
本系列文章主要介绍 BaikalDB在同程艺龙的落地实践
作者简介:王勇,同程艺龙架构师,BaikalDB Column Store Contributor,专注于分布式数据库方向的研发工作
欢迎Star关注 BaikalDB (github.com/baidu/BaikalDB) 国内加速镜像库gitee
BaikalDB 高性能和扩展性实践
本系列文章把BaikalDB总结为六个核心特性如下图,上篇文章BaikalDB高可用与HTAP特性实践 主要与前两个有关,本篇讨论中间两个, 下篇将讨论最后两个。

这也是我们在业务推广中的关注次序,即
- 首先必须(Must to)业务场景匹配精 准(1一致性)和运行平稳(2高可用)
- 其次最好(Had better)是数据多(3扩展性)与跑的快(4高性能)
- 最后应该是(Should)使用友好(5高兼容性)与 成本节省(6低成本)
简称:稳准多快好省。
本文将会通过介绍业务落地前的两个实际测试案例,来分享总结BaikalDB在性能与扩展性方面的数据。
基于行存OLTP场景的基准测试
测试目标
如果把BaikalDB看成一款产品,基准测试的目的就是加上一份产品规格说明书,在性能测试同学的参与下,我们进行了为期2个月的基准测试,并给BaikalDB这款产品的外包装上写下如下关于规格的信息:
- 设计的集群最大规模,在 1000 个节点情况下,能支持 18 种数据类型,单节点 1T 数据容量,集群整体1P容量。
- 在基准数据测试下,集群单点性能达到,write不低于2000 QPS,单次write不超过 50 ms, read性能达到不低于4000 QPS,单次read不超过 20 ms。
- 对外接口基本兼容MySQL 5.6版本协议。
- 基于Multi Raft 协议保障数据副本一致性,少数节点故障不影响正常使用。
- Share-Nothing架构,存储与计算分离,在线缩扩容对性能影响仅限于内部的数据自动均衡,而对外部透明,新增字段30s生效对集群无影响。
测试范围
