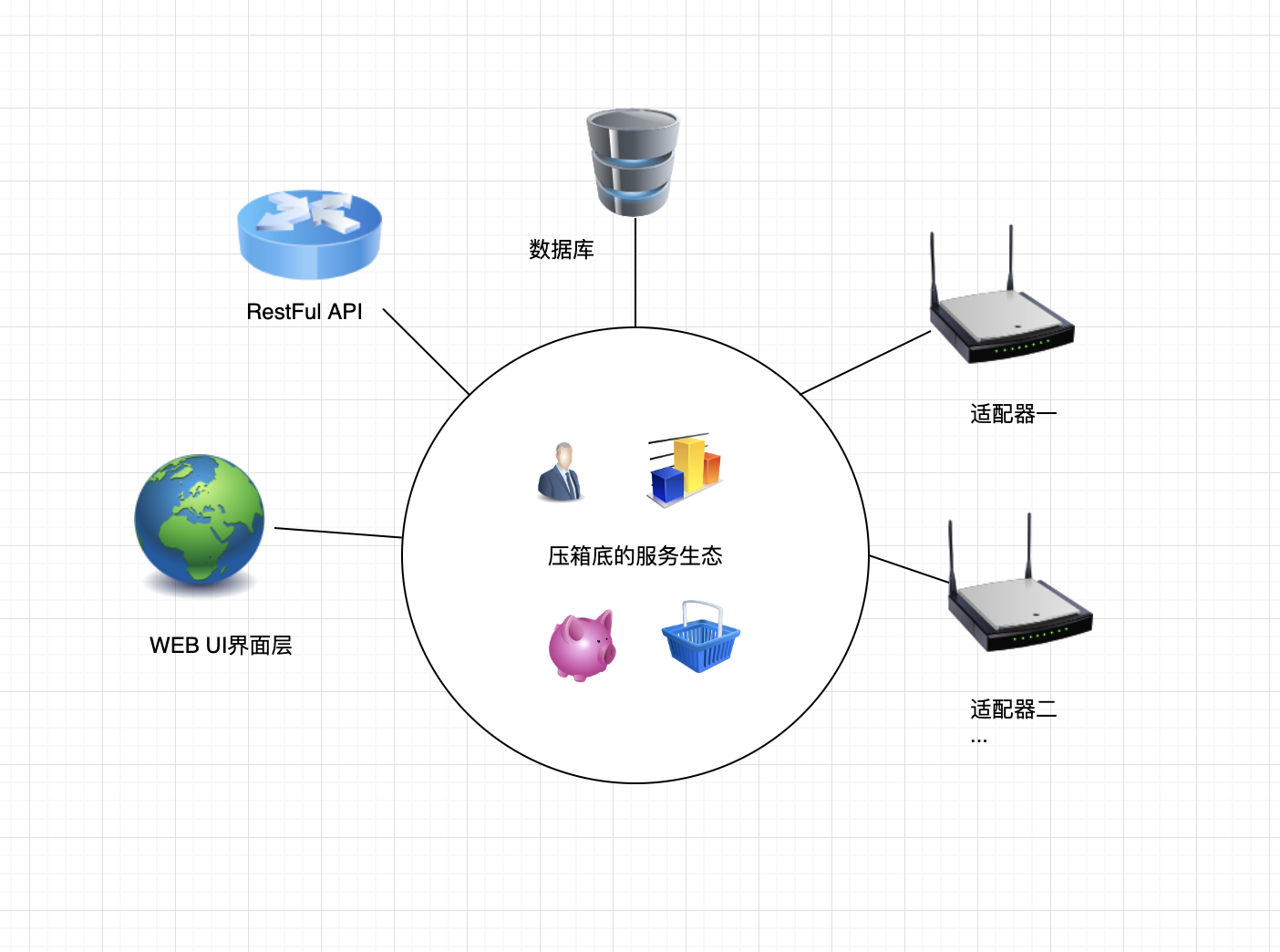
近几年随着Docker容器技术、微服务等架构的兴起,人们开始意识到服务发现的必要性。微服务架构简单来说,是一种以一些微服务来替代开发单个大而全应用的方法, 每一个小服务运行在自己的进程里,并以轻量级的机制来通信, 通常是 HTTP RESTful API。微服务强调小快灵, 任何一个相对独立的功能服务不再是一个模块, 而是一个独立的服务。那么,当我们需要访问这个服务时,如何确定它的地址呢?这时就需要服务发现了。
Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。通常拿来和zookeeper、etcd这些服务注册与发现的工具进行比较。Consul更像一个“全栈”解决方案,内置了服务注册与发现,具有健康检查、Key/Value存储、多数据中心的功能。个人比较偏爱他有三点:1、开箱即用,方便运维:安装包仅包含一个可执行文件,方便部署,无需其他依赖,与Docker等轻量级容器可无缝配合 。2、自带ui界面,可以通过web界面直接看到注册的服务,更新K/V。3、采用GOSSIP协议进行集群内成员的管理和消息的传播,使用和etcd一样的raft协议保证数据的一致性。
Consul提供的四个关键特性:
1、服务发现。提供HTTP和DNS两种发现方式。
2、健康监测。支持多种方式,HTTP、TCP、Docker、Shell脚本定制化监控。
3、KV存储。Key、Value的存储方式。
4、多数据中心。Consul支持多数据中心。
当然Consul还有很多锦上添花的特性,比如:可视化Web界面、配置模板“consul-template”等。
以下是consul ui的页面展示:
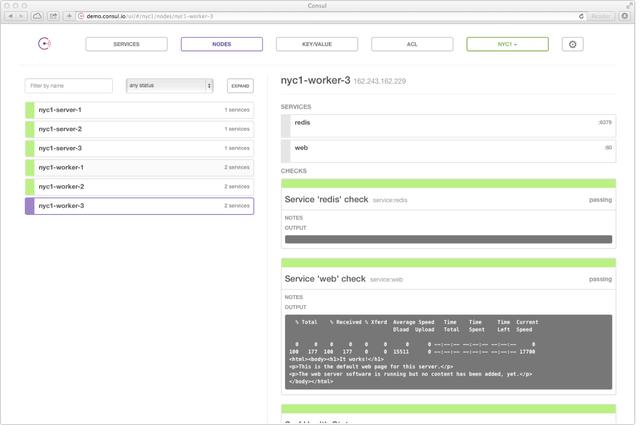
consul ui界面
Consul集群的搭建
集群架构示意图:
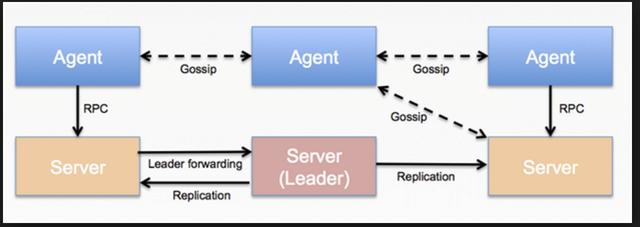
consul cluster架构
集群角色
上图是一个简单的consul cluster的架构,Consul Cluster有Server和Client两种角色。不管是Server还是Client,统称为Agent,Consul Client是相对无状态的,只负责转发RPC到Server,资源开销很少。Server是一个有一组扩展功能的代理,这些功能包括参与Raft选举,维护集群状态,响应RPC查询,与其他数据中心交互WAN gossip和转发查询给leader或者远程数据中心。
在每个数据中心,client和server是混合的。一般建议有3-5台server。这是基于有故障情况下的可用性和性能之间的权衡结果,因为越多的机器加入达成共识越慢,Server之间会选举出一个leader。然而,并不限制client的数量,它们可以很容易的扩展到数千或者数万台。
集群搭建
这里以5台机器搭建一个server集群,分别为:
172.30.100.1 consul01
172.30.100.2 consul02
172.30.100.3 consul03
172.30.100.4 consul04
172.30.100.5 consul05
1、创建consul安装目录,这里放到/data/consul目录下:
root@consul01# mkdir -p /data/consul/data
2、下载对应平台和版本的consul软件包并解压,这里以0.9.2版本为例:
root@consul01# cd /data/consul
root@consul01# wget -c https://releases.hashicorp.com/consul/0.9.2/consul\_0.9.2\_linux\_amd64.zip
root@consul01# unzip consul_0.9.2_linux_amd64.zip
3、创建consul的启动配置文件:
root@consul01# vim consul_config.json
{
