Ignite项目刚开源时,它被定义为一种纯粹的内存解决方案:一种分布式缓存,可将数据放入内存以加快访问速度。但随后在2017年推出了Apache®Ignite™2.1版本,它首次发布了Ignite的原生持久化模块,让Ignite可以作为一个完整的分布式数据库。从那以后Ignite就不再依赖于外部持久性存储机制,以及随之而来的数据库配置和管理问题。
Ignite原生持久化支持分布式ACID并且兼容SQL,可以与Ignite的固化内存架构透明地集成。Ignite持久化是可选的,可以打开和关闭,关闭时,Ignite就是一个纯粹的内存存储。
不过用户也对Ignite的持久化模式产生了一些疑问,例如:“如何防止脑裂情况下难以处理的数据冲突?”,“如果节点故障实际上不会丢失数据,那么如果不做分区再平衡,是否可以继续?“,”如何自动执行比如集群激活这样的操作?“
这些问题都需要给予解答。
Ignite的基线拓扑是服务端节点的一个集合,用于同时在内存和Ignite持久化中存储数据。基线拓扑中的节点在功能方面没有限制,并且也作为常规的服务端节点,充当Ignite中数据和计算的容器。
如果启用了Ignite持久化,则必须要有基线拓扑,它表示集群中将数据保存到磁盘上的一组服务端节点。
通常,当集群在Ignite持久化启用后的首次启动时,集群处于非激活状态,不允许任何CRUD操作。比如,如果尝试执行SQL或键值操作,会抛出异常,如下图所示:

这样做的目的是,在集群重启过程中,如果应用要修改还未加入集群、但是持有数据的节点上的数据时,避免可能出现的性能、可用性和一致性问题。因此需要为启用了Ignite持久化的集群定义基线拓扑,之后就可以手动或通过Ignite自动维护拓扑,下面会深入了解这个概念的细节,看看如何使用它。
基线拓扑:第一步
从概念上讲,内存模式集群是无状态的:没有专用节点,所有节点都是对等的,每个都可以被赋予缓存分区,获得计算任务,或者在其上部署服务。如果节点退出集群,则用户请求将由其它节点接管,并且已删除节点的数据将不再可用。
在持久化模式下,节点即使在重启后仍保持有状态,在启动期间,节点会从磁盘读取数据,并恢复状态。因此,节点的重新加载不需要从其它集群节点进行数据复制(也称为再平衡),在故障发生时存在于集群中的数据也将从本地磁盘恢复。
