一 登录datax可视化管理系统datax-web
网址:http://127.0.0.1:8080/index.html (根据实际地址填写,url中必须带/index.html)
默认用户名/密码:admin/123456
登录后
二 使用操作
1 项目管理
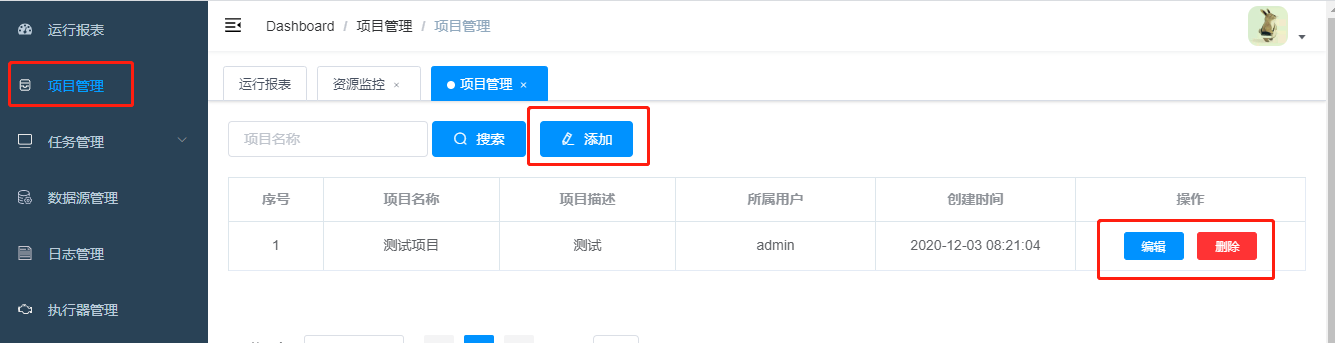
项目管理,用于对构建的job任务进行分类,此处根据实际项目创建即可。
2 执行器管理
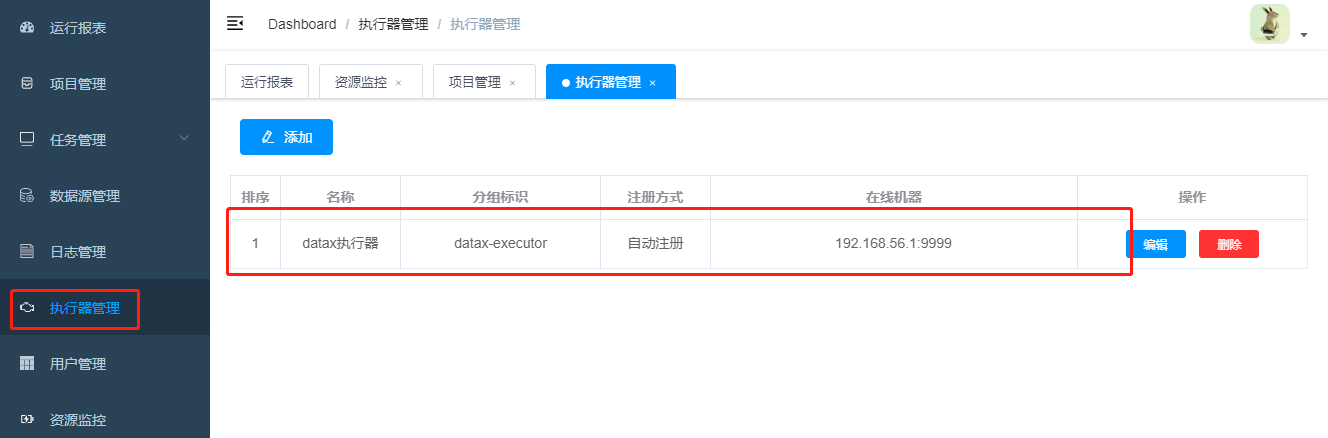
执行器会在启动时,自行注册,无需手动添加。自动注册,同时也表明管理端和执行端是连通的。不推荐手动添加,手动添加不能保证执行器是可靠的。
如果没有自动注册,则需要去检测执行器的配置及是否启动成功。
3 数据源管理
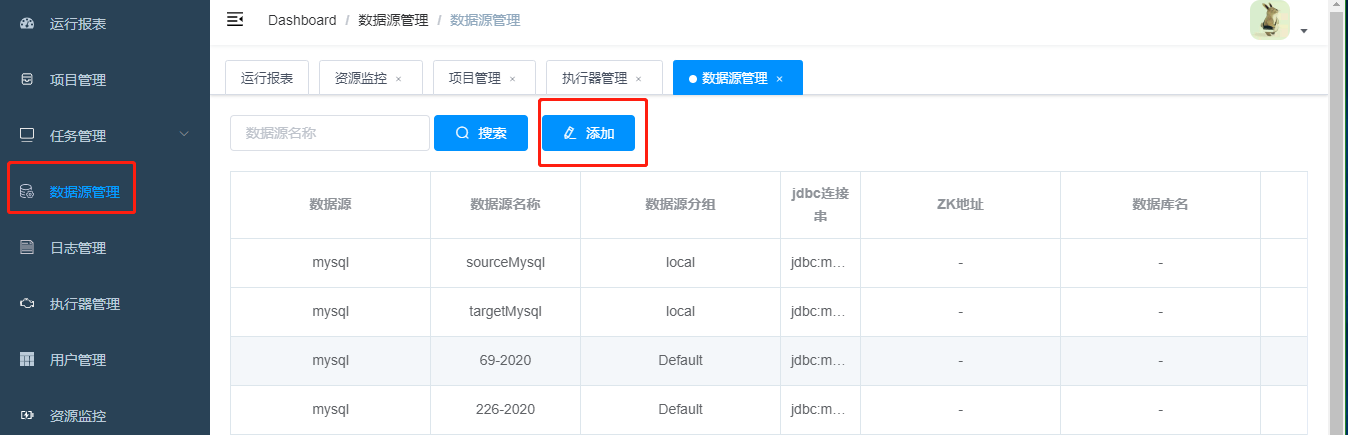
3.1 数据源说明
数据源分两种:源数据源和目标数据源
源数据源是指:数据抽取来源的数据库
目标数据源:数据最后插入的目的地数据库。
比如:从SqlServer 同步数据到 mysql。
这里SqlServer就是源数据库,mysql就是目标数据库。
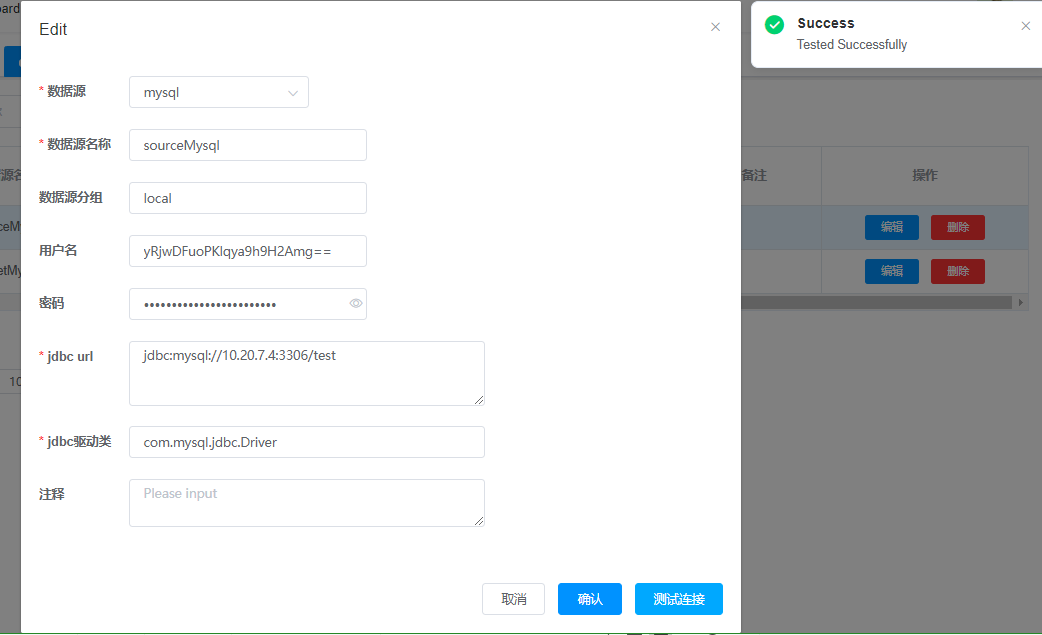
