
几乎所有玩ARM Cortex M单片机的坛友都是通过MDK Keil 5或者IAR环境进行单片机的程序开发的,俗话说工欲善其事必先利其器,我们天天都在用这个开发环境,那么,有些在MDK Keil 5中的实用功能小技巧,大家又知道多少呢?
1.并不是所有源文件(.c)都需要加进工程中,只需要添加必要的源文件即可。无论是什么开发环境,只要是C/C++的工程,工程编译时间的决定因素就是工程中的源文件,以STM32 HAL库的工程为例,单片机外设的驱动文件一般是【stm32fxxx_hal_xxx.c】的格式,里面有多少个这样的源文件,就代表这个工程启用了多少个STM32单片机的外设。我们可以做个对比:
我们使用STM32CubeMX生成一个工程,工程用到了外部高频、低频晶振、SPI1、USART1,CubeMX自动生成的工程里面,源文件只有必要的十来个:
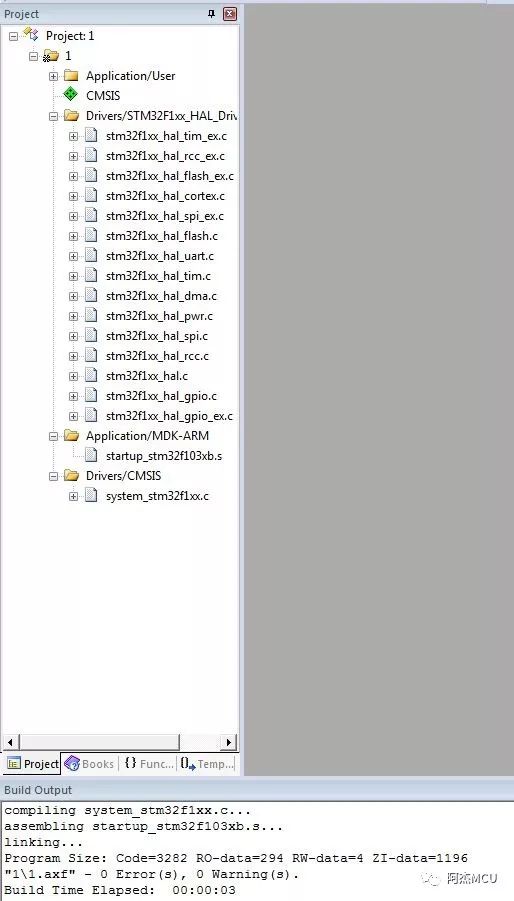
然后我们把一些不必要用到的源文件也加进去,我这里索性把CubeF1固件库里面的全部外设驱动都加进去了,甚至包括一些完全没有必要加进去的template.c模版:
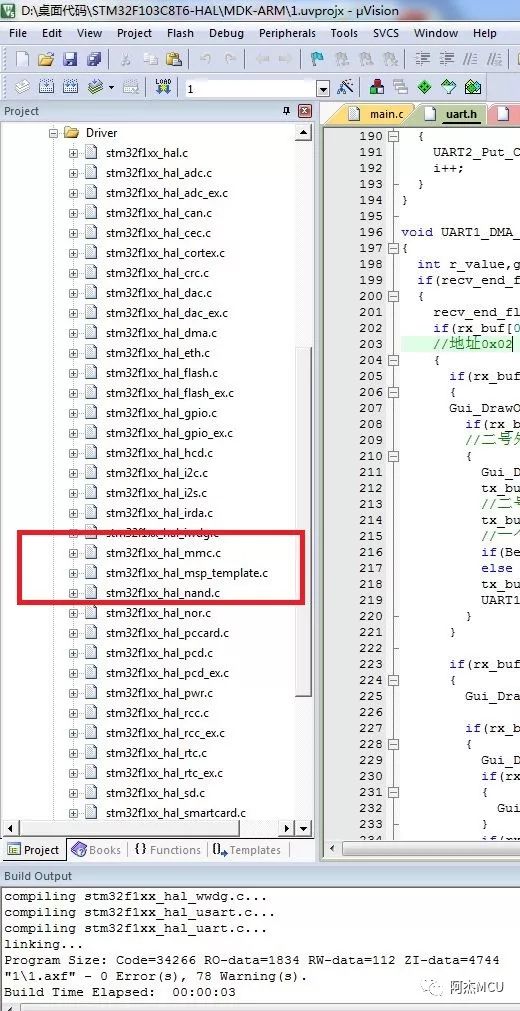
