
一、问题背景
在vivo互联网业务高速发展的同时,支撑的服务实例规模也越来越大,然而单个机房能承载的机器容量是有限的,于是同城多机房甚至多地域部署就成为了业务在实际部署过程中不得不面临的场景。
一般情况下,同一个机房内部的网络调用平均时延在0.1ms左右,同城多个机房之间的平均时延在1ms左右,跨地域机房之间的网络时延则更大,例如北京到上海的平均时延达到了30ms以上。
在业务多机房部署场景中,内部服务如果存在大量的跨机房、甚至跨地域的网络调用,则请求时延会显著加大,会直接影响到服务质量,甚至是用户体验。
二、解决方案
要解决以上问题,只需要实现服务消费者和服务提供者之间的网络调用尽量是同机房内部、或者是同地域即可,即服务消费者在调用服务提供者时,优先调用部署在本机房的服务提供者,当本机房没有部署该服务提供者时,再跨机房调用同地域的同城机房、甚至是跨地域机房的服务。
以上策略我们内部称为 就近路由。业务的就近路由示意图如下:
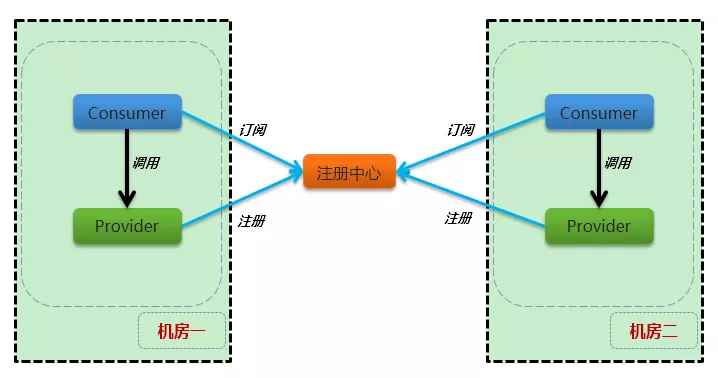

为了简单易用,vivo内部的服务间调用均使用了RPC框架来实现,在Java技术栈方向,我们选择了阿里巴巴开源的RPC框架 Dubbo,针对该场景的问题,我们扩展了Dubbo框架的源码实现,提供了 Dubbo就近路由能力。
三、技术原理说明
在服务提供者注册服务时,把该实例节点的机房信息【我们内部将机房标签定义为 app_loc 字段】注册到注册中心,在开启了就近路由策略后,消费者在过滤服务列表时,会自动筛选、匹配和消费者自己 app_loc 字段相同的服务提供者列表,从而实现就近路由访问。我们实现的就近路由策略,在本机房存在对应服务提供者的情况下,消费者会优先调用本机房的服务。
四、实现方案
开源版本的Dubbo框架并不提供就近路由能力,我们需要基于Dubbo框架源码扩展实现。Dubbo框架整体设计如下:【左侧为服务消费者使用的接口,右侧为服务提供方使用的接口】。
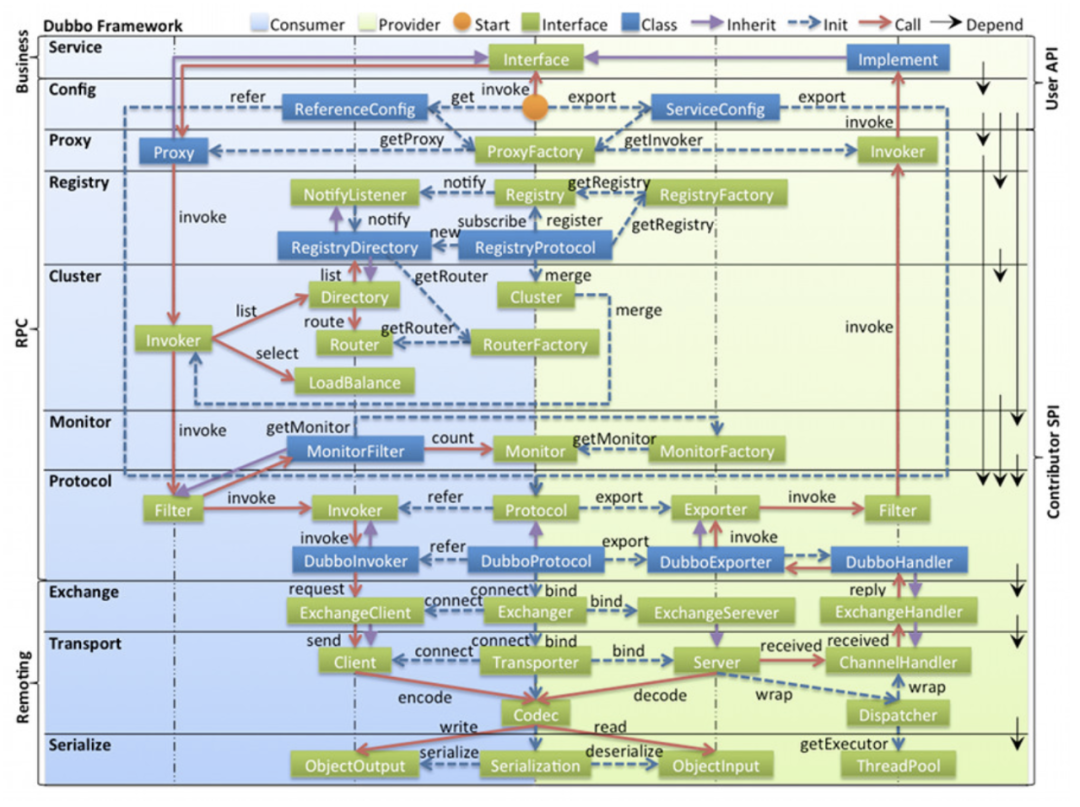

我们知道,Dubbo框架中服务消费者选择具体的服务提供者实例调用的匹配、筛选逻辑是在 Consumer 侧完成的,在 Cluster 层中,消费者会先应用用户配置的 Router 规则,然后再符合规则的服务提供者列表中,使用 LoadBalance 策略选择具体的服务提供者节点进行调用。
结合Dubbo框架源码实现,我们选择基于Dubbo 2.7.x版本的router层扩展口 org.apache.dubbo.rpc.cluster.Router 实现一种新的路由方式,即**就近路由(我们内部标识为 NearestRouter)**。
有了具体的解决方案,我们很快就完成了代码开发,内部也发布了一个集成就近路由策略的Dubbo版本,但在实际的线上灰度和业务推广过程中,我们实现的初版就近路由碰到了新的问题:
基于机房容量、机器成本等因素考虑,并不是所有的业务都实现了多机房部署,即有部分业务只实现了单机房部署,这部分业务的消费方无法实现同机房内部调用;
即使部分业务实现了多机房部署,但多个机房之间能提供的服务容量并不是相同的,对于服务容量较小的机房,如果一部分服务节点不可用,剩下的服务节点能提供的服务容量无法支撑本机房的消费方调用时,会造成该机房内的服务节点雪崩;