3.2 数据源添加
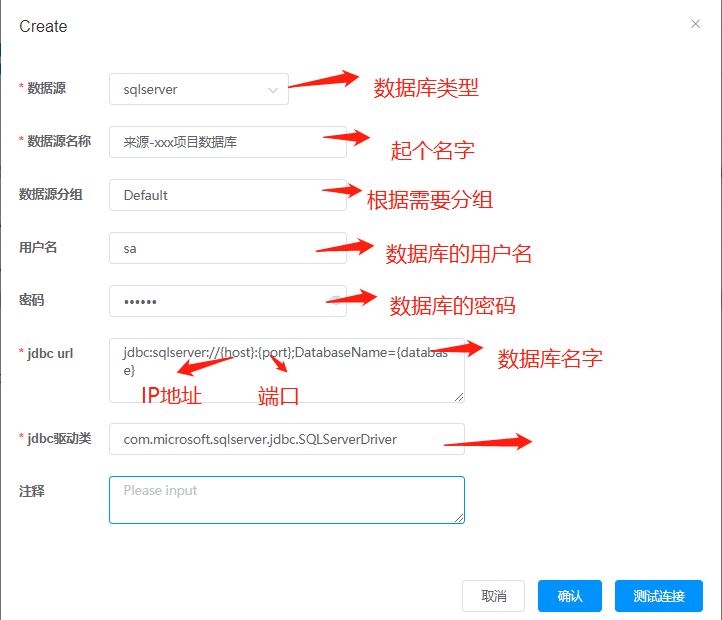
驱动程序不用修改,默认即可。点击“测试连接”,连接成功,保存即可。如果连接不上,查找具体原因,修改相应参数。
例子:mysql
4 任务管理-DataX任务模板
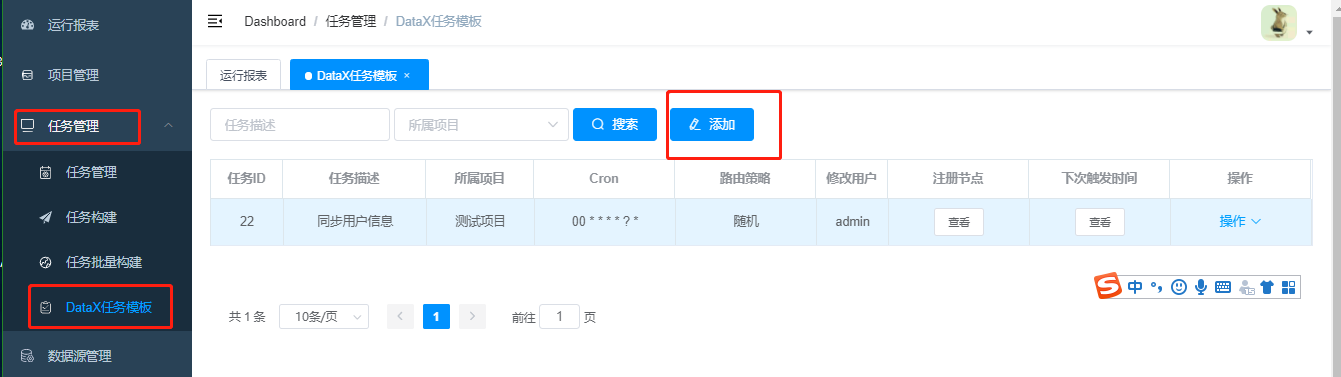
任务模板配置好之后,供“任务构建”阶段选择用。
任务模板:
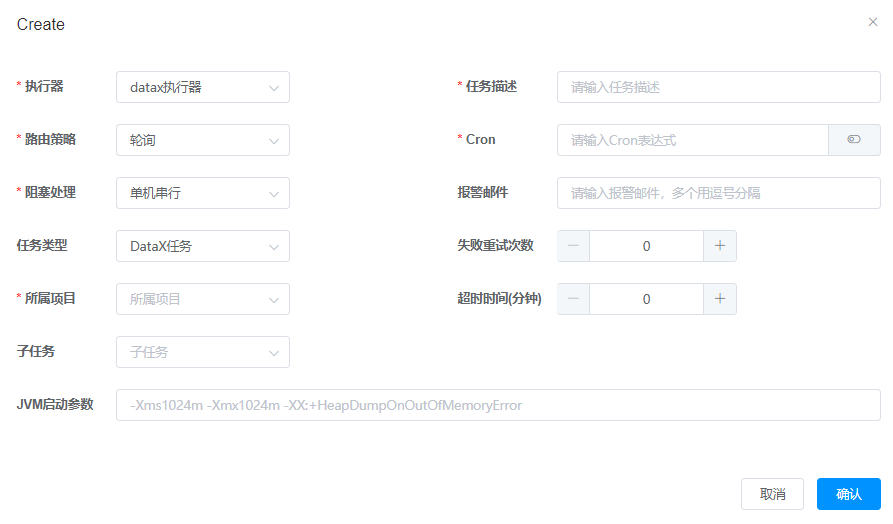
参数说明:
- 执行器:非集群模式下,执行器只有一个,即默认自动注册的那一个。
- 任务描述:为模板起个名字,最好带上执行周期。如:用户相关数据_1分钟同步一次
- 路由策略:路由策略有很多个,建议选择“轮询”,即执行器集群部署时,选择哪个执行器。轮询策略,能保证每个执行器都有机会。
- 阻塞处理:选择单机串行。任务排队,串行执行。其他处理方式都会导致有任务不执行。
- Cron表达式:根据实际要求的同步周期进行配置。要细心,容易配错。
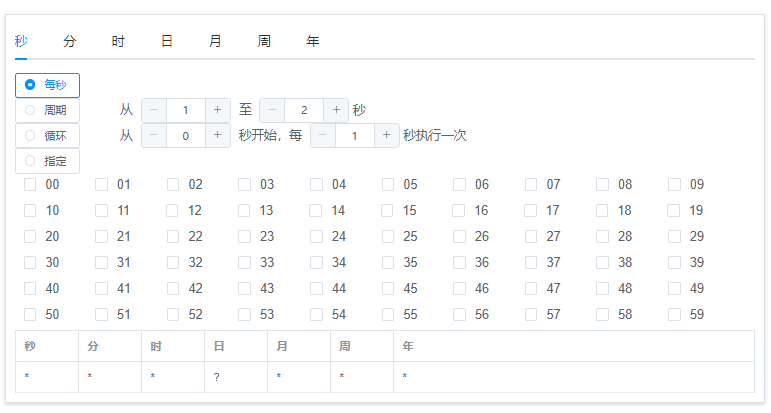
举例:周期为每分钟执行一次,如下:
秒:指定00
分:每秒
时:每小时
