
在前端页面显示,为了避免一次性展示全量数据,通过上下翻页或指定页码的方式查看部分数据,就像翻书一样,这就利用了MySQL的分页查询。
一、MySQL的深分页
查询偏移量过大的分页会导致数据库获取数据性能低下,以如下SQL为例:
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
这句SQL会使得MySQL在无法利用索引的情况下跳过1000000条记录后,再获取10条记录,其性能可想而知。这种查询偏移量过大的场景我们称为深分页。
MySQL的深分页会带来性能下降等问题,而这个问题在分布式数据库场景下,会变得更加复杂。
二、分布式数据库的深分页
弹性数据库JED可以简单理解成分布式的MySQL数据库,这里以JED为例,介绍下大多数分布式数据库是如何做分页查询的。
2.1 弹性数据库的分页实现
以下图的例子,我们来介绍多分片数据库如何执行分页查询。t_order表以id作为主键以t_col1作为分片键,数据分布如下:
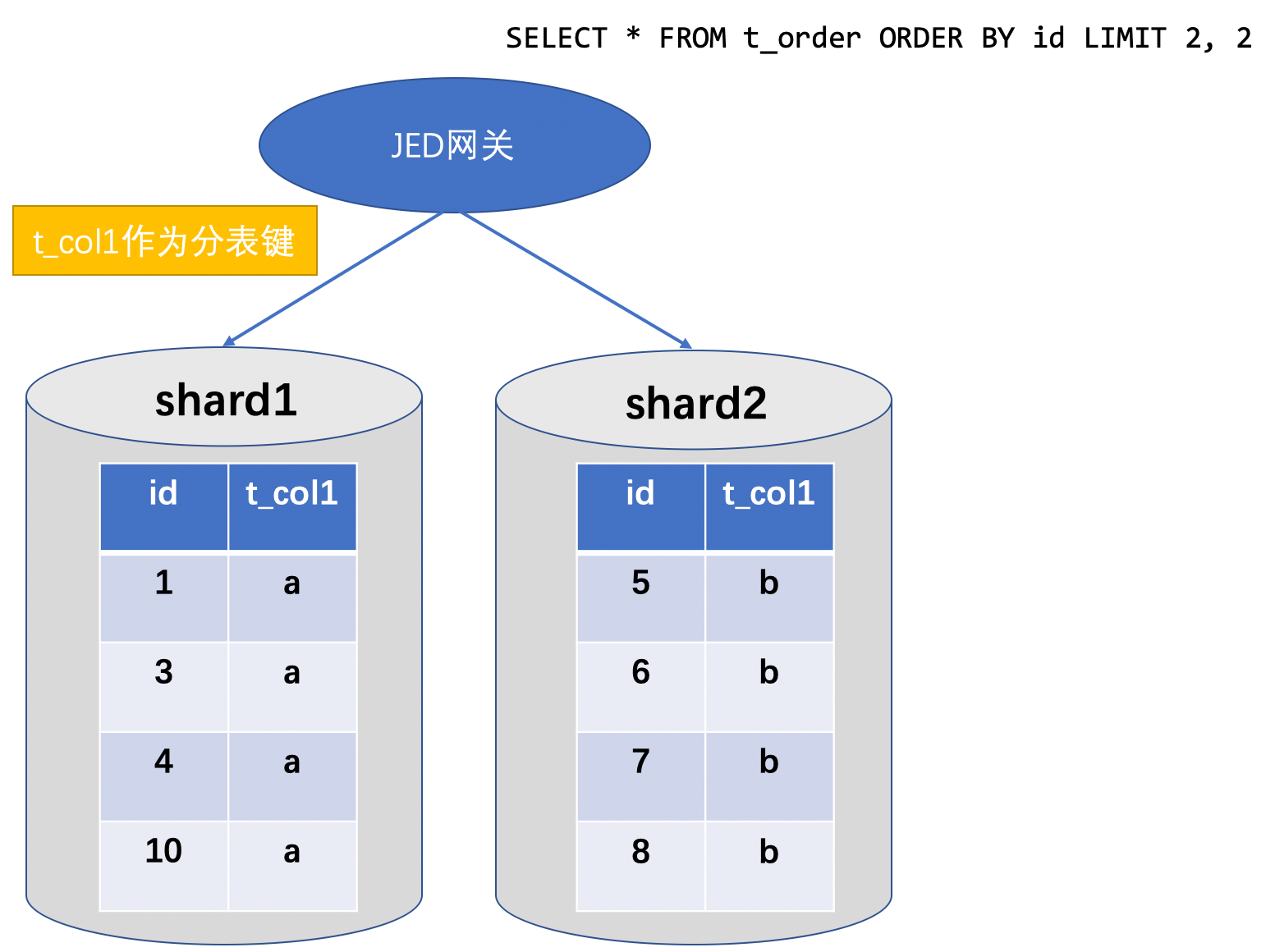
为了获取t_order表第2条之后的两条数据,执行SQL:
SELECT * FROM t_order ORDER BY id LIMIT 2, 2
假如只是简单的把SQL下推到每个分片的MySQL实例执行,再在内存中对返回结果进行聚合排序处理,会是什么效果呢?
