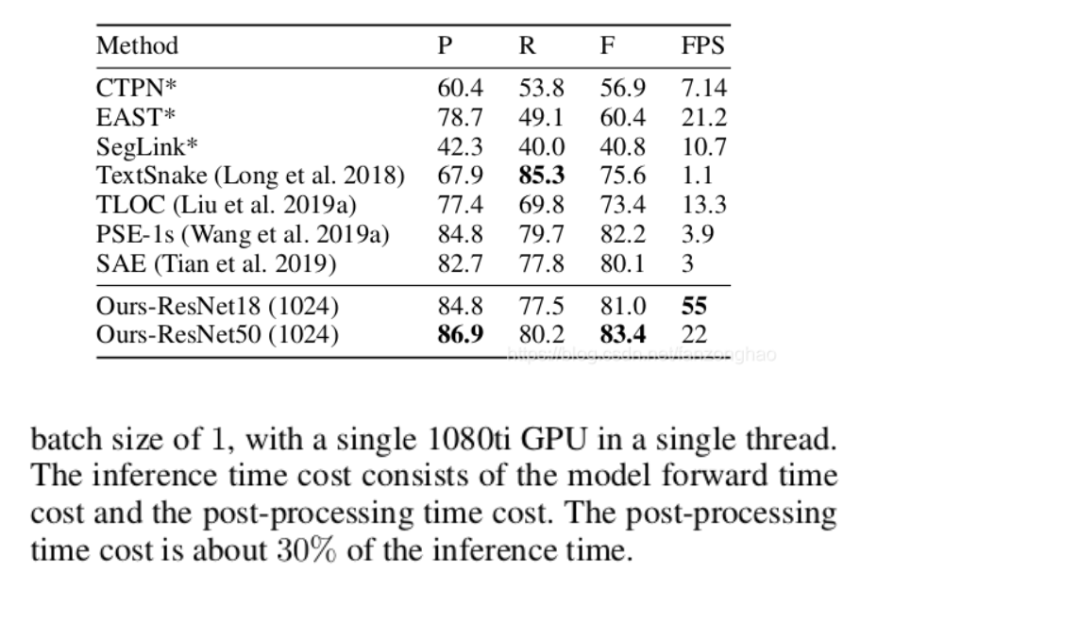
注意的是论文给的速度只是包含前向传播和后处理,所以实际上包含预处理,速度没这么快的.
二.知识蒸馏

其中T是温度,直接使用softmax层的输出值作为soft target, 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。T很大时就能软化softmax的输出概率, 分布越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。也就是从有部分信息量的负标签中学习 --> 温度要高一些,防止受负标签中噪声的影响 -->温度要低一些。
思路:采用resnet50(teacher)先训练,在利用训练好的resnet50(teacher)对resnet18(student)小模型进行联合训练,实验证明f1score比单独训练resnet18涨一个点。
项目 获取方式
关注微信公众号 datayx 然后回复 DB检测 即可获取。
AI项目体验地址 https://loveai.tech
三.torch模型->onnx->tensorrt
思路:采用torch.onnx将.pth转成.onnx格式,在用tensorrt推理。代码见github中的model_to_onnx.py.
四.一些效果展示
文字检测

条形码检测



原文地址 https://blog.csdn.net/fanzonghao/article/details/107199538
阅读过本文的人还看了以下文章:
**基于40万表格数据集TableBank,用MaskRCNN做表格检测
**
**【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
**
**《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
**
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

机大数据技术与机器学习工程
搜索公众号添加: datanlp

长按图片,识别二维码
本文分享自微信公众号 - 机器学习AI算法工程(datayx)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