日:每日
周:不指定
月:每月
年:每年
翻译一下:每年每月每天每个小时每分钟的第0秒执行这个任务。
- 任务类型:选择DataX任务。
- 所属项目:根据自己的配置选择。
- 子任务:这里会显示已经配置好的其他任务。当前任务执行完成之后,会触发一次子任务执行。但是不保证子任务一定执行成功,也不会对当前任务造成影响,只是触发而已。
- Jvm启动参数:这里不用配置,除非数据量特别大。任务执行时,默认1G的jvm内存。
每个任务调度执行时,都会分配。如果配置集群,执行器的个数要小于内存总大小/1G.比如服务器内存8G,执行器个数要小于8个,最好是6个以下。因为操作系统和应用程序运行也需要内存。执行器有几个,最大并行执行任务就有几个。并行任务并不等于并发线程数。一个任务在调度执行时也可能会产生并发。
- 报警邮件、超时时间、重试次数等,根据字面意思理解,按需配置。
5 任务管理-任务构建
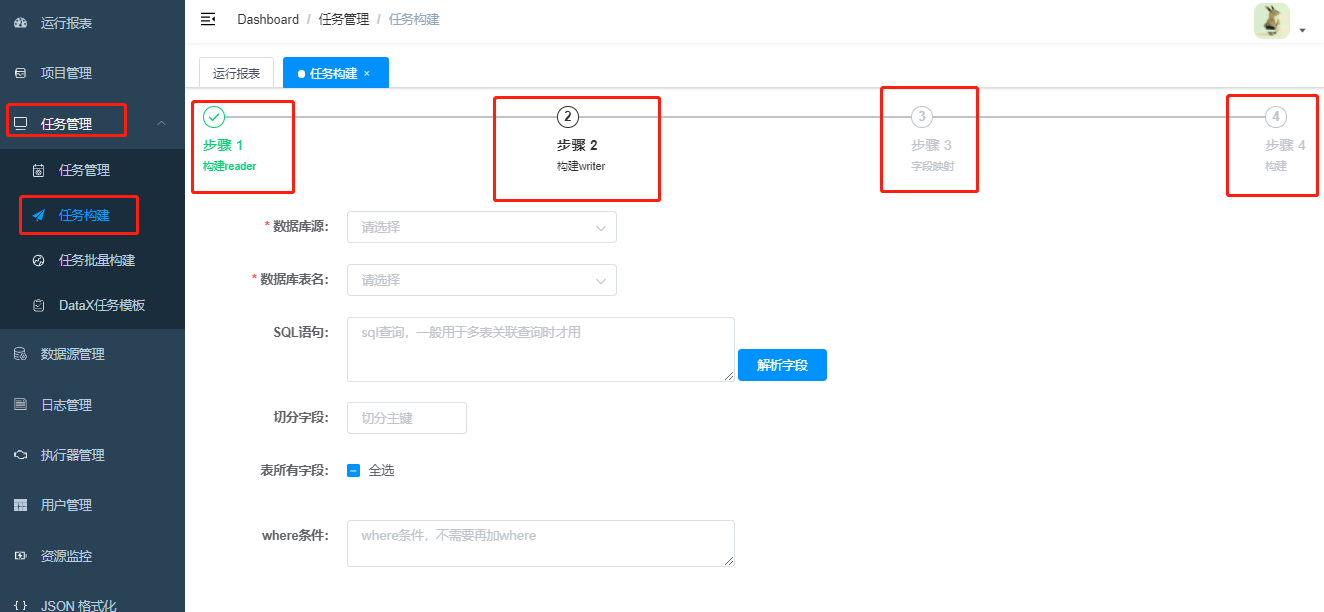
任务构建,是数据同步最核心的模块。绝大部分工作都是围绕这个模块进行了。
Datax 任务构建的目标是job.json文件,通过Datax-web可视化的四个步骤,简化了构建任务的过程,大大减少了工作量。
构建任务之前,目标数据库需要提前建立好同步需要的表结构。