分片1返回结果 {(id : 4, t_col1 : "a"), (id : 10, t_col1 : "a")};
分片2返回结果 {(id : 7, t_col1 : "b"), (id : 8, t_col1 : "b")};
内存排序计算后,将结果{(id : 4, t_col1 : "a"),(id : 7, t_col1 : "b")}返回,显然这是一个错误的结果。为了得到正确的结果,需要每个分片都获取前4条(2+2)数据,之后在内存中进行排序后分页。因此,每个分片执行的SQL改写为:
SELECT * FROM t_order ORDER BY id LIMIT 0, 4
再将返回的结果集在内存排序后,取第2条之后的两条数据{(id : 4, t_col1 : "a"),(id : 5, t_col1 : "b")} 返回用户。
2.2 深分页存在的问题
由于分布式场景下,分页语句会被放大。而这个问题,在执行深分页SQL时(查询偏移量过大),更加严重。深分页会导致数据库性能急剧下降,并且占用大量的CPU、内存资源用于聚合排序运算。
当执行以下SQL,获取1000000之后的10条数据:
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
在多分片场景下,为了保证数据的正确性,SQL会改写为:
SELECT * FROM t_order ORDER BY id LIMIT 0, 1000010
将改写后的SQL发送至每一个分片执行,并将结果集返回,对结果集汇总处理后,把排序后的10条记录返回给用户。可以发现原SQL仅需要传输10条记录至客户端,而改写之后的SQL则会传输1000010 * 2的记录至客户端,这将极大增大了OOM风险。
三、VtDriver的深分页优化
3.1 SQL下推
VtDriver对查询条件中带有分片键,仅落至单一分片的查询进行进一步优化。 落至单分片查询的请求并不需要改写SQL也可以保证记录的正确性,因此在此种情况下,VtDriver并未进行SQL改写,从而达到节省资源的效果。
3.2 流式处理
应用侧主动开启流式查询功能。开启流式查询后,采用流式处理 + 归并排序的方式来避免内存的过量占用。由于SQL改写不可避免的占用了额外的带宽,但并不会导致内存暴涨。 与直觉不同,大多数人认为VtDriver会将1000010 * 2记录全部加载至内存,进而占用大量内存而导致内存溢出。 但由于每个结果集的记录是有序的,因此VtDriver每次比较仅获取各个分片的当前结果集记录,驻留在内存中的记录仅为当前路由到的分片的结果集的当前游标指向而已。 对于本身即有序的待排序对象,采用归并排序,将会进一步降低性能损耗。
3.3 深分页自动转为流式查询
针对深度分页,VtDriver提供了根据深度分页临界值,自动开启流式查询的方式。
应用可通过deepPaginationThreshold参数,设置深度分页临界值。比如limit N,M,当N>deepPaginationThreshold设置的值时,会转为流式查询。
四、深分页的优化建议
可以看到,即便VtDriver对于深分页进行了优化,但是深分页的使用场景还是会给应用带来了很大的压力。用户通过优化SQL才可以从根本上解决问题。
4.1 范围查询
当可以保证ID的连续性时,用户根据ID范围进行分页是比较好的解决方案:
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id
或通过记录上次查询结果的最后一条记录的ID进行下一页的查询:
SELECT * FROM t_order WHERE id > 100000 LIMIT 10
4.2 子查询
把查询条件,转移回到主键索引。由于子查询中只获取主键列对应的值,可以一定程度上降低应用OOM风险。
改写后的SQL为(id为表t_order的主键):
SELECT * FROM t_order WHERE id >= (SELECT id FROM t_order limit 1000000, 1) LIMIT 10;
数据量过大时,客户端仍有OOM风险,建议把子查询仅作为应急过渡方案。
作者:京东零售 金越
来源:京东云开发者社区 转载请注明来源







