

Service Mesh Virtual Meetup 是 ServiceMesher 社区和 CNCF 联合主办的线上系列直播。本期为 Service Mesh Virtual Meetup#1 ,邀请了四位来自不同公司的嘉宾,从不同角度展开了 Service Mesh 的应用实践分享,分享涵盖如何使用 SkyWalking 来观测 Service Mesh,来自陌陌和百度的 Service Mesh 生产实践,Service Mesh 的可观察性和生产实践以及与传统微服务监控的区别。
本文根据5月14日晚,G7 微服务架构师叶志远的主题分享《Service Mesh 高可用在企业级生产中的实践》整理。文末包含本次分享的视频回顾链接以及 PPT 下载地址。
前言
谈到 Service Mesh,人们总是想起微服务和服务治理,从 Dubbo 到 Spring Cloud (2016开始进入国内研发的视野,2017年繁荣)再到 Service Mesh (2018年开始被大家所熟悉),正所谓长江后浪推前浪,作为后浪,Service Mesh 别无选择,而 Spring Cloud 对 Service Mesh 满怀羡慕,微服务架构的出现与繁荣,是互联网时代架构形式的巨大突破。Service Mesh 具有一定的学习成本,实际上在国内的落地案例不多,大多是云商与头部企业,随着性能与生态的完善以及各大社区推动容器化场景的落地,Service Mesh 也开始在大小公司生根发芽,弥补容器层与 Kubernetes 在服务治理方面的短缺之处。本次将以一个选型调研者的视角,来看看 Service Mesh 中的可观察性主流实践方案。
可观察性的哲学