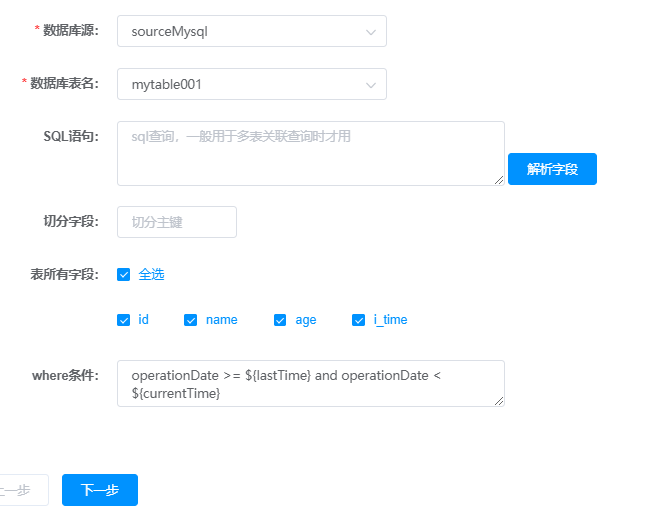
5.1 步骤1 构建reader
配置数据来源及对应的表和字段。
- 数据库源:选择数据来源,即在“数据源管理”中配置的数据源。
- 数据库表名:下拉列表,自动补全。选择本次要同步的表。
- Sql语句:如果是单表,这个地方不需要写sql。只有关联查询时才需要写。
(如果关联查询用到多张表,第二步中的数据库表名,只选择一个即可)
- 切分主键:这里要填的是主键或关联查询中确定的主键。这里填了主键后,任务执行时,会根据数据量自动对数据分片,启动多个线程并发执行。加快执行速度。数据量小,可不填。
- 表所有字段:根据需要选择。
- Where条件:如果没有条件,可不填。
如果选择“时间增量”进行增量数据抽取,这里填,operationDate >= ${lastTime} and operationDate < ${currentTime}
operationDate是表中对应的记录操作时间的字段,具体是什么,以表中的字段名为准。
${lastTime}、${currentTime} 与 配置增量更新时,写的参数一致。
如果选择“ID增量”进行增量数据抽取,这里填 id>= ${startId} and id< ${endId}
