
后端开发与云服务
云服务这个词,大概最早是从云盘开始的,那时候概念也特别简单,无非就是把一些数据存在别人的服务器上,在”云存储”这个名词火起来之前,QQ 也有提供网站的功能用来存一些小东西(05年06年的样子,那时候大概只有几十 M 的空间),其实刚听到这个概念的时候我就很不理解,光存存东西不至于吹得这么玄乎吧。毕业后入行,云服务器才慢慢真真的丰富起来,从最开始的 VPS 变成云服务器、存储变成资源服务器、远程数据库等等,现在甚至有帮你防 DDOS 的服务(去年和今年貌似 DDOS 变得越来越没有节操了)。确实节省了很多精力,也省钱。
除了云,最近几年还有另外一个比较火的词:"大数据”。我没接触过那么大的数据,作为一个半吊子运维,接触的最大的数据应该就是服务器 log 了。所以大数据的东西以后有机会接触再说,对我来说更重要的是 — 数据统计。
服务端的各种 log 不仅是分析服务器的状态的重要参数,也是从后台代码里抓 bug 抓异常检查 SQL 性能等各种工作的参考。log 数据一般都是单调而且重复的居多,要发现它的价值,往往需要大量的分析和统计工作。各种监控服务、分析工具也是层出不穷。不过到今年我才知道有个词叫 "APM"。
APM (Application Performance Management/Monitoring) 简单翻译过来就是"应用性能管理/监控”(也许说监控更准确一些)。大概就是服务器上部署的 awstats、nagios、zabbix 等一堆东西的集合。有服务器的地方就有云,既然这个事情这么麻烦,那就自然也可以交给别人来做了。