可观察性(Observability)不是一个新名词,它在很久之前就已经诞生了,但是它在 IT 领域却是一个新兴事物。可观察性在维基百科中原文是这样定义的:“In control theory, observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. ”。云原生领域第一次出现这个词,是在云原生理念方兴未艾的2017年,在云原生的思潮之下,运用传统的描述方式已经不足以概括这个时代的监控诉求,而 Observability 就显得贴切许多。

回想一下传统的监控方式,除去运维层面的主机监控、JVM 监控、消息队列监控之外,有多少监控是事先就想好怎么做的?很少!其实很多时候,我们做的事情就是在故障发生之后,对故障复盘的过程中,除了 bug 重现与修复,也会去定制加一些监控,以期望下次发生同样的情况时有一个实时的告警。研发人员收到告警之后得以快速地处理问题,尽可能地减少损失。所以,传统的监控模式大多都是在做亡羊补牢的事情,缺少一个主动性。
在云原生时代的容器化体系当中就不一样了,容器和服务的生命周期是紧密联系在一起的,加上容器完美的隔离特性,再加上 Kubernetes 的容器管理层,应用服务跑在容器当中就显得更加地黑盒化,相较在传统物理主机或者虚拟机当中,排查问题的时候显得非常不便。所以在云原生时代强调的是可观察性,这样的监控永远都是兵马未动而粮草先行的,需要提前想好我们要如何观察容器内的服务以及服务之间的拓扑信息、各式指标的搜集等,这些监测能力相当重要。

关于可观察性在云原生领域是何时开始流行起来的,没有一个很明确的时间。业界认为可观察性最早是由 Cindy Sridharan 提出的,其实一位德国柏林的工程师 Peter Bourgon 早在2017年2月就已经有文章在讨论可观察性了,Peter 算是业界最早讨论可观察性的开发者,他写的著名的博文《Metrics, Tracing, and Logging》被翻译成了多种语言。真正可观察性成为一种标准,是来自 Pivotal 公司的 Matt Stine 定义的云原生标准,可观察性位列其中,由此可观察性就成为了云原生时代一个标准主题。
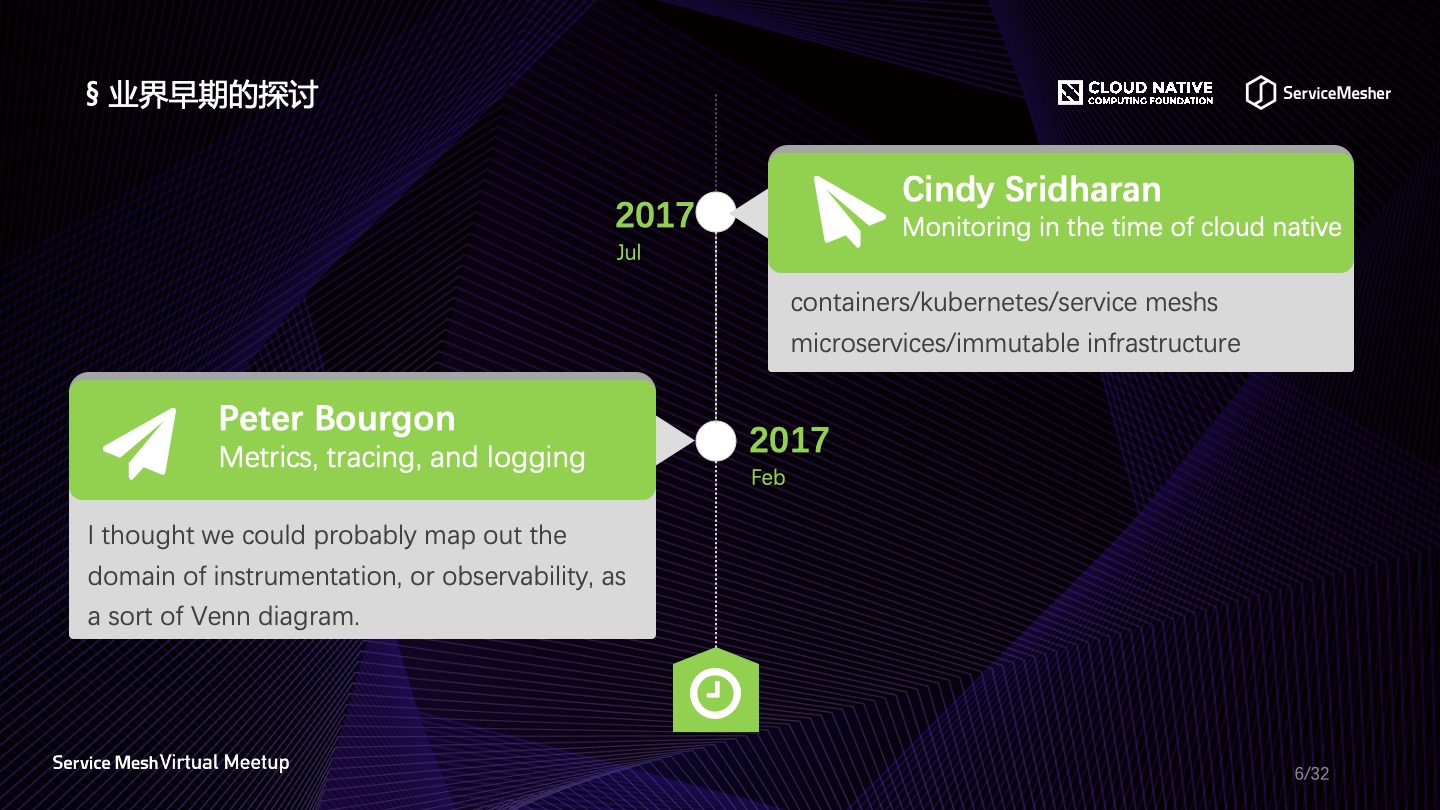