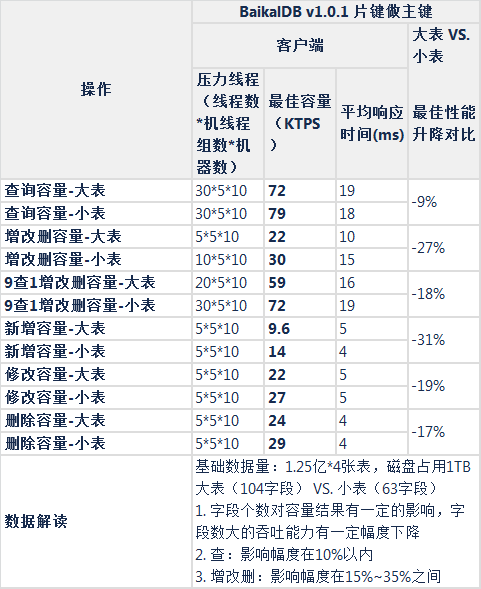
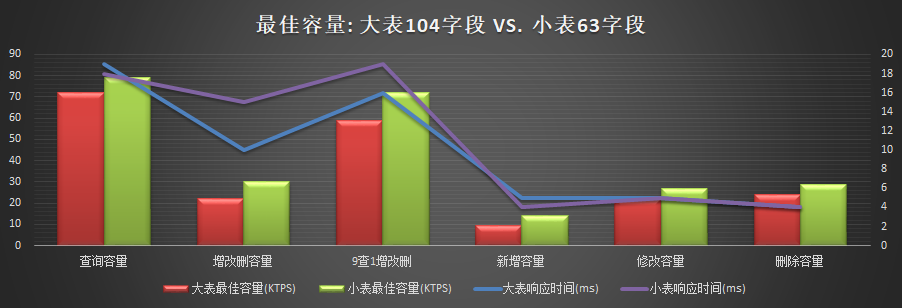
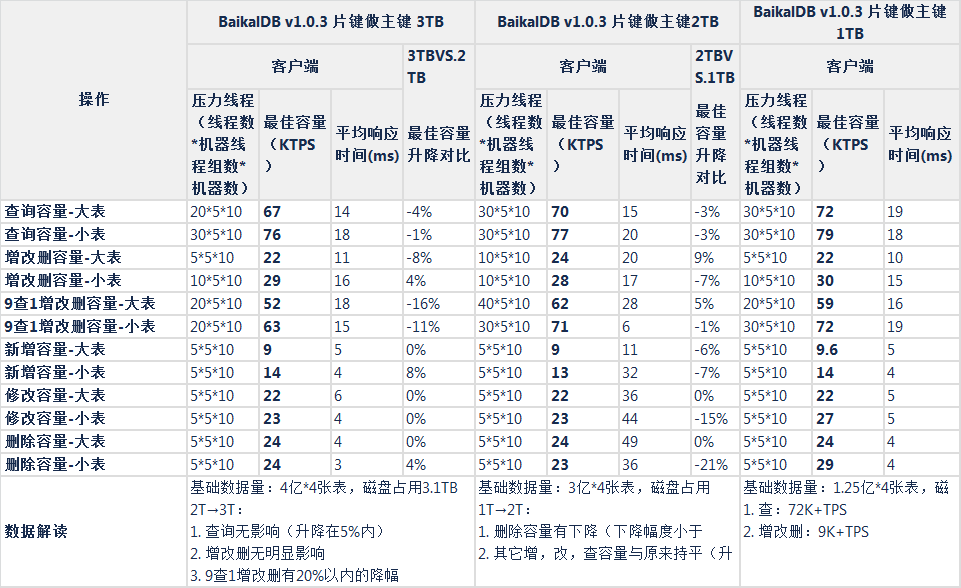
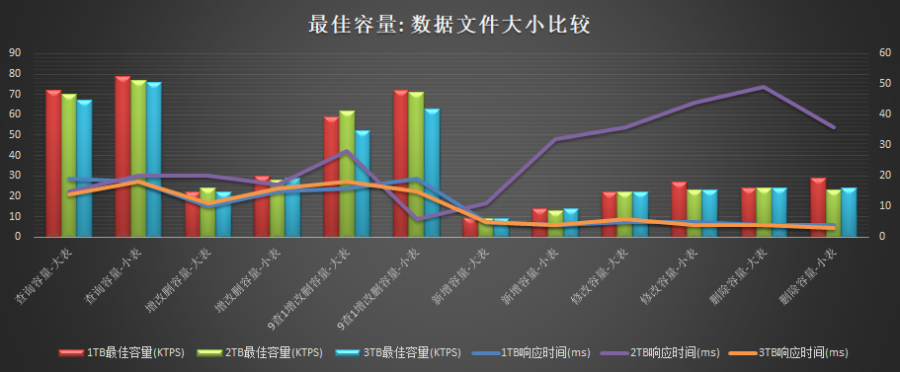
- 性能测试(行式存储,大表104字段,小表63字段,集群总基础数据1TB,2TB,3TB)
- 与mysql基准对比测试
- 表结构字段个数影响(大表104字段,小表63字段)
- 集群总基础数据大小影响(1TB,2TB,3TB)
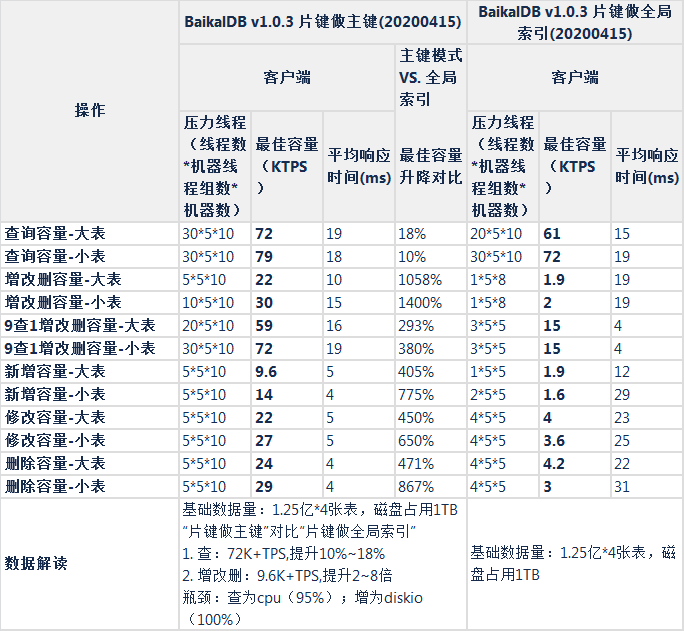
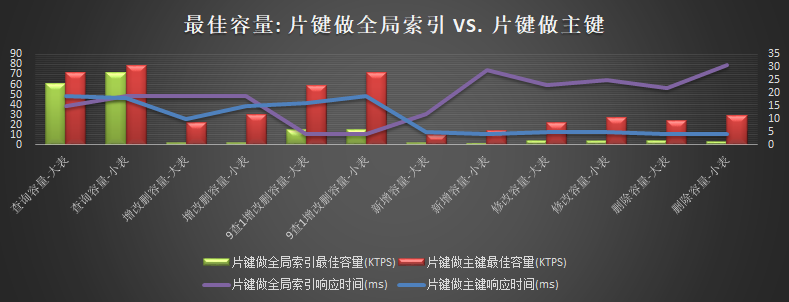
- 表结构影响("自增主键","片键做全局索引","片键做主键")
- 带压力的扩展性测试
- 加节点(store)
- 减节点(store)
- 动态加列
测试环境
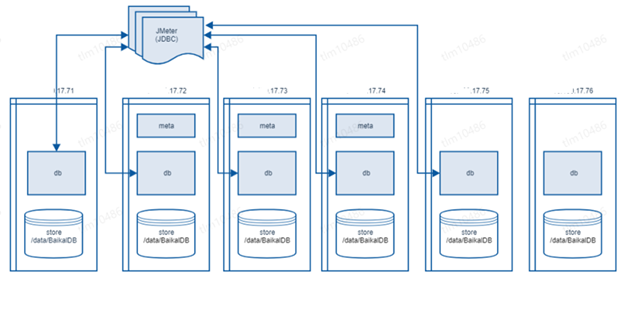
五台机器混合部署3 meta, 5 db, 5 store获取基准,另有一台机器作为增减节点机动(centos 7.4 32核 2.4GHZ,128G内存 1.5TSSD硬盘)
主要指标说明
- 最佳容量(KTPS):
- 定义
- 系统最大吞吐能力: 每秒dml操作请求数
- 单位为KTPS(千次操作请求/秒)
- 前置条件:
- 5台机器配置的集群(3 meta, 5 db, 5 store)
- 连续两分钟可以稳定支撑的最大吞吐能力
- 平均读响应时间小于20ms,平均写响应时间小于50ms
- 定义
- 响应时间:dml操作从发送到收到返回结果所经过的时间,单位为毫秒
- diskIOUtil 磁盘使用率: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的
- 如果接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