前几天找到了一个 Python 的小 web 框架:bottle,只有一个文件,简洁好用,觉得很不错,先是用它来做了一个简单的小应用(APP 下载,公司内部使用),准备这段时间尝试用它来自己写一个简单的博客系统,改造一下自己的博客,所以业务时间花在搞 Python 上的比较多一点。恰好看到了在测 Python 版本的探针,于是部署来测试一下。部署之前先在本地做了一些测试,不过听云目前仅支持基于 django 开发的程序(文档上写的目标是支持所有以 wsgi 协议部署的 Python Web 服务,包括 flask、tornado 等等,不过这个应该还要等后续开发支持了),所以我就先在本地用 django 测了一下。
听云探针(Python版)的使用
探针部署过程十分简单,在听云后台复制自己账户的 license key,生成配置文件,将配置文件地址加载到环境变量中,就可以启动程序开始使用了。以下是测试环境部署步骤的介绍。
先用 virtualenv 开辟一个环境并 active 之:
virtualenv tingyun
cd tingyun
source bin/active
听云探针在 pypi 的仓库里有,所以可以直接安装了,同时也安装 django , 探针支持 MySQL 的 log 记录,所以我也安装了 MySQL 的组件并将 django 的数据库从 sqlite 改成 MySQL:
# 安装组件
pip install tingyun django MySQL-python
# 创建一个 django 工程
django-admin startproject www
接着需要修改一下 django 的数据库选项,进入到 www/www 目录,打开 settings.py,找到 DATABASE 的字典,注释掉原有的 sqlite 选项并改为 MySQL:
# 'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
# }
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'django',