可以看到,生成的Code大小差得非常远,我这里还是用ARMCCV6版本的编译器,还看不出前后两个工程的编译时间,如果是用ARMCCV5版本的,估计时间要差好几倍。实际上前后两个工程,实现的效果完全是一样的,那些原本没有必要加进去的源文件,除了浪费编译空间和编译时间以外,没有任何用处。
2.头文件(.h)可以随便加进工程中。在MDK的代码开发工程中,头文件是必不可少的。头文件在工程的作用是提供宏定义/常量、结构体声明、枚举量声明统一放置的地方、函数的声明(甚至可以直接把函数的实现写在头文件里面,没有任何问题)。在实际的开发过程中,经常要频繁修改宏定义,而传统MDK开发者的习惯一般是工程只添加源文件而不添加头文件,这样就使得修改宏定义变得非常麻烦了,我们应该摒弃这个习惯,把频繁使用的头文件加进工程中。
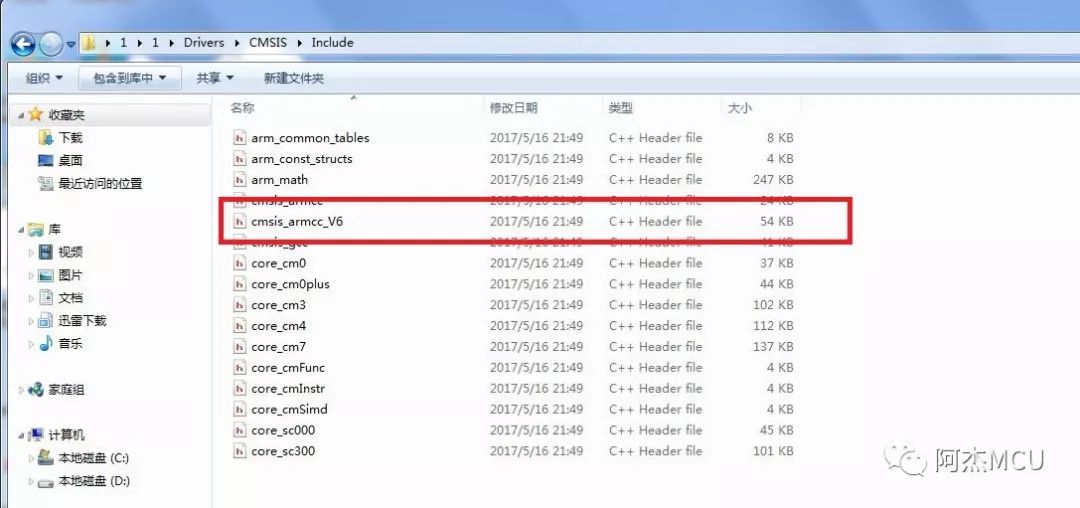
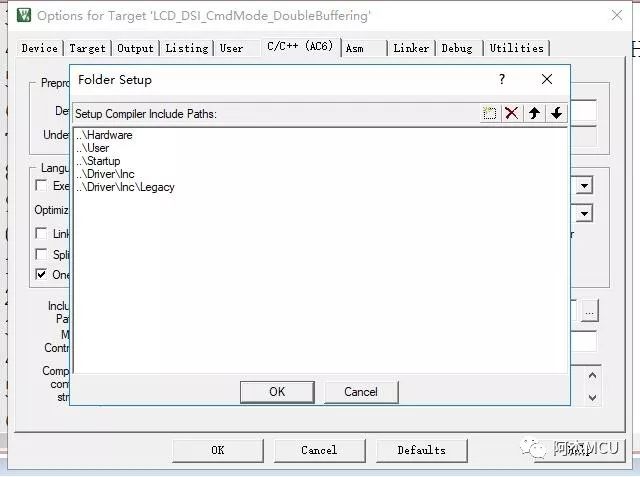
3.编译器版本选V6。在MDK 5.24和MDK 5.25中,有个非常重要的更新,那就是MDK开始逐步支持完善ARMCC_V6编译器了。