"datacenter": "consul-cluster",
"node_name": "consul01",
"bind_addr": "172.30.100.1",
"client_addr": "172.30.100.1",
"server": true,
"bootstrap_expect": 5,
"data_dir": "/data/consul/data",
"http_config": {
"response_headers": {
"Access-Control-Allow-Origin": "*"
}
},
"log_level": "INFO",
"enable_syslog": true,
"ports": {
"http": 8500,
"dns": 8600,
"serf_lan": 8301,
"serf_wan": 8302
},
"enable_script_checks": true
}
关键参数解释:
bind_addr: 同命令行的-bind参数,内部集群通信绑定的地址。默认是‘0.0.0.0’,如果有多块网卡,需要指定,否则启动报错
client_addr:同命令行的-clinet参数,客户端接口绑定的地址,默认是‘127.0.0.1’;
server:true指定consul agent的模式为server模式;
bootstrap_expect:同命令行的-bootstrap-expect,集群预期的server个数,这里我们有5台server,设置为5;不能和 bootstrap参数一同使用。
enable_syslog:启用则consul的日志会写进系统的syslog里;
enable_script_checks:是否启用监控检测脚本。
详细配置参数解释见官方链接:https://www.consul.io/docs/agent/options.html
其他4个节点的配置,把node_name更改为自己的即可。
4、启动consul agent
root@consul01# ./consul agent -config-file consul_config.json -ui
指定配置文件位置,并启动ui界面。在其他四个节点进行相同的操作
5、把agent加入到集群
告诉第二个agent,加入到第一个agent里:
root@consul02# ./consul join -http-addr http://172.30.100.2:8500 172.30.100.1
在其余3个节点上,更改自己的http-addr,执行相同的操作,比如在consul03上执行:
root@consul03# ./consul join -http-addr http://172.30.100.3:8500 172.30.100.1
特别提示:加入集群的时候,一个consul agent只需要知道集群中任意一个节点即可,加入到集群之后,集群节点之间会根据GOSSIP协议互相发现彼此的关系。
5、集群检查
所有节点都启动成功之后可以查看集群成员是否全部加入成功,任意节点上执行命令:
root@consul03# ./consul members http://172.30.100.3:8500
Node Address Status Type Build Protocol DC
consul01 172.30.100.1:8301 alive server 0.9.2 2 consul-cluster
consul02 172.30.100.2:8301 alive server 0.9.2 2 consul-cluster
consul03 172.30.100.3:8301 alive server 0.9.2 2 consul-cluster
consul04 172.30.100.4:8301 alive server 0.9.2 2 consul-cluster
consul05 172.30.100.5:8301 alive server 0.9.2 2 consul-cluster
6、登陆WEB UI