'USER': 'root',
'PASSWORD': '',
'HOST': '',
'PORT': '',
}
在 MySQL 中创建 django 的库,然后安装 django 的 admin 后台需要的数据表(注意回到 manage.py 所在的目录):
python manage.py syncdb
接下来设置听云的服务,按照听云后台的提示和文档说明进行就可以了:
# YourLicenseKey 是你的听云后台里显示的 key
# 听云后台里将 tingyun.ini 放置在 tmp 目录,我建议你放在当前工作目录,免得丢失
# 一些配置参数可以打开 tingyun.ini 进行修改
tingyun-admin generate-config YourLicenseKey tingyun.ini
#
# 这里的 TING_YUN_CONFIG_FILE 写绝对路径比较保险,以下是我本地的目录
# 如果是在服务器上,可以写入到 .bashrc 或者 .bash_profile 中去,需要重启服务时不用重新设置
export TING_YUN_CONFIG_FILE=/Users/Scholer/Work/Personal/tingyun/tingyun.ini
#
# 听云的服务会读取当前环境变量的参数 TING_YUN_CONFIG_FILE 来获取配置文件
# 我们可以先检查一下,如果看到 success 字样就 OK
tingyun-admin check-config
万事具备,可以启动服务了:
tingyun-admin run-program python www/manage.py runserver
接下来我们就可以浏览一下页面,登录一下后台等等生成一些访问记录来看看效果了(或者可以比较残暴一点用测试工具,我用 ab 发了一些的测试请求)。