- 大于30%说明I/O压力就较大了,读写会有较多的wait
- 最佳容量判定方法
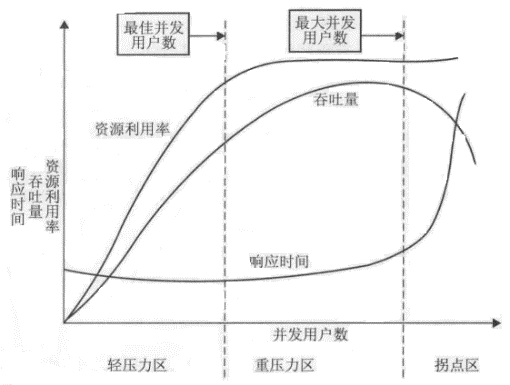
绘制系统的性能指标随着并发用户数增加而出现下降趋势的曲线,分析并识别性能区间和拐点并确定性能阈值。
测试结论
- 性能测试
- 读: 片键做主键模式,5节点读容量为72K+TPS,性能比mysql高85%+,瓶颈为CPU
- 写: 片键做主键模式,5节点写性能为9.6K+TPS,与mysql相当,为mysql的85%~120%之间,瓶颈为DiskIO
- 扩展性测试
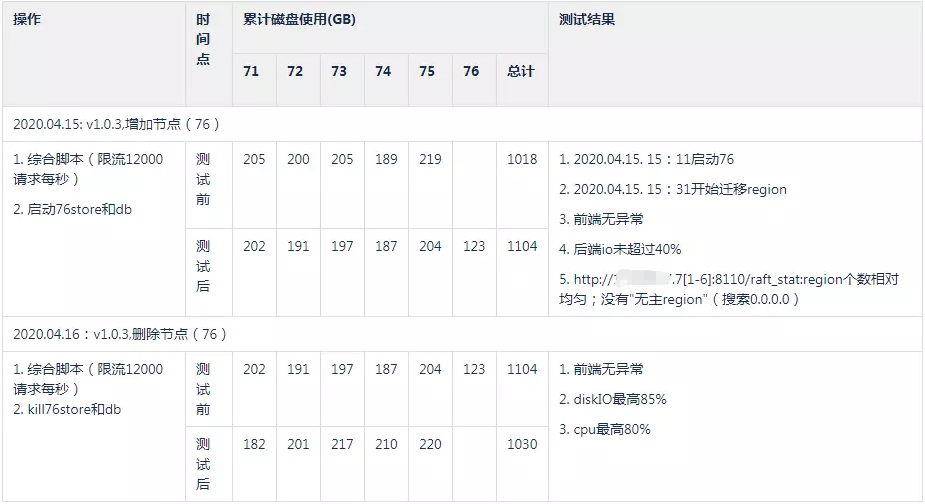
- 加节点:前端吞吐平稳
- 减节点:减节点操作需要确保集群能力有足够的余量,能承载被减掉节点转移的压力
- 加列: 22秒新列生效(1.25亿基础数据)
性能测试详情
与mysql基准对比测试

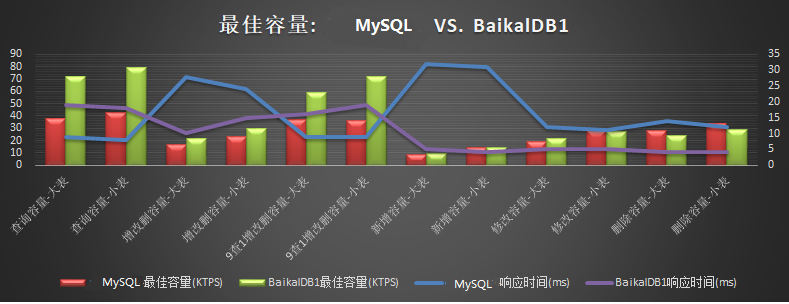
表结构字段个数影响
集群总基础数据大小的影响
表结构影响
扩展性测试详情
不停服增减节点
不停服增加列
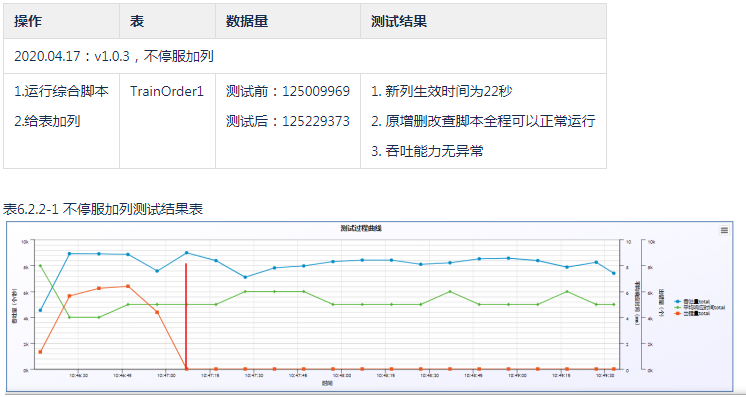
不停服加列测试过程曲线图(22秒后所有的带新列的insert语句全部成功,红色曲线代表失败数降为0)
基于列存OLAP场景测试
测试背景
指标监控系统用于实时(定时)监控线上某实时业务数据,生成关于健康状态的相关指标,如果指标超出阈值,则触发报警功能。数据表约50列20亿行,查询sql10余种均为聚合类查询,检索列数不超过4列,查询条件为一定时间区间的范围查询,之前是跑在一款行存的分布式数据库之上,这是一个典型的olap类场景,我们采用baikaldb的列存模式与线上进行了对比测试,测试对象均为线上真实数据,两款DB集群配置相当,测试查询性能的同时,均承担等同的写负载。
测试结果
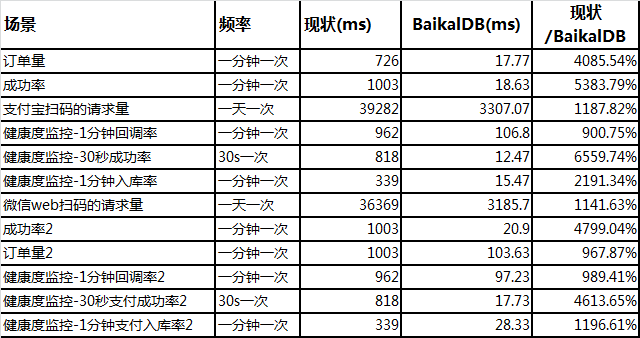
