
本系列文章主要介绍 BaikalDB在同程艺龙的落地实践
作者简介:王勇,同程艺龙架构师,BaikalDB Column Store Contributor,专注于分布式数据库方向的研发工作
欢迎Star关注 BaikalDB (github.com/baidu/BaikalDB) 国内加速镜像库gitee
BaikalDB 低成本思考
本系列文章把BaikalDB总结为六个核心特性,上篇文章BaikalDB高可用与HTAP特性实践 主要与前两个有关,中篇BaikalDB 高性能和扩展性实践讨论中间两个, 本篇将介绍最后两个。

这也是我们在业务推广中的关注次序,即
- 首先必须(Must to)业务场景匹配精 准(1一致性)和运行平稳(2高可用)
- 其次最好(had better)是数据多(3扩展性)与跑的快(4高性能)
- 最后应该是(should)使用友好(5高兼容性)与 成本节省(6低成本)
简称:稳准多快好省。
作为系列文章的最后一篇,是关于成本的思考,如果说强一致与高可用是用户关心的在功能上是否满足需求,扩展性与高性能是老板关心的在规格上是否值得投入,那么兼容性与成本则是项目实施者应该关心的问题,因为它关系到项目推进难度。
如果你认可NewSQL的发展趋势,也发现了公司的实际业务场景需求,本文将会讨论在项目实施中需要克服的问题,并建议用成本的角度进行评估,这样有助于对项目的工作量进行计算。例如如果调研发现公司的潜在目标用户均跑在mysql数据库上,那么是否兼容mysql协议直接决定了用户的意愿,用户的学习成本,业务代码的改造成本,生态的配套成本,如果潜在用户超过10个以上则成本将会放大10倍;如果大部分潜在业务使用的是PostgreSQL,那么最好在选型时选择兼容pg的NewSQL。这也是本文将兼容性归类到低成本一并讨论的原因。
成本的分类
狭义的成本:指数据库软件的开发,授权,运维及硬件成本,特点是可量化,例如:
- 开发投入: 24人月
- License授权:10万/年
- 运维投入:DBA 2人
- 硬件成本:服务器10台
广义的成本:泛指在组织实施数据库应用工程实践过程中,所产生费用总和,特点是与项目管理与实施有关,包括:
- 学习开发成本
- 测试验证成本
- 业务迁移成本
- 用户习惯
- 运维配套工具
- 软件成熟度
- 技术前瞻性
狭义的成本可以理解为这件事值不值得做,广义的成本可以理解为把事情做成需要做的工作,截止到本文发表为止,BaikalDB已在公司10余家业务上进行了落地应用,这些应用实际产生的成本与收益如何评估(狭义)?项目落地过程中需要落实哪些工作(广义)?下面将就这两个问题展开讨论。
狭义的成本理论上可减低100倍