一切顺利的话,过一会儿刷新一下听云的后台,就能看到一些数据了。
有一些事情需要注意一下:
- 听云的多个应用是同一个 key,通过应用名称来区分应用;
- 不同于一些其他服务、听云没有新建一个 应用的过程,有部署、上报的数据就能看到数据了;
- 如果使用 uwsgi 的方式不是,需要开启
enable-threads和single-interpreter的选项。
上报数据观察
登录到听云的后台管理面板就能查看到一些监控日志分析了(图表是用 highcharts 做的,体验相当不错)。
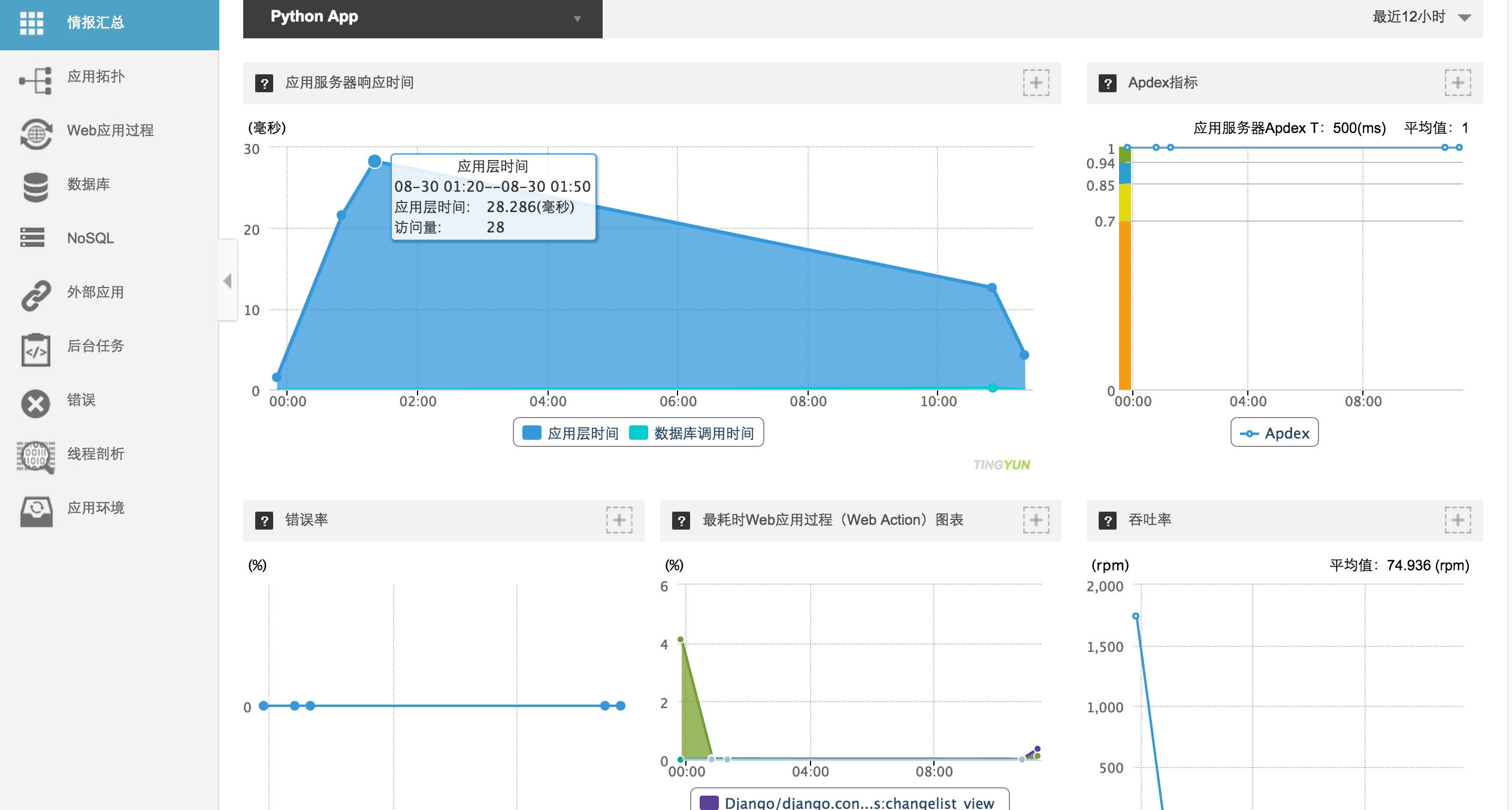
图中可以看到一些基本的数据图表,包括应用的响应时间、Apdex(应用程序性能指数),应用响应耗时和吞吐率等等。
此外面板上也会有硬件的基本信息,包括 CPU 的占用时间、内存占用等参数。
各项参数指标的统计最终目的都是为了分析服务器本身的承载能力和性能。当以上参数出现异常情况,比如响应时间过长、CPU负载过高或者内存剩余不多时,就要考虑升级硬件资源或者对程序进行优化了。
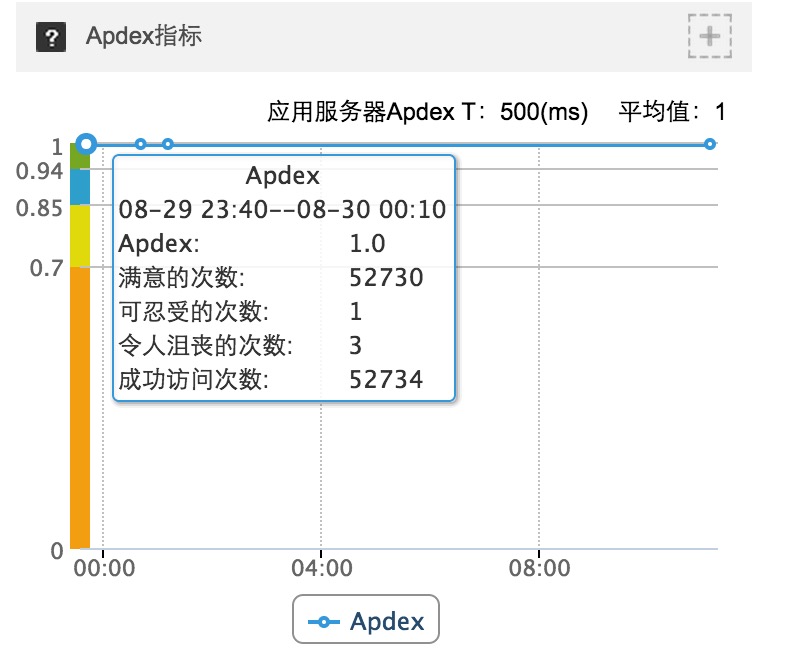
Apdex (Application Performance Index) ,应用性能指数。这是一个近几年成立的联盟组织,大概是在 2010 年发起的,12 年之后沉寂了两年,去年又开始活跃了。这个联盟意在通过一个统一的标准来计算和衡量应用程序的的性能,在它的 官网 中有一些专门的文章来介绍自己。
"Apdex is a way to study measurements of any experience that can be interpreted on a scale ranging from excellent to unacceptable. " (Apdex 用以学习解释从好到坏的评级标准的相关经验。)