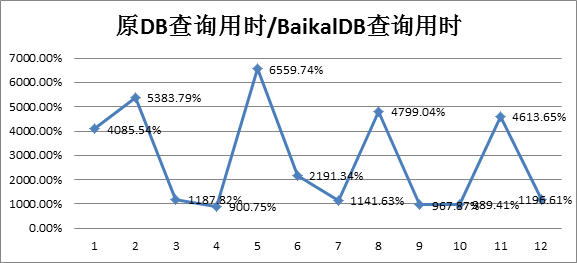
从测试结果可以看出,在宽表少列与聚合查询的sql查询,使用baikaldb的列式存储,可以有效减少磁盘IO,提高扫表及计算速度,进而提高查询性能,这类查询也是olap场景sql的常见写法。
性能与扩展性总结与思考
性能分析的几个角度
- 资源瓶颈视角
- CPU : 多发生在读qps过大时(db,store),可监控vars/bthread_count指标
- IO: 多发生在写qps过大时(store),可监控io.util指标,及store/rocksdb/LOG日志。
- Mem:
- io.util满可导致内存刷盘不及时进而引起内存满(store);
- 慢查询过多时,会导致查询积压于store,进而引起内存满(store);相关参数db:
slow_query_timeout_s=60s; - store内存建议配置为所在实例的40%以上,因为内存直接影响cache命中率,cache miss过多的话,会增大io.util及sql用时;相关参数:
cache_size=64M export TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES=209715200 #200M,当大value时,调大可以避免线程竞争,提高性能 。
- Disk:
- io.util满可导致rocksdb的L0层文件压缩不过来,出现快速的空间放大,进而导致磁盘快速被写满。相关参数:
max_background_jobs=24 - rocksdb数据文件不建议超过1T,按照默认配置,超过1T后rocksdb将增加1层,写放大增大10,写放大会导致io.util出现瓶颈。若服务器磁盘远大于1T,建议单机多实例部署。
- io.util满可导致rocksdb的L0层文件压缩不过来,出现快速的空间放大,进而导致磁盘快速被写满。相关参数:
- NetWork:
- 查询及事务大小建议控制在10M以内,数据量过大会触发事务及RPC包大小限制;