${startId} 、${endId} 与配置增量更新时写的参数一致。
举例:
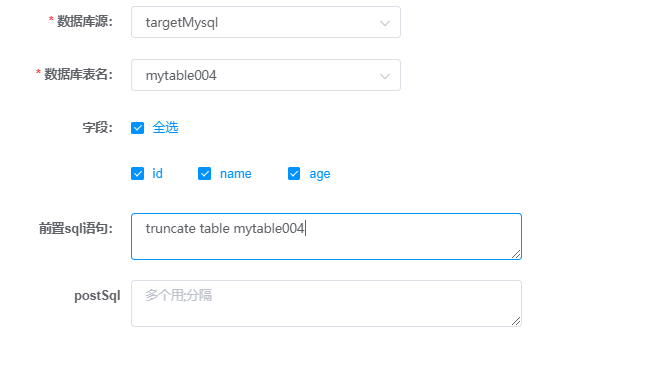
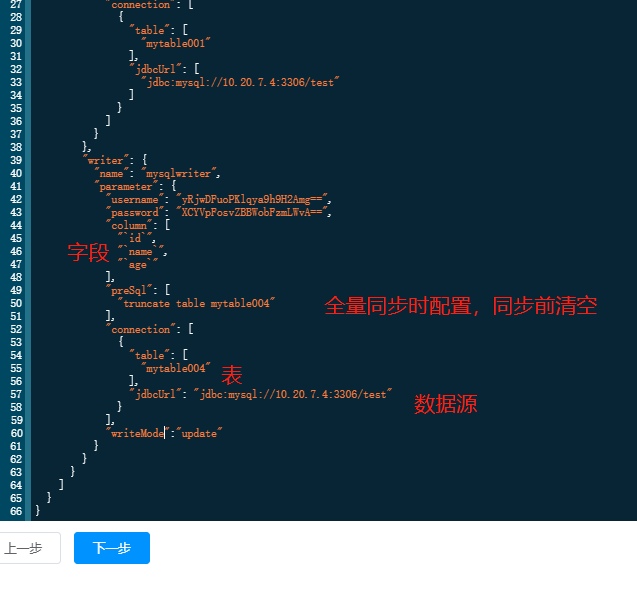
5.2 步骤2 构建writer
选择目标数据库,对应的表和字段。
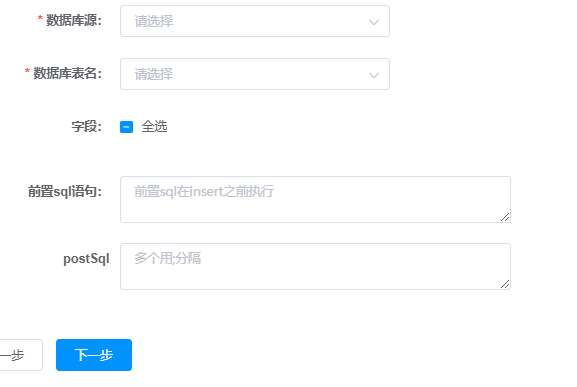
- 数据库源:选择在数据源管理中配置的目标数据源。
- 数据库表名:目标表,根据需要选择
- 字段:目标表的字段,根据需要选择
- 前置sql语句:数据插入表之前执行的语句。如果是全量定时同步,则每次同步前都要清空表。这里需要填:truncate table 表名。如果是增量定时同步,则不需要清空表。只能填一条语句。
- postSql:数据插入表完成后,执行的后置sql语句,可以填多条,用;隔开。
举例:
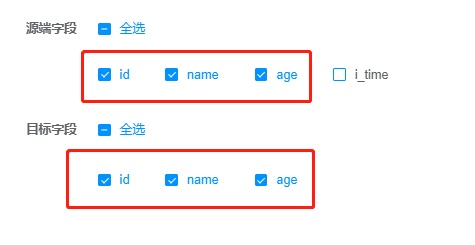
5.3 步骤3 字段映射
根据同步要求,选择对应的字段。如果顺序不对,则在构建后进行修改。
5.4 步骤4 构建

- 先点“构建”
- 再点“选择模板”


5.5 提示构建成功后转向“任务管理”模块