Apdex 的计算在下面这篇文章用也有介绍:
Apdex = (正常样本 + 0.5 x 低质样本 + 0 x 高质样本) / 样本总量
我们可以这样把正常样本理解成正常的时间,低质和高质就分别表示响应的慢和快。显然计算结果从 1 到 0 就表示从好到坏。
详细介绍:http://www.apdex.org/index.php/2014/05/apdex-is-not-just-for-application-performance/
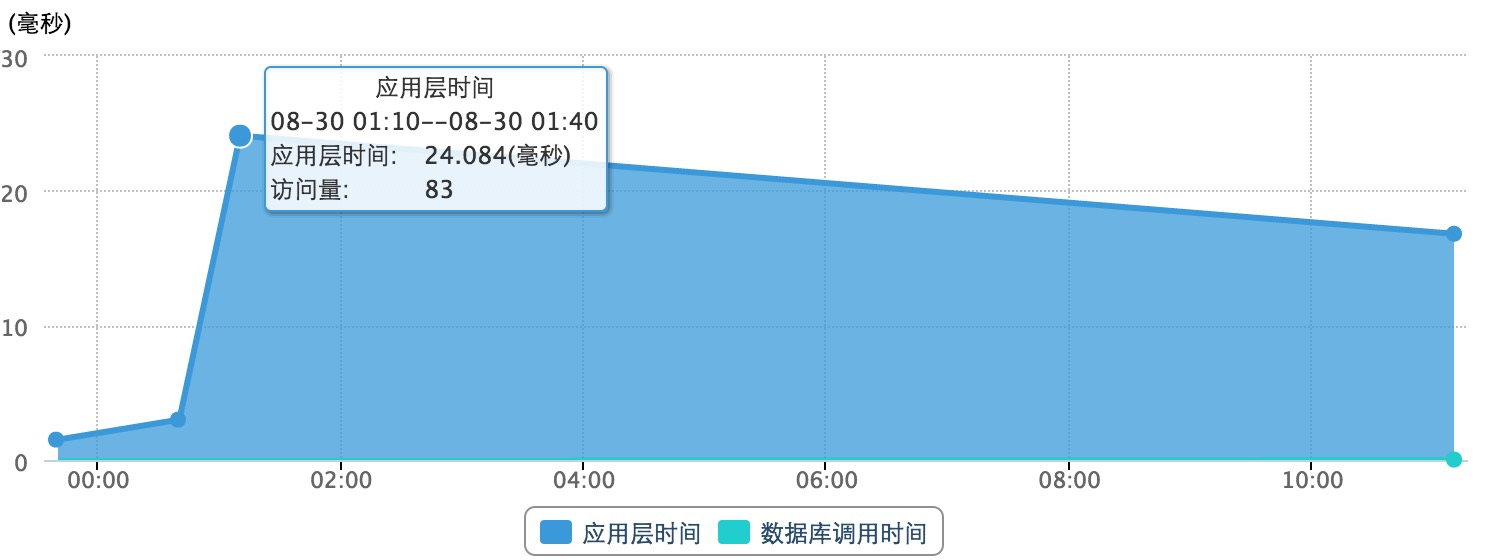
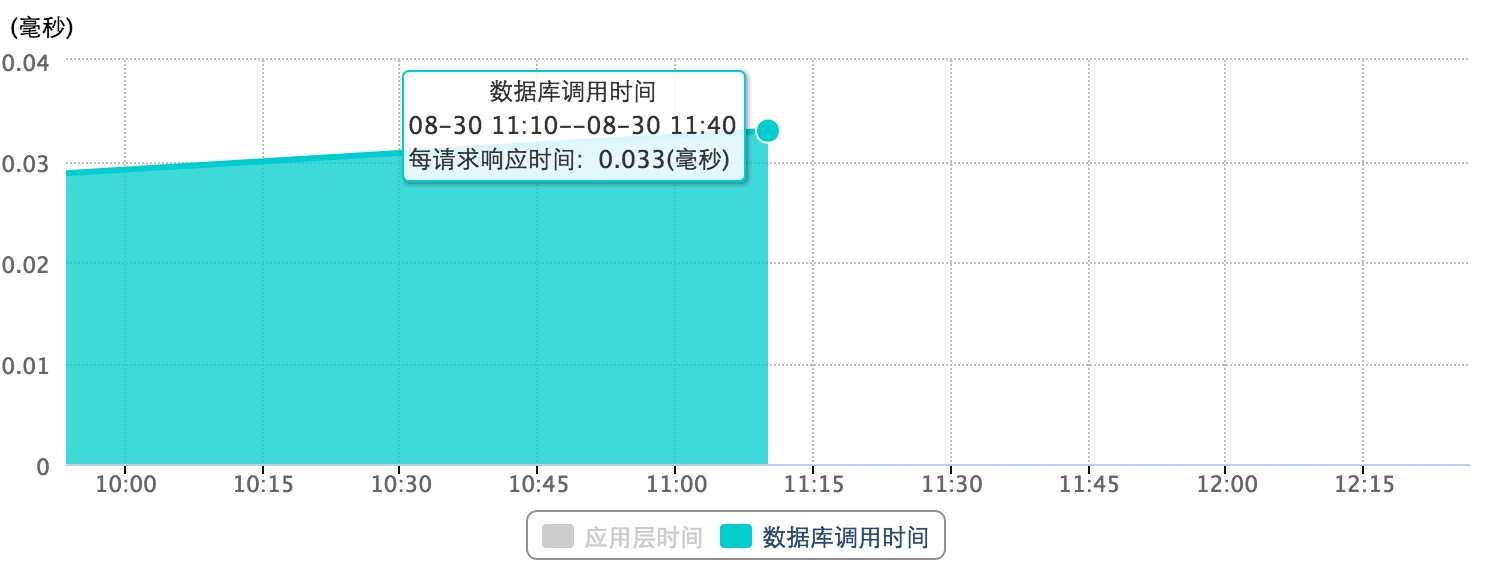
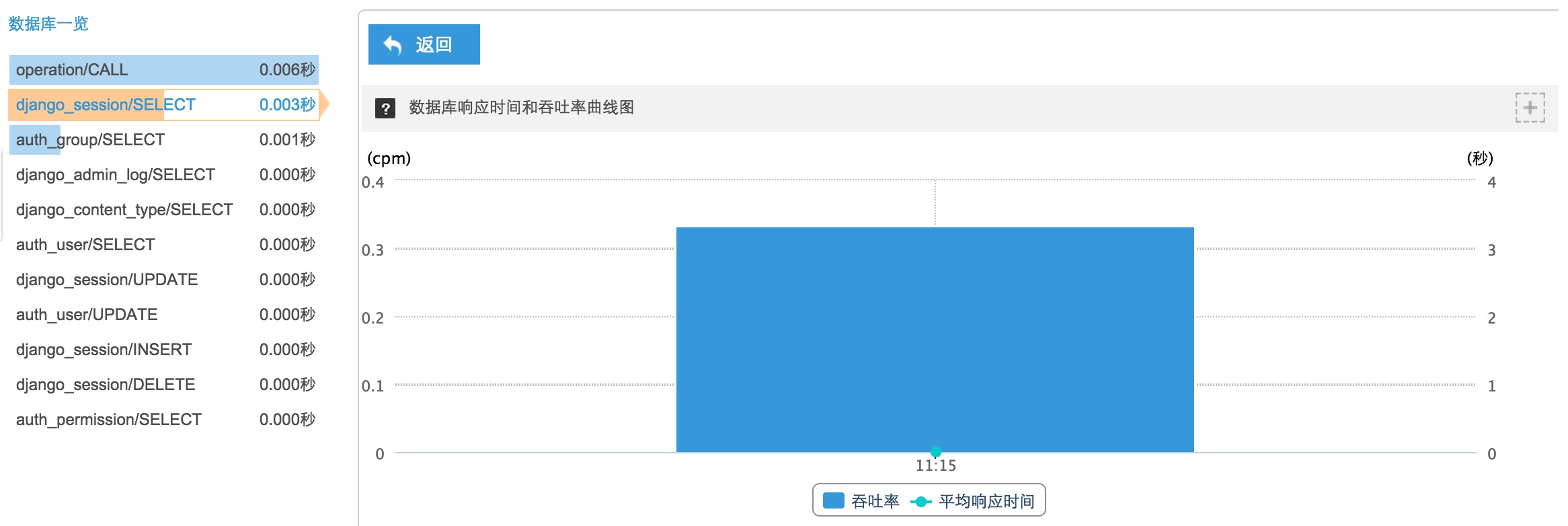
以上两张统计图分别展示了应用层的处理时间与数据库调用时间。这两个参数是对程序和 SQL 语句进行优化的重要参考。这里应该是计算的平均时间。
在实际的分析过程中,我们也同样需要对于所有耗时过长的处理或者 SQL 慢查询进行分析和优化。听云也提供了对于耗时应用和 SQL 的统计。
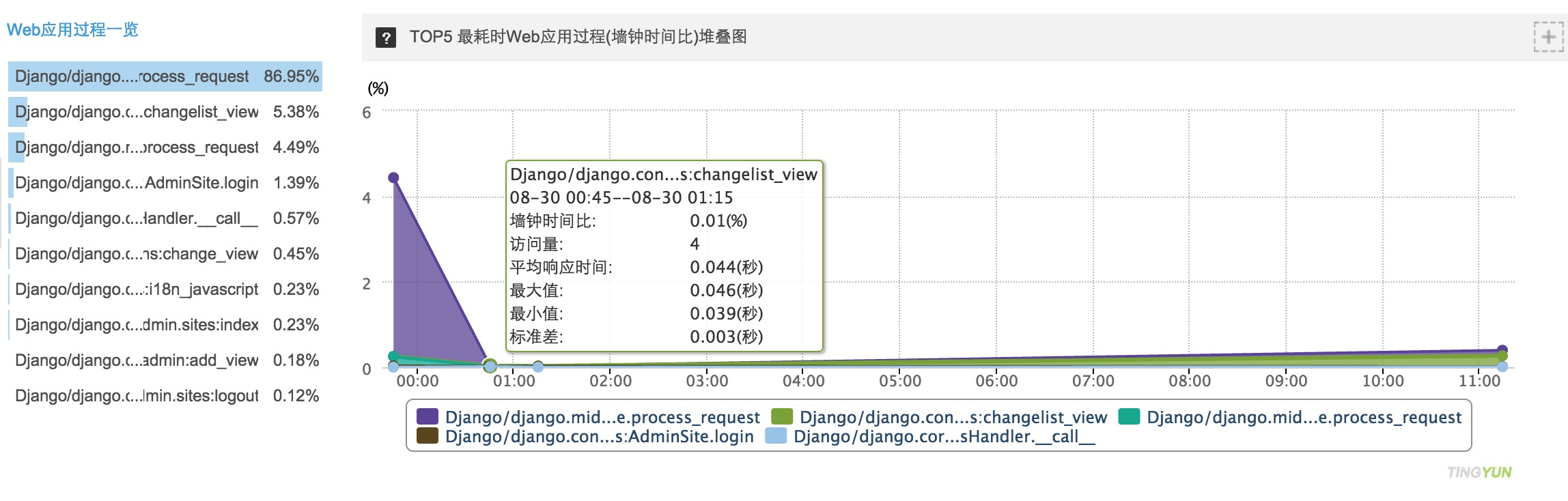
在上面的"最耗时的应用过程"中,有一个墙钟时间比的概念。墙钟时间(Wall-clock time / wall time)指的是程序从开始执行到结束的过程中人的时间感知(这个时间是大于 CPU 时间的,由系统提供)。墙钟时间比就表示当前时间点下某个程序占总墙钟时间的百分比。
除了常见关系型数据库的监控,听云也提供了对 memcached、Redis、MongoDB 等非关系型数据库的监控和统计。
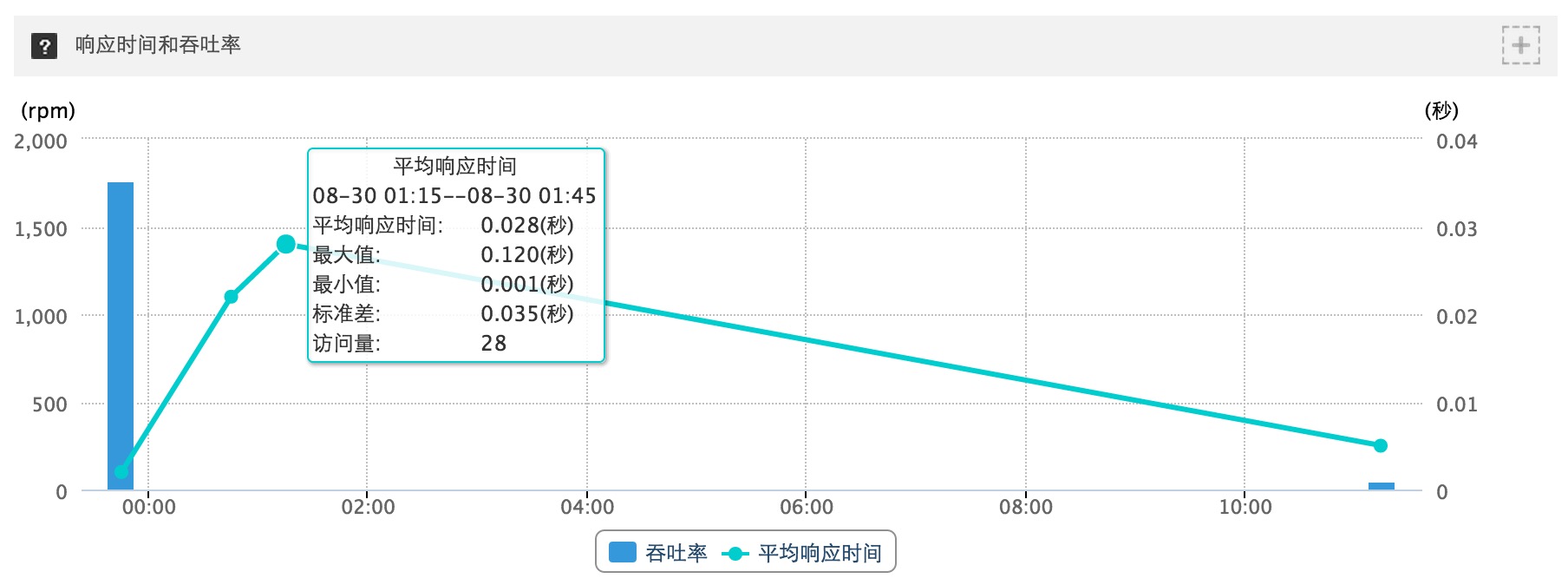
