
在日志收集服务器上使用Flume(1.6)的Kafka Sink将日志数据发送至Kafka,在Flume Agent启动之后,发现每个Agent的CPU使用率都非常高,而我们需要在每台机器上启动多个Flume Agent来收集不同类型的日志,如果每个Agent都这样,那肯定会把机器的CPU吃满了,刚开始使用jstack定位到是org.apache.flume.sink.kafka.process()的问题,后来google了下,果然是这个代码有问题。找到一个ISSUES: https://issues.apache.org/jira/browse/FLUME-2632
发现该问题在Flume1.7中fix掉了,接着找到github中Flume1.7的代码,具体就是:
使用该代码编译后替换掉flume-ng-kafka-sink-1.6.0.jar中的KafkaSink.class,重启Flume Agent之后,问题解决。
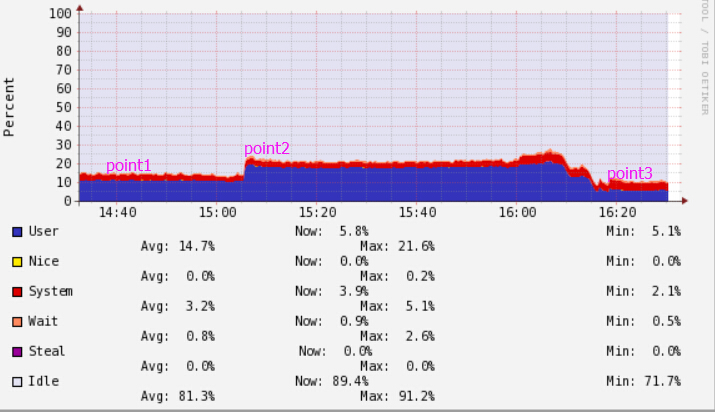
图中point1是运行了一个flume agent;
在point2时刻,我启动了第二个flume agent,CPU一下上来一截;
在point3时候,我使用fix之后的flume-ng-kafka-sink-1.6.0.jar,前后重启了两个flume agent,CPU使用率下降了很多。
接下来继续观察CPU使用情况以及收集的数据是否异常。