业务侧在开启就近路由策略时,希望消费服务的业务方能逐个开启,有一段时间的灰度观察过程,保证更平滑的升级验证;而不是比较粗暴的要么开启,要么关闭;
部分消费者的Dubbo版本较低,不支持就近路由功能,或者不支持配置应用维度的就近路由,在业务灰度过程中,希望能实现向前兼容,业务侧不报错。
基于以上问题,我们细化了实现方案:
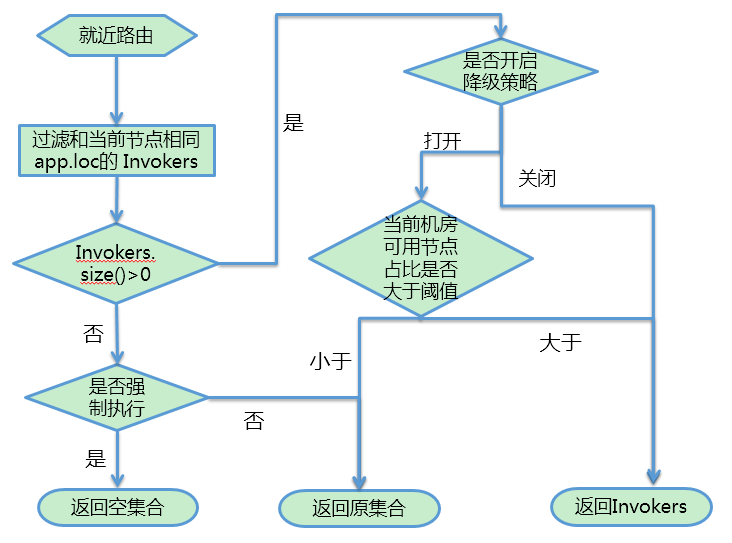
就近路由策略默认不强制执行,即当本机房不存在服务提供者时,不再区分本机房、跨机房,就近路由策略自动失效,优先保障服务之间的正常调用;
支持设置就近路由策略的降级阈值,在调用本机房服务的过程中,当 本机房服务实例数量 / 集群服务实例数量 得到的数值小于设置的降级阈值时,我们认为当前机房的服务容量无法支撑本机房的消费方调用,就近路由策略自动失效;
支持配置应用维度的就近路由策略,即配置的就近路由策略可只针对配置的应用生效,实现应用维度的灰度效果;
实现Dubbo版本自动校验能力,不满足开启就近路由策略条件的业务,提示用户不开启。
有了以上细化方案,我们梳理的就近路由大致逻辑流程如下:

扩展Dubbo框架 Router 接口实现的 NearestRouter 核心代码如下:
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL consumerUrl, Invocation invocation) throws RpcException {
// validate application name (this.url -> routerUrl)
String applicationName = getProperty(APP_NAME, consumerUrl.getParameter(CommonConstants.APPLICATION_KEY, ""));
boolean validAppFlag = application.equals(applicationName) || CommonConstants.ANY_VALUE.equals(application);
if (!validAppFlag) {
return invokers;
}
String local = getProperty(APP_LOC);
if (invokers == null || invokers.size() == 0) {
return invokers;
}
List<Invoker<T>> result = new ArrayList<Invoker<T>>();
for (Invoker invoker: invokers) {
String invokerLoc = getProperty(invoker, invocation, APP_LOC);
if (local.equals(invokerLoc)) {
result.add(invoker);
}
}
if (result.size() > 0) {
if (fallback){