响应率和吞吐率参数参数。吞吐率指的是单位时间内响应的数量。这两个参数是对网站总体的响应速度和承载能力的评估。
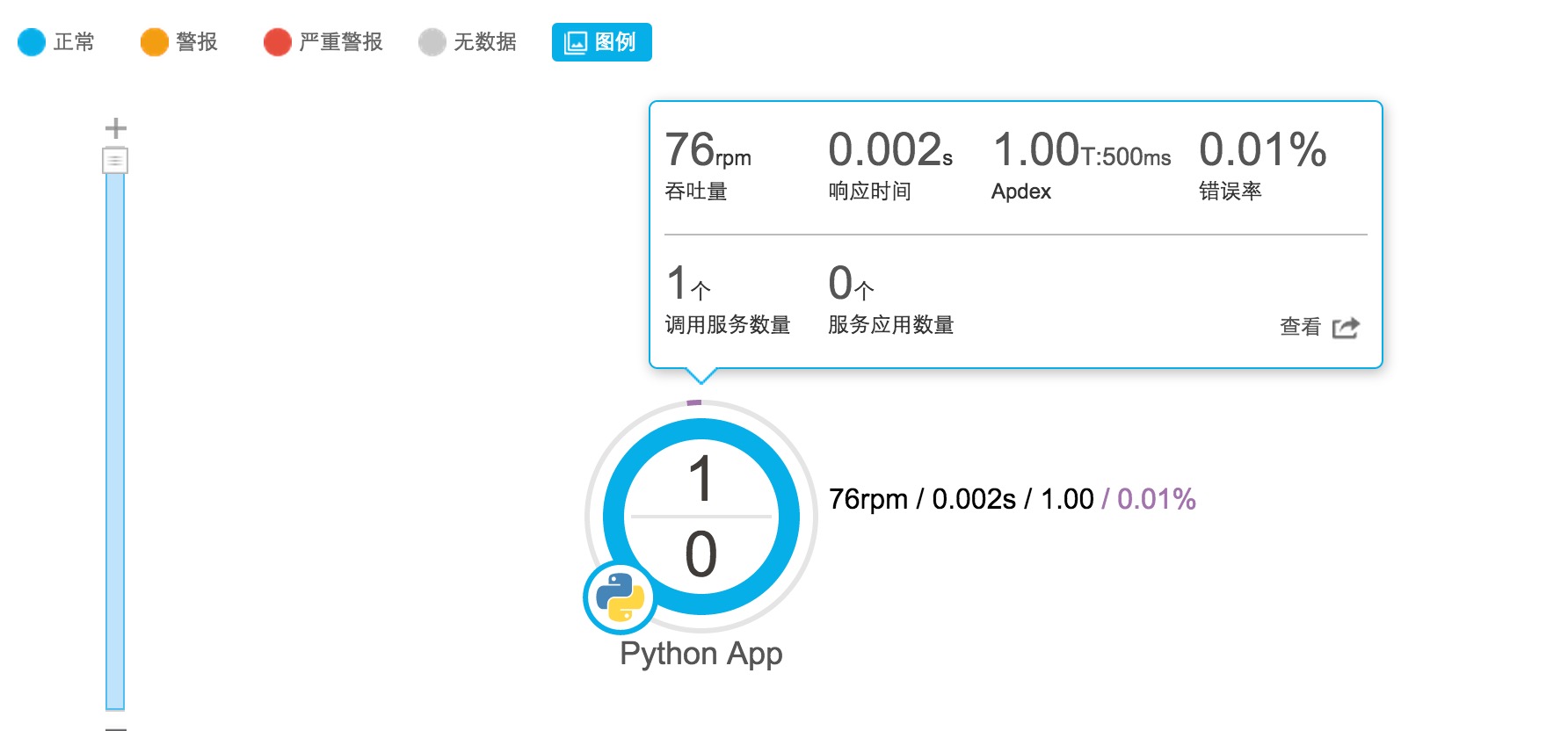
吞吐量、响应时间、Apdex和错误率的概览。
听云后台的参数记录十分全面,从硬件基础到程序响应到数据库执行耗时都有完整的分析和记录。不过遗憾的是在后台没有看到 HTTP 状态码的记录,类似 awstats 提供的记录和统计功能。不过相对于一个需要自己做复杂的配置的开源组件,优势还是十分明显的。我也相信随着时间的推移,服务会越来越丰富,这些信息都会被记录并分析出来。
简析
部署和数据分析都说了,现在也可以简单的来分析下听云是如何运作的。我无意去弄清楚探针工作的每一个步骤,但却可以了解一下大致的流程。
Python 作为一门胶水语言,已经积淀了丰富的优秀模块,历来都是被公认为作为服务端运维最强力的脚本语言,对于这类问题的处理上,具有天然的优势。听云在语言上也做了处理,能够同时支持 Python 2 和 Python 3。
在听云的配置文件 tingyun.ini 中,除了有 license_key 以外,还有 app_name、 log_file 、 log_level 等参数配置。其中 action_tracer.log_sql 可以选择是否将 SQL 日志只保存在本地文件中(这应该是出于安全考虑,毕竟把所有的 SQL 日志都暴漏给服务平台,有些人可能会有些顾虑。但是考虑到现在服务器一般都是云服务器,所以这其实问题也并不大,选择了服务,就应该相信服务),这点听云考虑的很周到。
log 文件中记录了一些 trace 的log,包括程序耗时等。