由于BaikalDB是开源的,开发成本可以忽略,部署简单,其狭义成本主要集中在硬件成本上。结合公司的双中心建设与Kubernetes云原生平台战略,我们给出了BaikalDB两地四中心三副本行列混存的方案,理论上有望使硬件成本降低100倍,方案如下图:
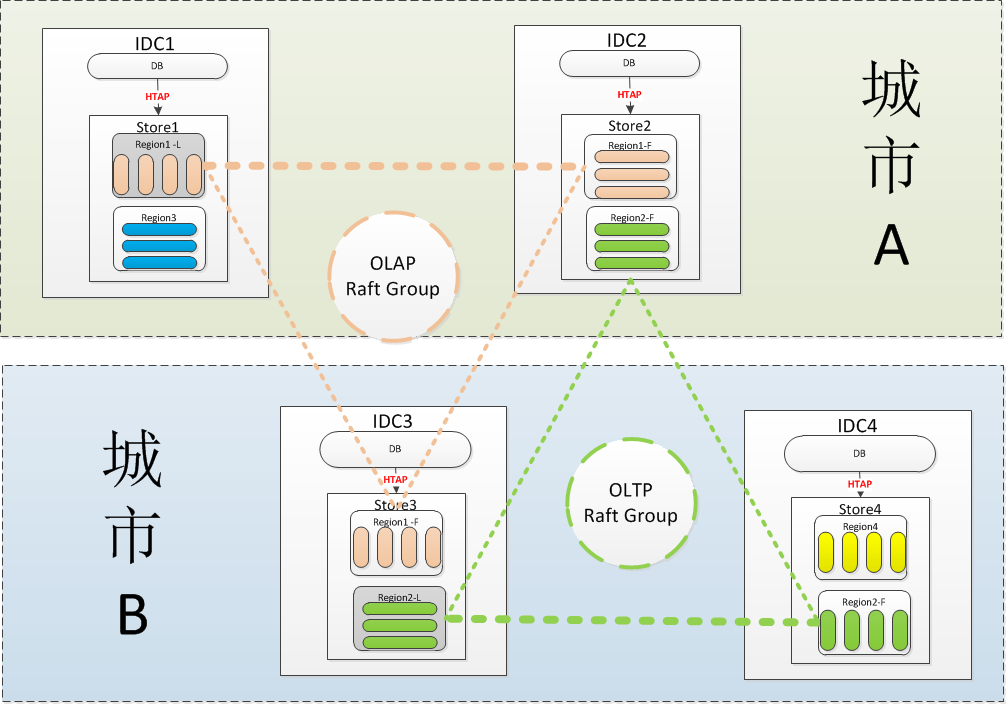
- 注1:图中省去了meta节点部署
- 注2:每个IDC会实际部署了多个store与db节点。
- 注3:行列混存的特性还在开发中
上图采用了完全对称的双中心部署方案,每个数据中心又存在2个对等IDC机房,基于BaikalDB的逻辑机房与物理机房概念,可以完成以上部署,并提供城市级别的容灾能力,通过Raft Group层面的行列混存技术实现仅需3副本即可提供HTAP的能力,配置细节已经在第一篇文章HTAP部署有所描述,本文在之前基础上增加了行列混存(功能尚未实现)的方式,进一步合并了应用场景,减少副本个数,从而达到节约成本的目的。以上方案具体成本节约主要体现在三个方面:
1. HTAP带来的成本降低为5倍
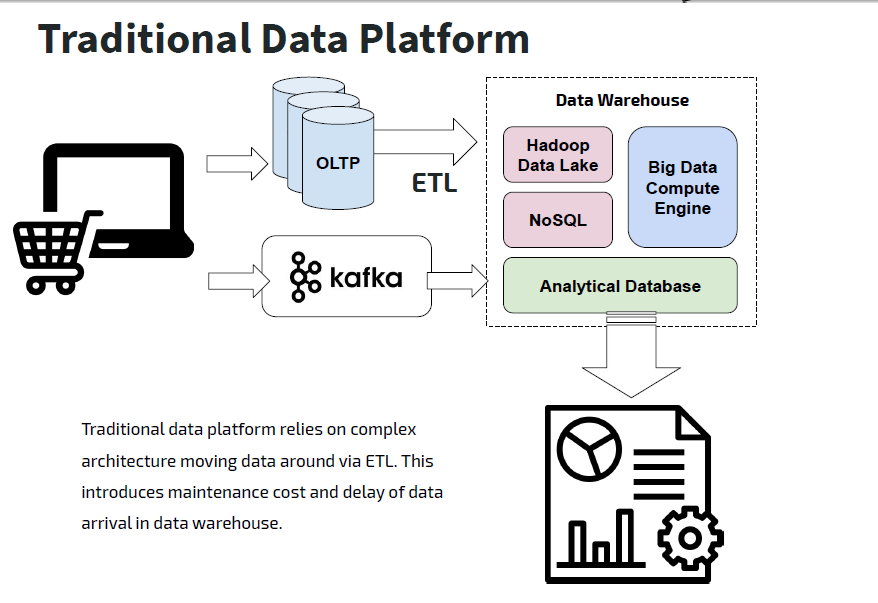
为了满足不同的应用场景,通过同步工具,数据会被分发到ETL,ES,HBASE,kafka,TiDB等不同数据组件中去,核心业务的存储资源存在5倍以上的放大。依据数据库使用现状情况,核心业务一般1套OLTP主库+数据同步平台+5套OLAP数据库,采用此方案后能同时满足以上全部场景,并且省去了异构数据源之间数据同步延迟问题,因为异构数据源超过了5个,合并为1个后,预计收益增大5倍。
2. 单位资源效能带来的成本减低为4倍
行存OLTP类场景性能提升85%
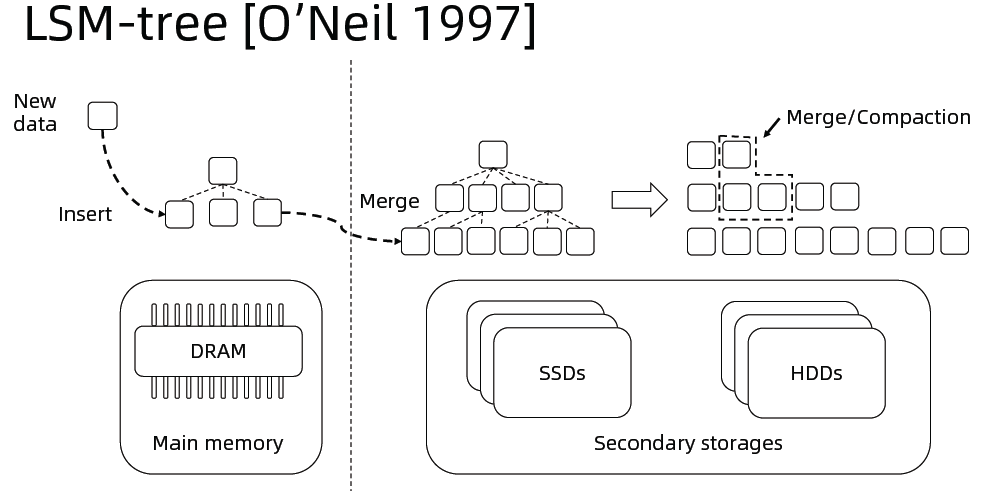
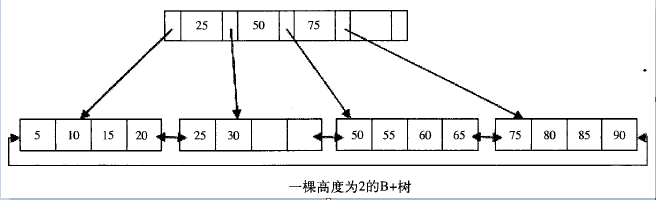
BaikalDB存储层使用RocksDB的LSM-Tree存储,相较于innodb的B+树,通过平衡读,写,空间放大使得读写性能更加均衡,通过out-of-place update及一定的空间放大来优化写性能(对比innodb相当于牺牲全局有序性及存储空间换取写性能),能充分发挥SSD硬盘的随机读优势及利用高效缓存来加速点查询,对于范围查则主要通过data reorganization(merge/compaction)及SSD的并发读来优化速度。参考第二篇性能测试文章的基准性能测试结果,适用于OLTP场景的行存BaikalDB综合性能可提升**85%**。
- 列存OLAP类场景性能提升10倍
OLAP类场景下的SQL查询语句一般是宽表少列,以聚合函数为主,数据比较适合按列存放在一起,一个例子如下:

Demo
#统计每个广告平台的记录数量
SELECT CounterID, count() FROM hits GROUP BY CounterID ORDER BY count() DESC LIMIT 20;
行式

列式

使用BaikalDB的列存引擎,使我们第一家接入OLAP业务(约100亿数据量的聚合查询)查询速度提升10倍。
业务一般会有1个OLTP场景加n个OLAP场景组成,平均来看BaikalDB可以使单位资源效能提升4倍左右。
3. 云原生弹性能力带来的成本减低为5倍
以mysql为例,由于缩扩容升降配困难,为了应对少数发生的业务高峰时段(例如双11一年只有一次)而不得不一直留够Buffer,导致硬件资源的投入不能随着流量的变化而动态变化,弹性不足,资源利用率普遍较低约8%的水平。公司也意识到相关问题,在积极构建基于kubernetes云原生平台(见下图),具体文章参见同程艺龙云原生 K8s 落地实践 。
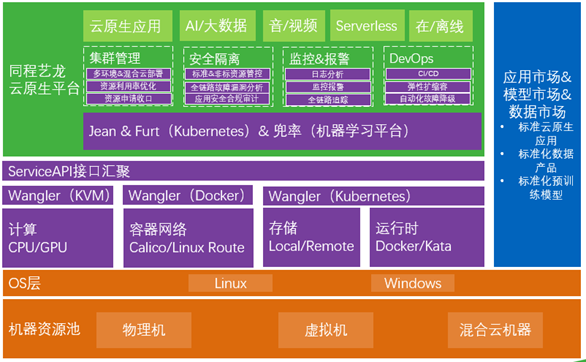
BaikalDB的share –nothing云原生特性能完美的k8s的调度能力进行结合,预计可以把资源利用率提升到40%,因此弹性收益为5倍。之所以没有提升到80%以上是为了满足双中心容灾互备的需要,以应对城市级故障带来的单中心双倍压力。
综上所述,总收益 = HTAP收益 * 单位资源能效收益 * 资源利用率收益 = 5 * 4 * 5 = 100倍
实际上广义的成本难以量化但不能有短板
在狭义成本评估值得做的情况下,需要从项目管理或项目实施的角度思考如何把项目顺利推进,由于每家公司每个项目的实际情况均不一样,项目的评估很难统一量化,但我们在进行项目实施时必须要慎重考虑这些因素,并且任何一个环节不达标均可能导致项目的失败,在这里把项目推进中要完成的工作量称为广义的成本,以我们实践经验进行总结评分,满分为10分,分值越高越好,评价不同于以往的性能测试,具有很强的主观性,仅供参考。
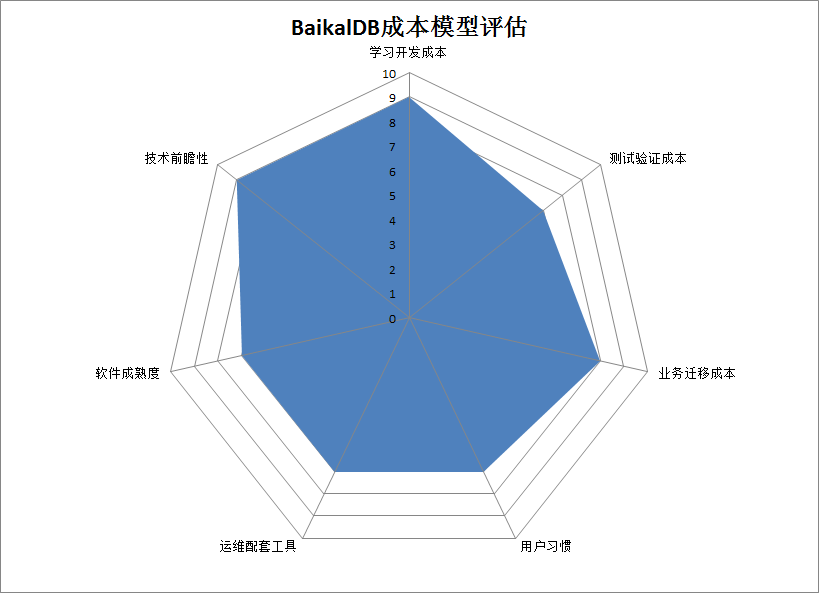
1. 学习开发成本:9分
BaikalDB的学习主要包括依赖与BaikalDB代码本身。
BaikalDB的依赖少而精,主要有三个:
- brpc:Apache项目,百度内最常使用的工业级RPC框架
- braft:百度开源的Raft一致性与复制状态机工业级实现库
- RocksDB:kv存储引擎,集成了Google与Facebook双方大牛的力作
以上三款开源项目,社区都比较成熟,每一款都值得好好学习。