// 开启服务降级,available.ratio = 当前机房可用服务节点数量 / 集群可用服务节点数量
int curAvailableRatio = (int) Math.floor(result.size() * 100.0d / invokers.size());
if (curAvailableRatio <= availableRatio) {
return invokers;
}
}
return result;
} else if (force) {
LOGGER.warn("The route result is empty and force execute. consumerIp: " + NetUtils.getLocalHost()
+ ", service: " + consumerUrl.getServiceKey() + ", appLoc: " + local
+ ", routerName: " + this.getUrl().getParameterAndDecoded("name"));
return result;
} else {
return invokers;
}
}
在vivo内部的服务治理平台上,我们提供了可视化的配置能力,页面内容如下:
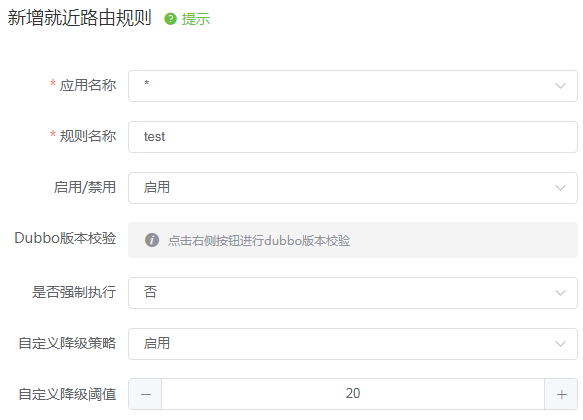
通过扩展Dubbo框架,服务治理平台能力支持,我们以上问题都得到了较好的解决。
五、写在将来
虽然以上解决方案能覆盖我们当前业务场景中的大部分问题,随着业务的高速发展,新的业务问题也接踵而至。
当前就近路由策略代码实现集成在Dubbo框架中,业务侧需升级Dubbo框架版本才能完成升级,升级周期长,框架碎片化问题趋向严重;
当前业务服务注册时携带的机房信息比较有限,例如缺失服务实例所在的机架信息,和当前服务同城的其他机房信息等,该类信息可支持我们实现更丰富的就近路由策略;
业务侧的流量灰度策略较丰富,除了就近路由策略之外、往往还需要结合Dubbo框架自带的条件路由、标签路由策略才能实现;
在特定场景下,就近路由策略失效由框架自动完成,业务侧缺少及时的感知能力。
针对以上问题,我们的解决思路如下:
适配云原生ServiceMesh技术方案,实现RPC框架复杂逻辑和业务代码的分层解耦,业务侧集成的SDK功能偏向简单,版本迭代较少,版本碎片化问题能得到较好解决;框架的复杂逻辑下沉到Agent端,框架升级业务基本无感知。幸运的是Dubbo 3.0 版本已规划增加对云原生的支持,我们将持续关注;
Dubbo框架的注册中心和内部CMDB系统结合,可以获取到更多维度的信息,不限于该服务节点所在的机架、同城的其他机房信息等。目前vivo内部已启动自研注册中心,可在该场景的能力建设上走的更远;
服务治理平台结合业务侧常用的流量灰度策略,提供结合就近路由、条件路由、标签路由的组合式路由策略,提供更丰富的流量路由能力;
针对框架错误、异常、自适应变更等的告警需求,vivo内部规划建设统一的框架SDK侧的监控告警能力,对于常见的错误、异常、自适应变更等,从SDK侧直接捕获,并和告警中心进行联动,缩短整个监控告警的链路路径,让业务侧能及时感知,甚至是提前感知。
作者:LuoLiang