回到程序本身中去,在启动探针的时,我们执行的是 tingyun run-program,最终执行的是听云的 package 中 admin 目录下的 run_program 的函数,check_config、generate_config 也位于 admin 目录下。整个程序目录还包括 bootstrap 、hook 和 api 目录。
root_directory = os.path.dirname(root_directory)
boot_directory = os.path.join(root_directory, 'bootstrap')
python_path = boot_directory
run_program 将 bootstrap 目录加入系统 path 中。通过 Python 提供的两个 hook(sitecustomize 和 usercustomize 之中的 sitecustomize,听云探针正式被加载到运行环境中:
if config_file is not None:
# When installed as an egg with buildout, the root directory for
# packages is not listed in sys.path and scripts instead set it
# after Python has started up. This will cause importing of
# 'tingyun' module to fail.
if root_directory not in sys.path:
sys.path.insert(0, root_directory)
import tingyun.agent
# Finally initialize the agent.
tingyun.agent.initialize(config_file=config_file)
在 tingyun.api.initial.config 中,initialize 函数被执行,调用 _process_module_builtin 函数,探针开始工作 :
_load_configuration(config_file=config_file)
if not _detect_done:
_detect_done = True
_process_module_builtin()
MySQL、Redis 等监控模块都位于 hook 目录下,通过 _process_module_definition_wrapper 函数将进程与监控模块进行绑定,包括 django 的主要模块以及常用的数据库等。在核心模块执行的时候触发监控,将数据回传到 api.tracert 模块进行处理。
而对于硬件信息的检测则由 api.platform.system_info 进行。
应用监控数据最终会由 api.tracert.uploader 上传到听云的服务器(host 的设置位于 api.settings 中,host 地址是 redirect.networkbench.com,所以看到你的服务器往这个域名发送请求时,不要觉得奇怪),通过听云的处理,我们就能看到应用程序的各种监控数据了。
对听云探针的简单分析就到这里,有兴趣的读者可以进一步深入研究。其实对于这类云服务,程序的本身都是透明的,不用有太大的安全顾虑,对于服务提供方而言,更重要的是数据的分析工作。
听云本身提供的服务器是非常优秀的,虽然目前还并非完美。我也期待服务能更加完善,提供更完善的数据分析。另外一方面,通过 tingyun-admin run-program 的方式启动程序,对开发者和服务器管理员来说可能有些侵入感。如果能用模块加载的方式调用,或许更符合某些开发者的习惯。