基线拓扑是将有状态的节点集(可在重启后恢复)与其它节点区分开来的机制,基线拓扑(后续称为“BLT”)其实就是配置了数据存储的节点标识符的集合。
持久化的数据:冲突保护
分布式系统的脑裂问题已经很难处理,但是在开启持久化的背景下变得更为危险,考虑一个简单的场景,比如有一个集群和一个复制缓存,然后执行以下操作:
- 停止集群然后启动一个叫做子集A的子集群;
- 更新缓存中的部分数据;
- 停止该子集然后启动子集B;
- 对同样的键执行其它一些更新操作。
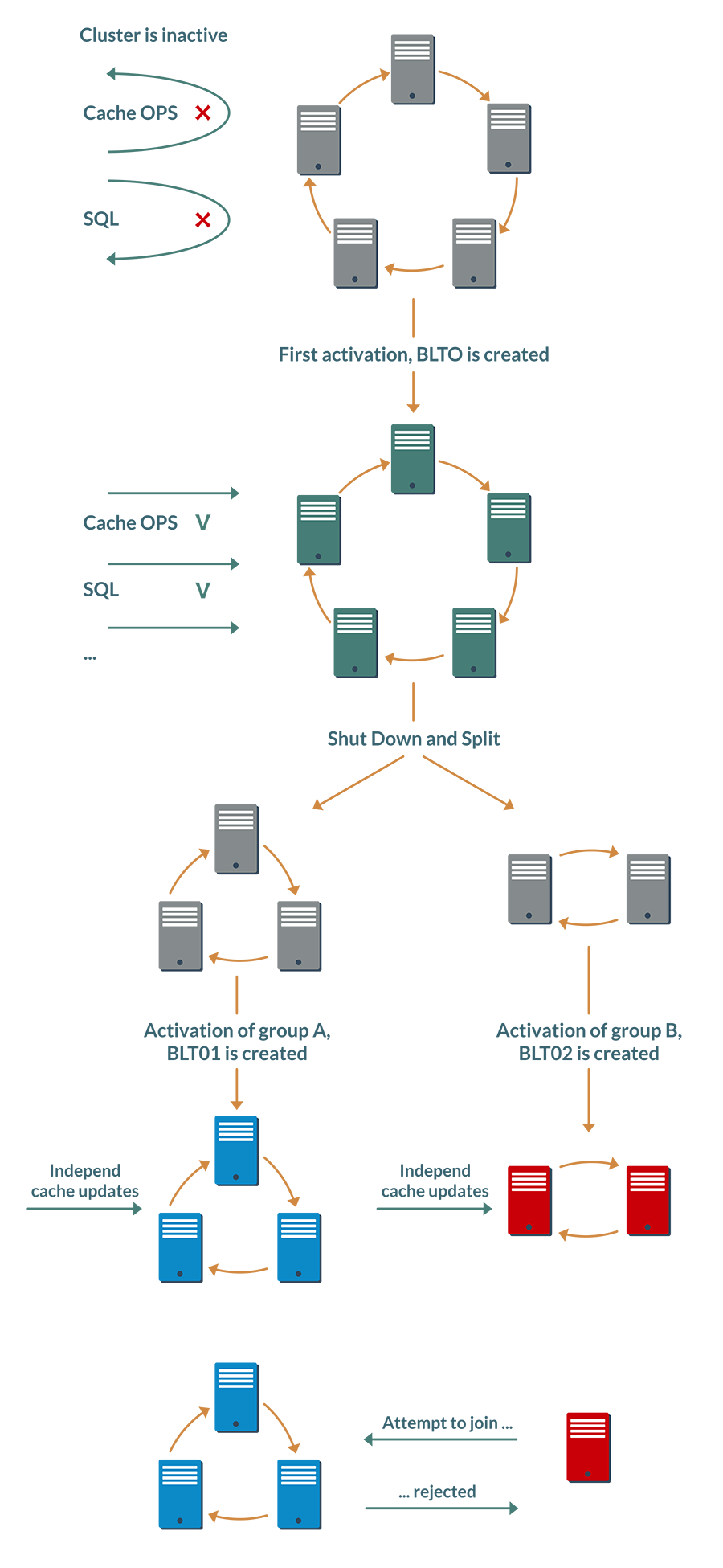
因为Ignite工作于数据库模式,所以在第二个子集的节点被搁置后,更新不会丢失,如果我们再次运行第二个子集,这个数据仍然有效,恢复初始集群后,不同的节点可以包含相同键的不同值。
只是通过停止和运行节点,集群中的数据就已经处于未定义状态,这是不可能自动解决的,需要BLT来防止这种情况。
这个想法就是,在持久化模式下,集群需要另一个阶段:激活。
在第一次激活期间,在磁盘上创建并保存了第一个基线拓扑,其中包含了激活时集群中存在的每个节点的信息。
此数据还包括根据在线节点的ID计算的哈希值。如果在下次激活期间拓扑缺少某些节点(例如集群重新加载并且一个节点停止服务),则将再次计算哈希值,并将之前的值保存在相同BLT的激活历史记录中。
因此,基线拓扑维护了一个哈希链,描述了每次激活后的集群构成。
在阶段1和阶段3,启动节点子集后,需要激活不完整的集群,然后每个在线节点将在本地更新BLT,即向其中添加新的哈希。每个子集的所有节点都可以计算相同的哈希,但不同子集的哈希值会不同。
这时可能会猜到以下内容:如果某个节点尝试加入其它的组,则系统会认为其在该组之外已被激活,并且将拒绝访问。
但是要注意,这种验证机制不会对脑裂场景中的冲突提供绝对保护。如果集群分成两半,例如每半部分至少保留一个分区的副本,并且这一半没有重新激活,可能会遇到每一半都发生相同数据冲突变化的情况。BLT与CAP定理不冲突,但通过显式管理错误保护用户免受冲突。
好处
除了防止冲突,BLT还可以增强一些很好的兼容性。
好处1:少一个手动动作。应在每次集群重启后手动完成上述激活; 没有“开箱即用”的自动化解决方案。使用BLT,集群可以独立决定是否需要激活。