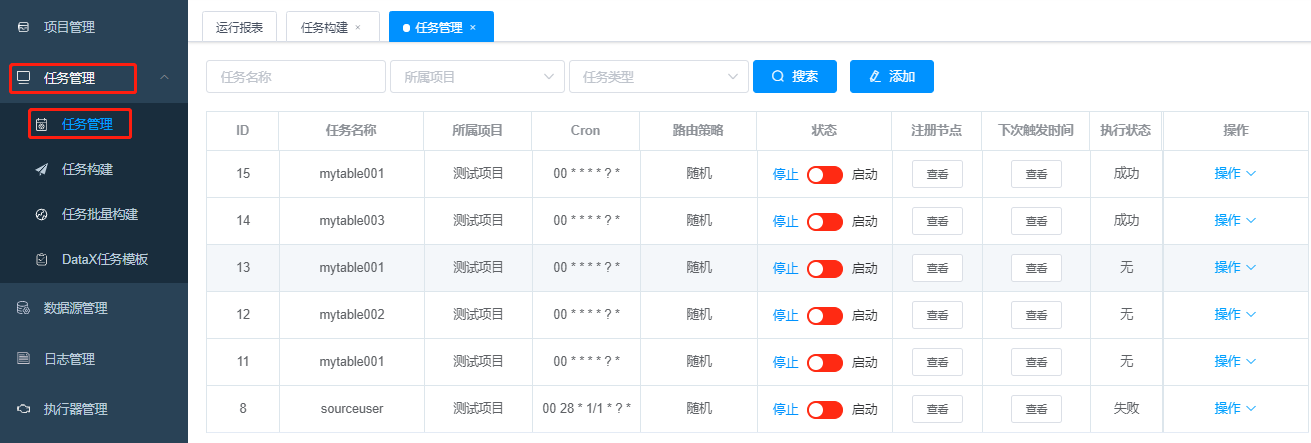
这里可以看到刚才“构建”的任务。
6 任务管理-任务管理
任务管理中可以对任务开启、停止、编辑、删除、执行、查看对应日志等操作
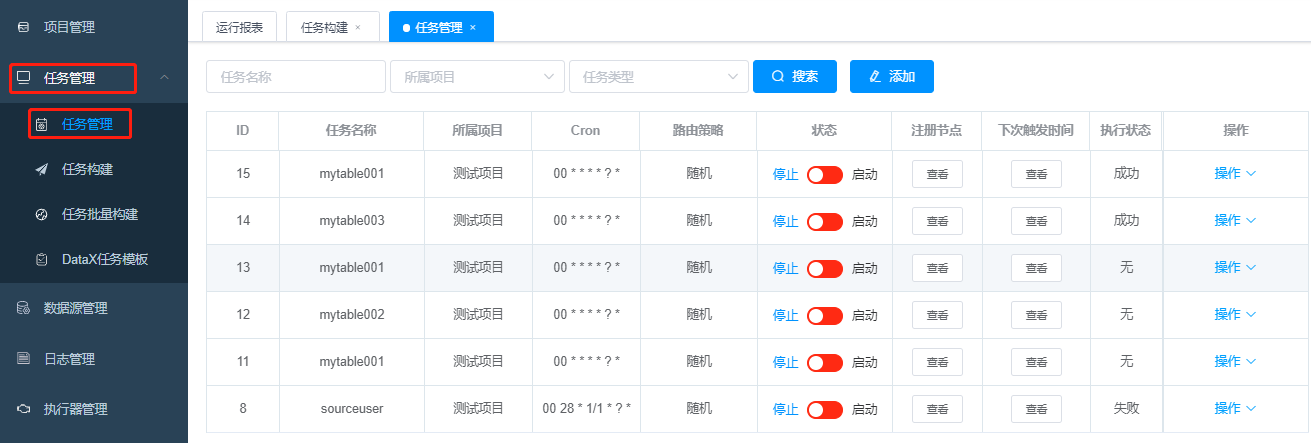
- 状态:绿色代表任务启动,会定时执行。红色代表任务停止,不会定时执行。
- 注册节点:查看这个任务可以被哪些执行器执行。
- 下次触发时间:定时任务的下次执行时间。
- 执行状态:无,成功,失败。第一次创建,未执行前,状态是无。
- 操作:执行一次、查询日志、编辑、删除。
执行一次:手动触发任务,执行一次。
查询日志:跳转到本任务的日志列表
编辑:打开编辑窗口,显示任务的所有信息,可以修改。
删除:这个不用说了,任务不要了。
重点说一下编辑:点击编辑按钮,打开编辑页面。
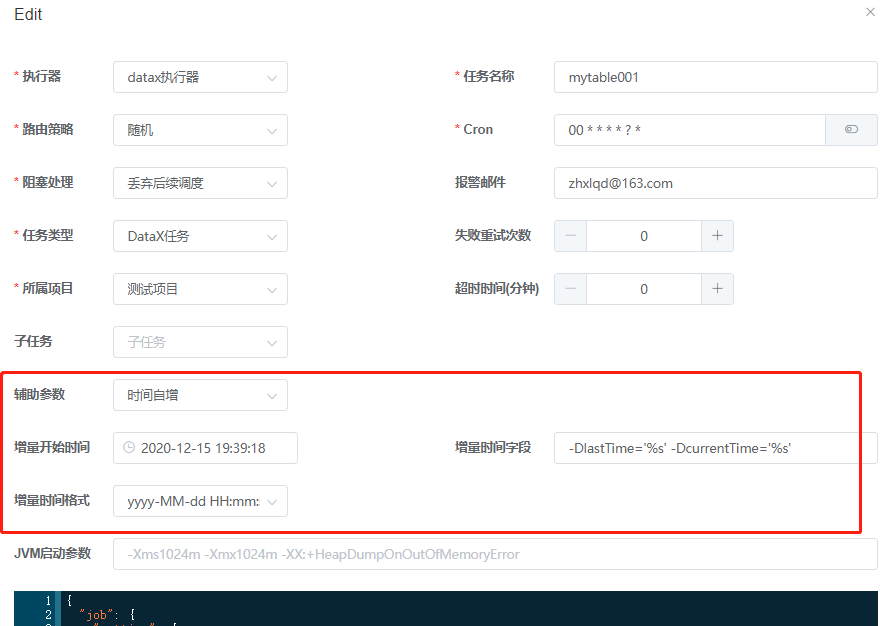
辅助参数:辅助增量数据抽取的。目前推荐使用“时间自增”。ID自增存在缺陷,历史ID对应的数据如果被修改过,在增量抽取时,永远不会更新。而“时间自增”这种方式对增量数据进行抽取,也可以抽取ID不变,其他字段修改过的数据。只要源数据库表中操作时间字段根据实际操作的时间更新过即可。