在以前的5.20以下的版本中,时常听说大佬们有用ARMCC_V6编译器的,但大多都是放礼**,按照例程走也是一大堆报错,真正能实现的没几个,而从5.24版本开始,MDK使用V6编译器一般不会再出现报错了。使用V6编译器的步骤:
1)添加cmsis_armcc_V6.h头文件进我们的工程中,并设置包含路径;
2)工程的Tatget选项卡的编译器版本选V6.9;
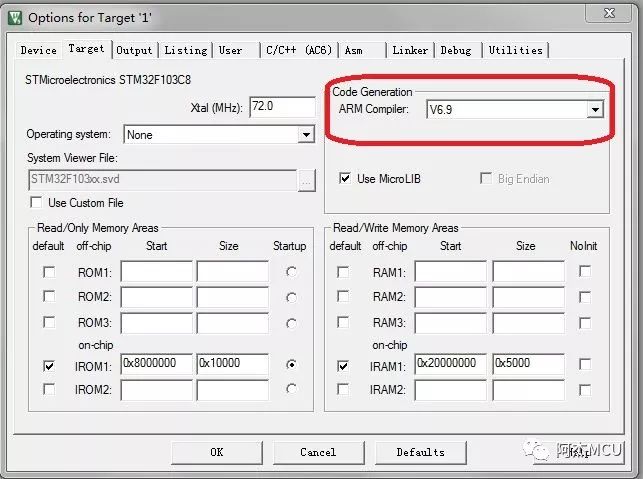
3)Misc Controls留空,C语言和C++语言都选gnu11版本,优化等级随意,没有关系;
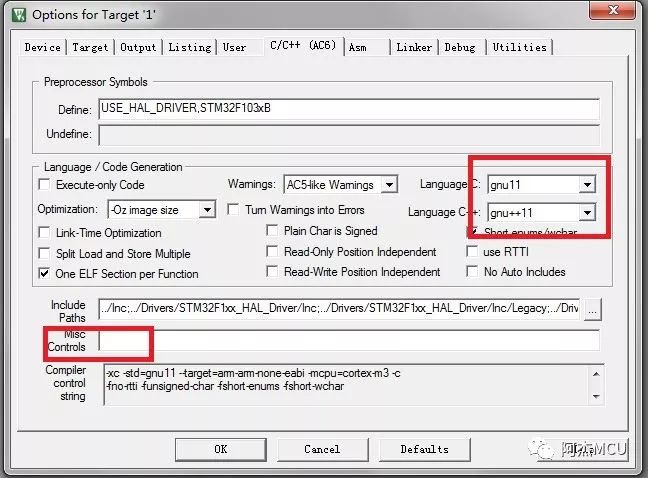
这样,MDK使用V6编译器编译工程就没有任何问题了。
4.生成bin文件。MDK还有一个重要的功能就是生成bin文件,直接在工程的User选项卡下面的After Build里面添加一行【fromelf.exe --bin -o
"$L@L.bin" "#L"】:
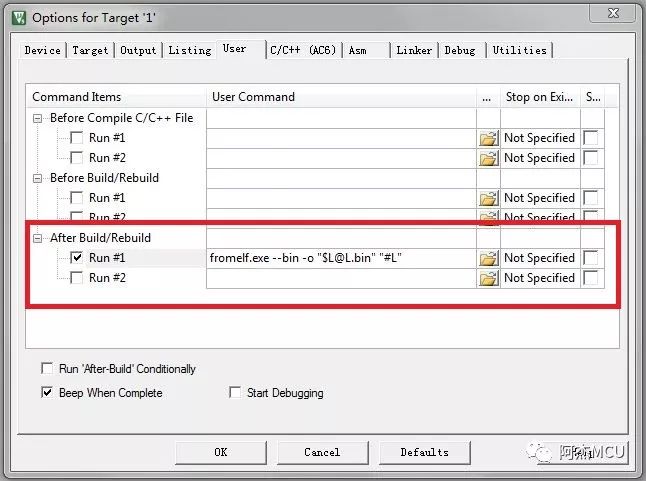
工程编译输出如下信息即代表bin文件成功生成:

在工程文件的目录下可看到与工程文件同名的bin文件:

5.注释与缩进快捷键