- 若需全量导出,用
/*{"full_export":true}*/ select * from tb where id > x limit 1000;语法。
用户视角
- 联合主键 vs 自增主键
- BaikalDB是按主键进行分片的,主键的选择影响了数据的物理分布,好的做法是把查询条件落在尽量少的分片上,查询时基于前缀匹配,一般建议按范围从左到右建立联合主键,例如:
class表主键可设置为schoolid,collegeid,classid # 学校,学院,班级; - BaikalDB实现自增主键主要是为了与MySQL兼容,由于全局自增是通过meta单raft group完成,会存在rpc开销及扩展性问题;另外全局自增主键也容易导致数据批量插入时请求集中于最后一个Region节点,容易出现瓶颈。
- BaikalDB是按主键进行分片的,主键的选择影响了数据的物理分布,好的做法是把查询条件落在尽量少的分片上,查询时基于前缀匹配,一般建议按范围从左到右建立联合主键,例如:
- 全局索引 vs 局部索引
- 全局索引与主表不在一起,有自己的分片规则,好处是有路由发现功能,坏处是多了与全局索引的RPC开销,局部索引与主表一起,需要通过主键确定分片,否则需要广播,好处是RPC开销。
- 小表建议用局部索引;
- 大表(1亿以上),查询条件带主键前缀,用局部索引,否则用全局索引。
- 行存 vs 列存
- 宽表少列(查询列/总列数 小于 20%), 聚合查询的olap请求用列存
- 其他情况用行存
实现视角
- Balance:BaikalDB会周期性的进行Leader均衡与Peer均衡,负载均衡过程中若数据迁移量较大,可能是影响性能,一般发生在:
- 增删节点时
- 批量导入数据时
- 机器故障时
- SQL Optimizer:目前主要基于RBO,实现了部分CBO,若性能与执行计划有关,可以使用explain,及 index hint功能调优。
扩展性考虑因素
- 稳定性
- 扩容:从实测情况看,扩容情况下比较平稳