BaikalDB本身作为一款纯开源的分布式数据库,代码10万行,以C++语言为主,代码架构简洁,组织清晰。虽然目前文档不是很多还在完善中,但项目保持了良好编码风格,代码可读性强,大部分实现原理可以通过直接阅读代码掌握,少部分需要结合数据库及分布式领域的理论知识与论文学习。在模块化抽象与分层上保持清晰保持简洁,在一些核心对象例如逻辑计划:LogicalPlanner,表达式:ExprNode,执行算子:ExecNode 仅有一层继承关系,具有薄胶合层显著特点,有效的减低了软件的学习成本,体现了Unix开源文化的KISS原则(Keep It Simple, Stupid!)
总之,BaikalDB是一款非常值得学习的DB,给9分。
2. 测试验证成本:7分
BaikalDB的测试验证工作量与其它DB差不多,中规中矩给7分。
3. 业务迁移成本:8分
业务的迁移成本主要包括数据迁移与SQL改写两个部分,由于BaikalDB兼容MySQL协议,公司已研发了基于MySQL生态的数据同步平台,数据迁移成本不大。使用MySQL开发的业务代码,大部分情况不需要改写SQL,改写主要发生在BaikalDB尚未支持的MySQL语法例如(子查询,一些系统函数上)和慢查询改写上面,业务迁移成本给8分。
4. 用户习惯:7分
- 图像化工具:能使用Navicat, IDEA自带MySQL UI, DataGrip进行简单的表浏览,SQL执行功能,不能进行复杂管理操作
- 公司已有系统对接(例如工单,权限,一站式查询等):尚未打通
- 对新概念的接受过程(例如新的数据文件,部署方式,资源隔离,多租户等)
5. 运维配套工具:7分
- 备份工具:
- 热备: 基于SST的备份恢复
- 冷备: 通过SQL语句逻辑备份。 /{"full_export":true}/ select * from tb where id > x limit 1000;
- 监控工具:Prometheus
- 运维脚本:script
- 部署工具:Ansible
- 压测工具:sysbench
- 订阅工具:Binlog功能开发中
- 同步工具:Canal
6. 软件成熟度: 7分
7. 技术前瞻性:9分
BaikalDB提供的PB级分布式扩展能力,动态变更Schema能力,分布式事务,异地多活,资源隔离,云原生K8s,HTAP能力均与公司未来的需求或规划匹配,因此给9分。
后记
至此BaikalDB在同程艺龙的应用实践系列文章就结束了,BaikalDB作为一款开源两岁的NewSQL数据库还非常年轻,存在很大完善空间。同时作为后浪也借鉴很多前浪的设计思想,有一定的后发优势。BaikalDB实现简洁,功能强大,社区专业友好,无论是用来代码学习还是业务应用均有很大成长空间,欢迎感兴趣的朋友一起参与。由于笔者水平有限,文中如有不妥之处,还望理解指正。