MDK Keil 5中一个非常实用的新功能:批量注释/取消注释和代码批量缩进/后退。如果需要把一大段代码全部注释掉,只需要点一个按钮便可。


6.一级文件目录
MDK的工程,说到底是由众多的头文件和源文件组成的,这些头文件和源文件被分装在了不同的目录,MDK工程通过链接这些文件夹目录来找到对应的源文件和头文件。可是,在ST官方的例程中,头文件,源文件,库文件,启动文件放在了多层混乱的目录中,虽说官方这样做的目的是为了更好地对驱动文件进行分类和管理,但对于我们开发者来说,要移植他们官方的例程,真的不是一件容易的事,我就放几张截图看看官方的例程是怎么存放工程文件和驱动文件的:
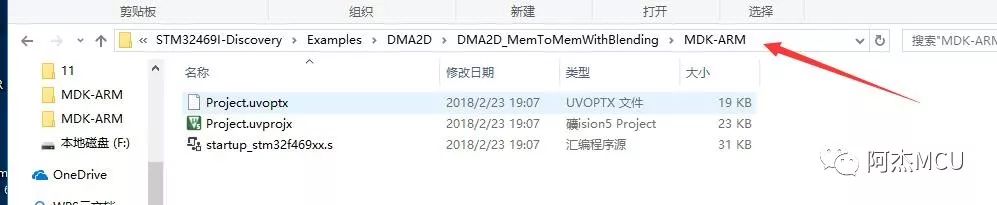
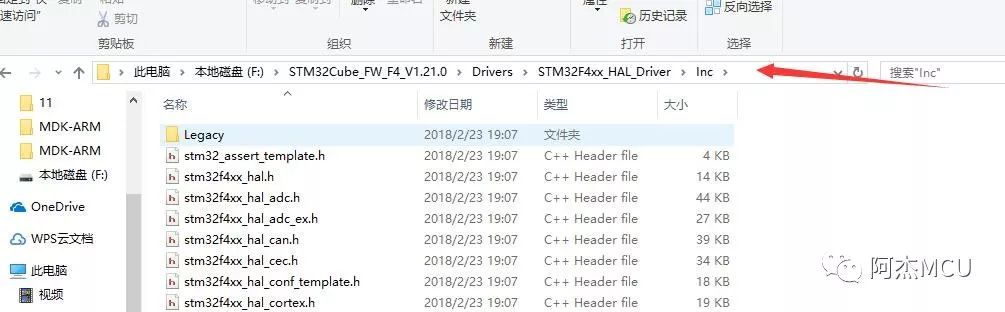
反观原子的例程,除了个别第三方库如DSP和FATFS是二级目录外,只有一级目录,结构清晰:
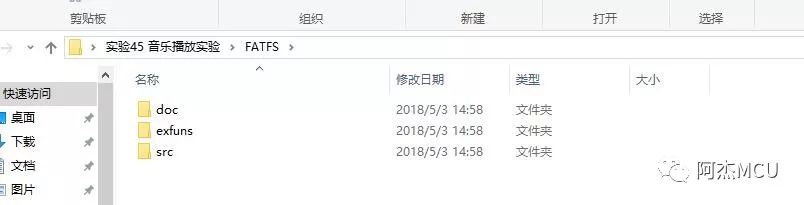
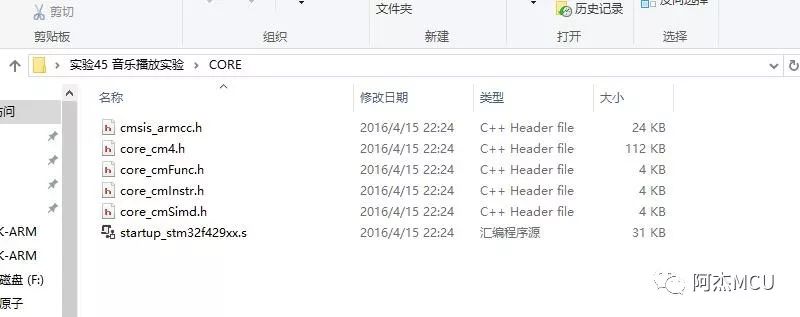

我们应该提倡在MDK里面只使用一级目录,无论是文件查找还是例程移植,都非常方便:
7.使能MicroLIB