虽然Ignite集群是一个弹性系统,可以自动添加或删除节点。BLT基于此,在数据库模式下,帮助用户维护稳定的集群配置。
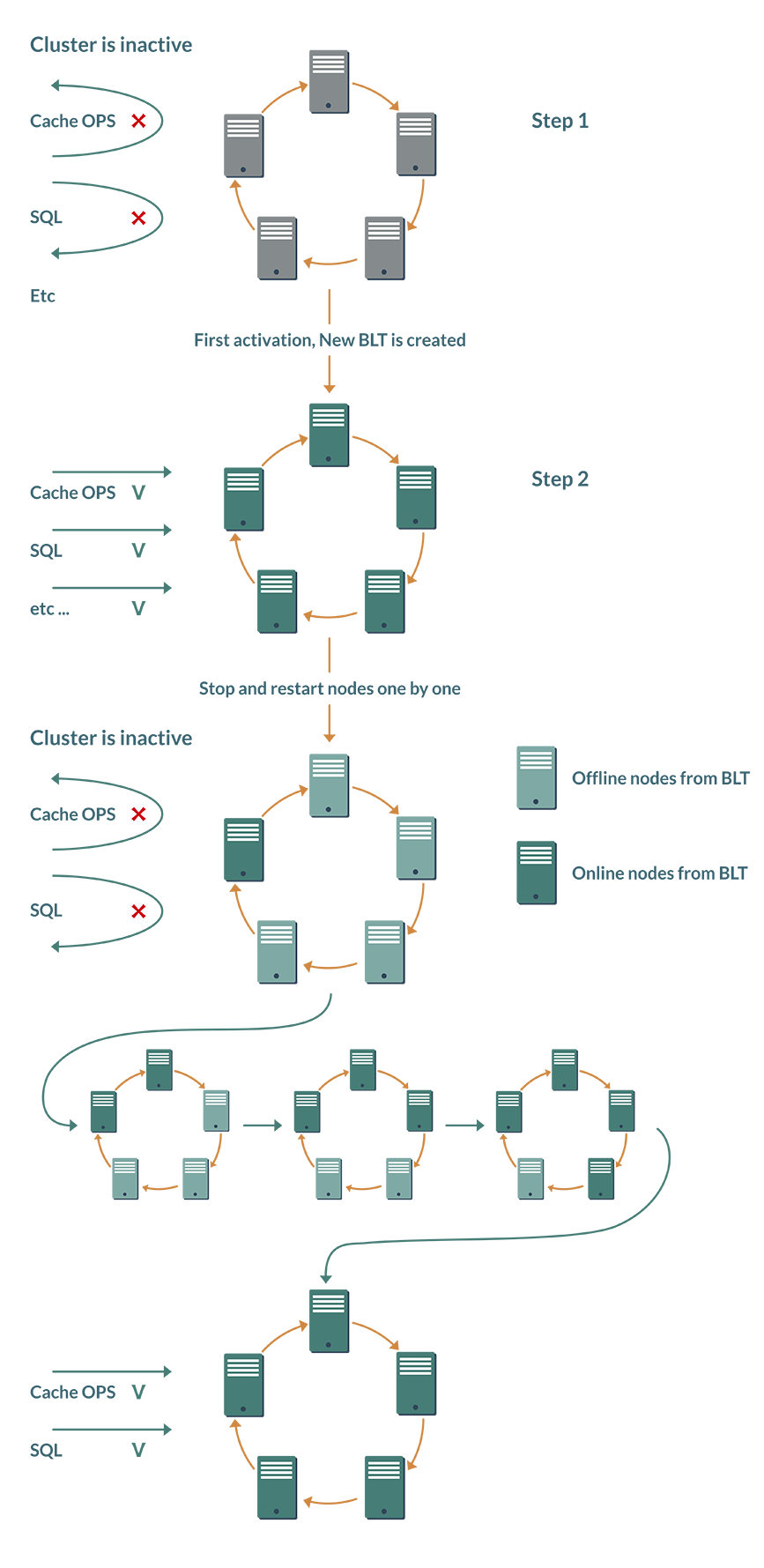
首次激活集群时,新组成的基线拓扑会记住拓扑中应存在哪些节点。重新启动后,每个节点都会检查其它BLT节点的状态,一旦所有节点进入在线状态,集群将自动激活。
好处2:更节省网络资源。当然,这个想法建立在拓扑结构长期保持稳定的前提下。在BLT之前,如果节点从拓扑中退出哪怕10分钟,都会导致缓存分区再平衡以维持足够的备份。但是,如果节点几分钟内就能恢复,为什么要花费网络资源并拖慢整个集群的速度?基线拓扑就可以对这种情况进行优化。
集群默认会假定故障节点将很快恢复,此时间段内,某些缓存可以使用较少的备份,但不会导致服务减慢或停止。
管理基线拓扑
因此就可以知道,基线拓扑由第一次集群激活时自动配置,激活之后,在BLT中就持有了所有在线的服务端节点。
手工BLT管理是通过Ignite发行版的控制脚本实现的,相关的详细说明请参见这个文档。
该脚本暴露了一个非常简单的API,仅支持三种操作:添加节点、删除节点和配置新的基线拓扑。
虽然添加节点是一个相对简单的操作而没有重大风险,但是从BLT中删除节点就是一项更复杂的任务。在生产环境下执行此操作可能会导致竞争,即在最糟糕的情况下,整个集群可能会无响应。因此删除需要满足一个条件:要删除的节点必须处于离线状态,如果尝试删除在线节点,脚本将抛出异常从而终止。
从BLT中删除节点时,还需要手工执行一项操作:停止此节点。因为这种情况不常见,所以这点额外的工作也可以忽略不计。
用于BLT管理的Java接口甚至更简单:它只公开了一个方法,基于一个节点列表配置基线拓扑。
结论
维护数据的完整性工作必不可少,必须在任何数据存储中解决。关于分布式关系数据库,尤其是Ignite,这个任务变得更具挑战性,考虑一些实际的、数据完整性可能被破坏的场景,基线拓扑会提供很多的帮助。
Ignite还对性能高度重视,BLT还有助于显着节省资源并缩短系统响应时间。
原生持久化功能最近才实现,必将不断发展,变得更强大、更高效、更易于使用,而基线拓扑概念也会随之不断演变。