7 任务管理-批量构建
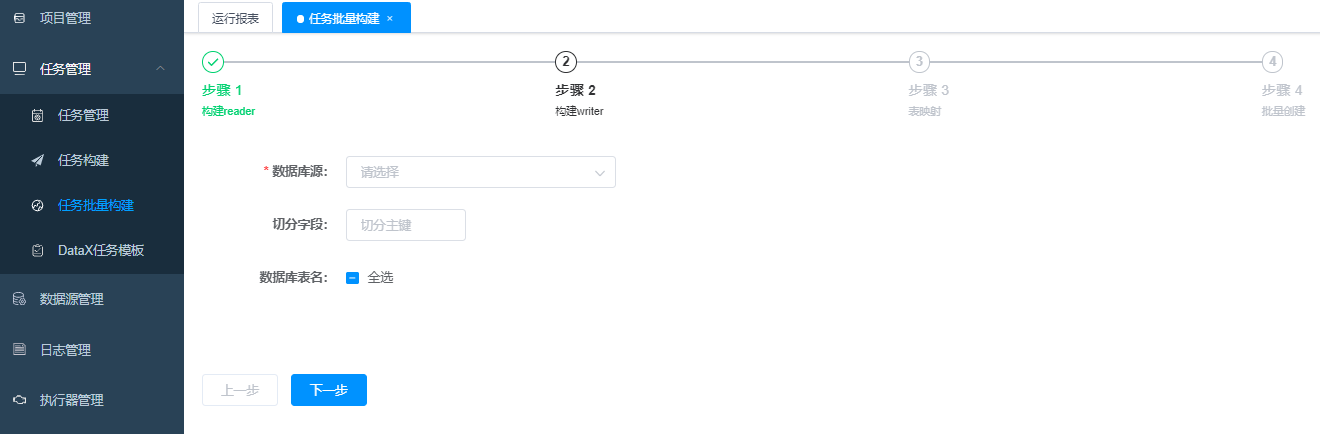
批量构建适合同构表的批量同步,比如:1天一张订单表,现在要同步一年的365张订单表,这些表的结构完全一致,此时就可以选择批量构建。
非同构表批量同步也可以,因为没有字段的匹配过程,所以构建完成后,还需要在任务管理中找到任务进行编辑修改。
三 DataX和Datax-web 安装配置
Datax 和 Datax-web的关系:
Datax是异构数据库(同构也可以)离线同步的ETL工具。
Datax-web是可视化的管理系统,可以简化构建任务、管理任务、定时设置及调度执行,属于辅助datax使用的配套工具,提高工作效率。
DataX
gitee地址:
https://gitee.com/mirrors/DataX
github地址:
https://github.com/alibaba/DataX
DataX-web
gitee地址:
https://gitee.com/WeiYe-Jing/datax-web
github地址:
https://github.com/WeiYe-Jing/datax-web
关于文档说明:在以上开源地址打开后或者源码中都可以看到详细的说明.