在MDK中有一个跟标准C库非常接近的功能,那就是MicroLIB,在工程配置菜单里面可以找到这个设置:
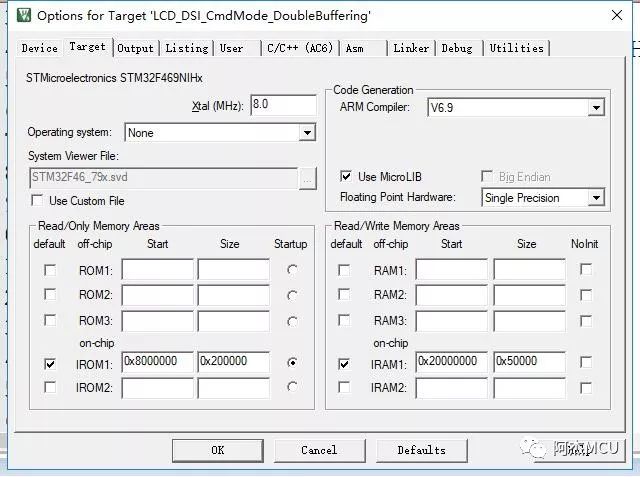
这个库是缺省标准C库的备选库,选上这个之后,可以用标准C库的一些经过简化的库函数,如fputc memcpy等等,其中最常用的当然是fputc了,这个函数写好之后可以直接用printf函数打印数据,外设可以是串口,也可以是显示屏。
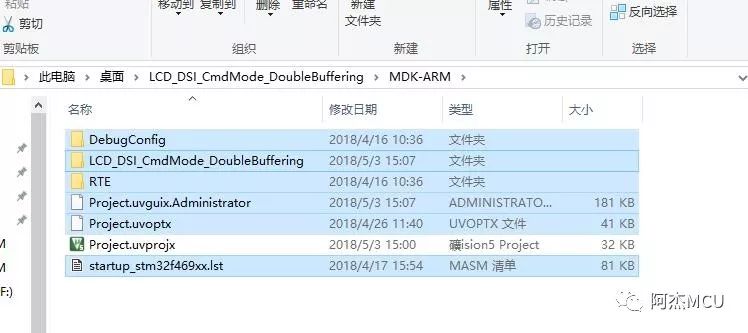
8.手动KeilKill
大家应该都知道MDK有个KeilKill脚本,这个脚本的作用是把编译生成的obj等中间文件删掉,这样工程要进行复制黏贴或是打包的时候就不会太过于占用空间,中间文件生成的大小与工程中的源文件代码量直接相关。实际上KeilKill是可以手动进行的,就是把与工程文件(.uvprojx)同一目录下的其它文件全部删除,效果与KeilKill脚本完全一样。
本文分享自微信公众号 - 嵌入式单片机之家(mcuic6666)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。