- 缩容:缩容较少发生,但在双中心单中心故障的情况下,相当于缩容一半,此时稳定性还是值得注意与优化的,主要包括:
- meta,尤其是主meta挂了情况下,将不能提供ddl, 主auto incr 挂了情况下,将不能提供自增主键表的insert功能。
- store读正常,但瞬间一半store leader挂了情况下,写功能需要等到所有leader迁移至健康中心为止。
- 极限容量:
- 计算逻辑如下
- Region元数据=0.2k, Meta20G内存共计可管理的 Region总数 = 20G/0.2k = 100M
- Region数据量 = 100M,Store 1T磁盘共可管理的 Region个数每store = 1T/100M = 10k
- 共计可以管理的数据量 = Region总数 * Region数据量 = 100M * 100M = 10P
- 共计可以管理的store个数 = Region总数 / Region个数每store = 100M/10k = 10k
- 理论上Meta 20G, Store 1T磁盘情况下,预计可管理 10k个store节点, 10P大小数据。
- 实际上百度最大的集群管理了1000个store节点,每store 1T磁盘, 共计约1P的集群总空间。
- 计算逻辑如下
- 线性
- 固定范围:O(1)
- 可以下推store全量: O(n/db并发度)
- 不可下推store全量: O(n)
- JOIN查询: O(n^2)
后记
- 本文的性能与扩展性分析数据均来源于实际项目,而非TPCC,TPCH标准化测试,但测试项目据有一定的代表性。
- BaikalDB测试数据基于V1.0.1版,最新发布的V1.1.2版又有了较多优化:
- 优化seek性能,实测range scan速度提高1倍;
- rocksdb升级6.8.1,使用Partitioned Index Filters,进一步提高了内存使用效率;
- 增加利用统计信息计算代价选择索引功能(部分);
- 事务多语句Raft复制拆分执行,提高了Follower的并发度。