1 Datax
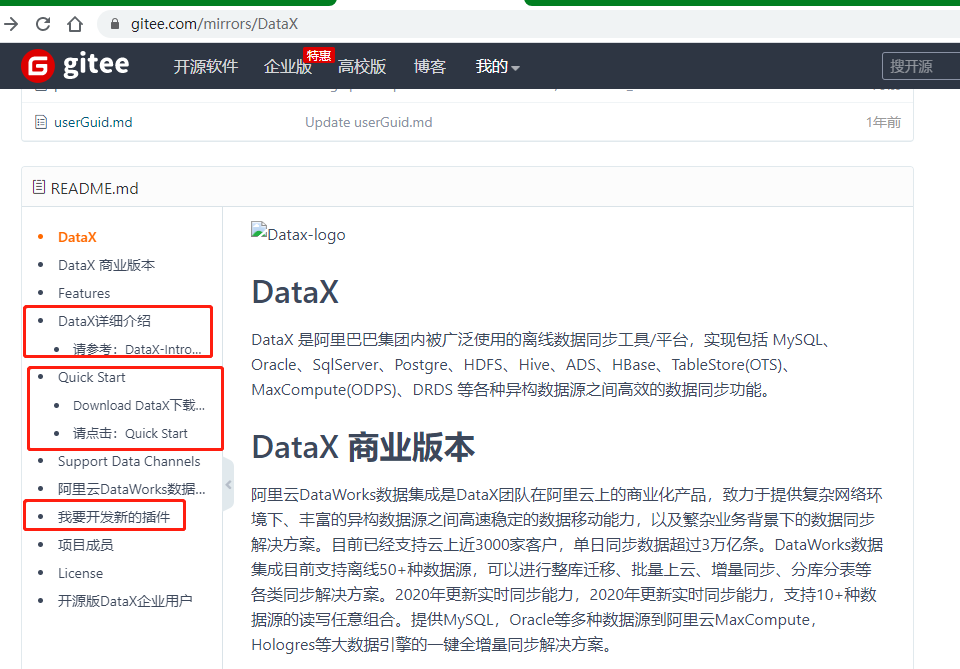
除了readme.md之外,还有其他文档
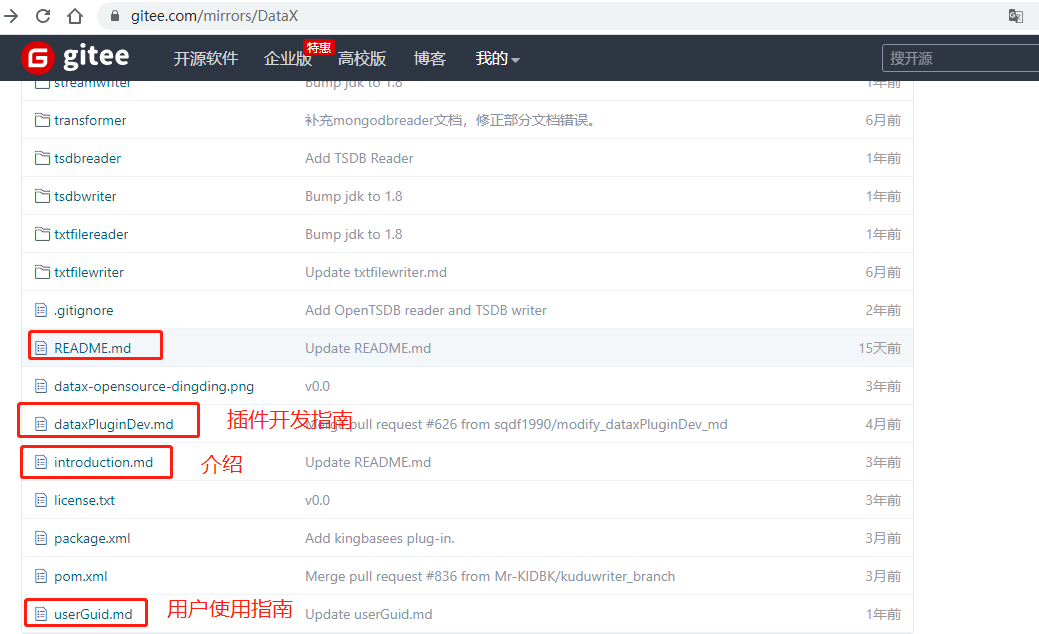
除此之外,每个插件都有对应的介绍。
2 Datax-web
除了readme.md之外,还有其他文档