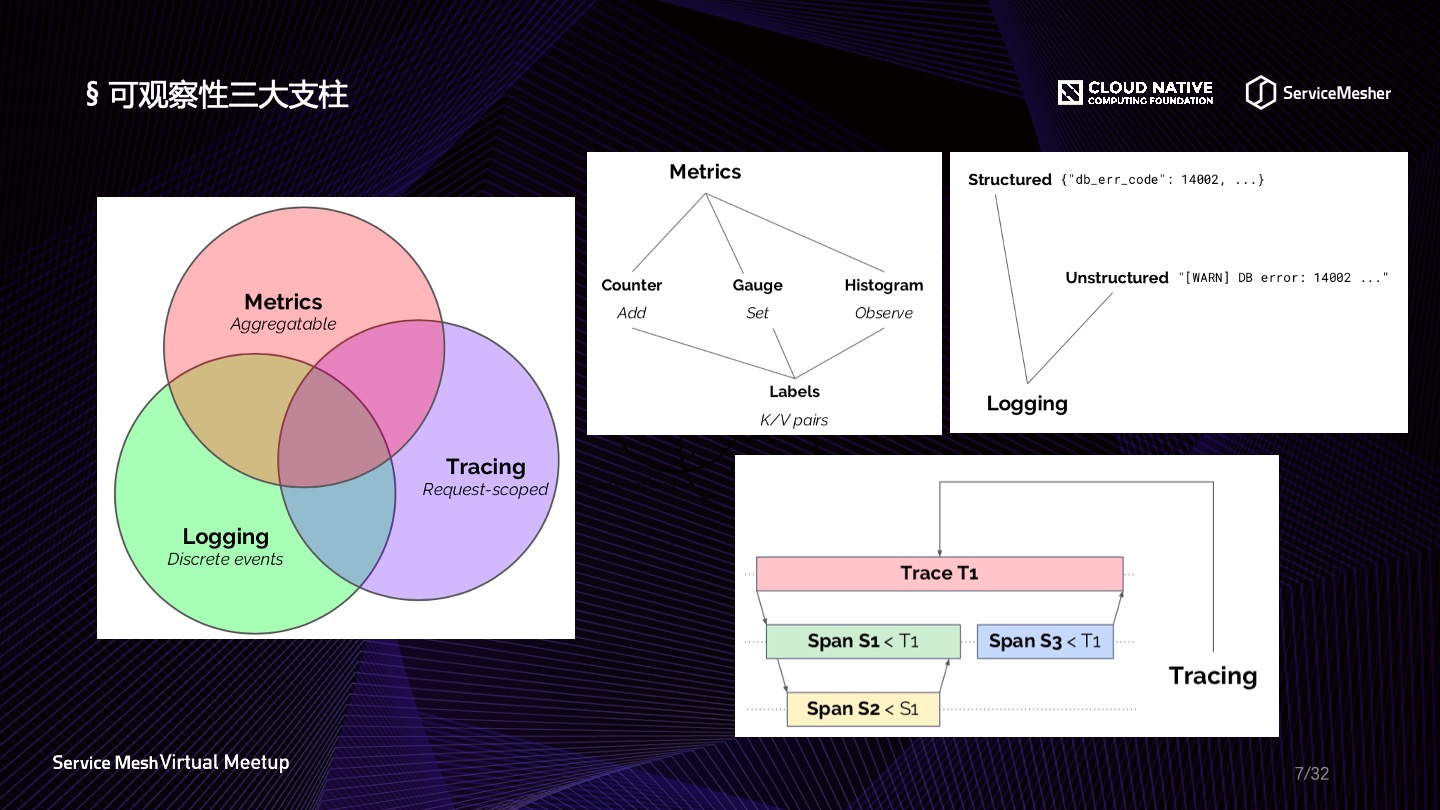
Peter Bourgon 提出的可观察性三大支柱围绕 Metrics、Tracing 和 Logging 展开,这三个维度几乎涵盖了应用程序的各种表征行为,开发人员通过收集并查看这三个维度的数据就可以做各种各样的事情,时刻掌握应用程序的运行情况,关于三大支柱的理解如下:
- Metrics:Metrics 是一种聚合态的数据形式,日常中经常会接触到的 QPS、TP99、TP95 等等都属于Metrics 的范畴,它和统计学的关系最为密切,往往需要使用统计学的原理来做一些设计;
- Tracing:Tracing 这个概念几乎是由 SOA 时代带来的复杂性补偿,服务化带来的长调用链,仅仅依靠日志是很难去定位问题的,因此它的表现形式比 Metrics 更复杂,好在业界涌现出来了多个协议以支撑 Tracing 维度的统一实现;
- Logging:Logging 是由请求或者事件触发,应用程序当中用以记录状态快照信息的一种形式,简单说就是日志,但这个日志不仅仅是打印出来这么简单,它的统一收集、存储以及解析都是一个有挑战的事情,比如结构化(Structured)与非结构化(Unstructed)的日志处理,往往需要一个高性能的解析器与缓冲器;
此外,Peter Bourgon 在博文中还提到了三大支柱结合态的一些理想输出形式,以及对存储的依赖,Metrics、Tracing、Logging 由于聚合程度的不同,对存储依赖由低到高。更多细节,感兴趣的同学可以查看文末的原文链接。
Peter Bourgon 关于可观察性三大支柱的思考不止于此,他还在2018年的 GopherCon EU 的分享上面再次讨论了 Metrics、Tracing 和 Logging 在工业生产当中的深层次意义,这次他探讨了4个维度。
- CapEx:表示指标初始收集成本,很明显日志的成本最低,埋点即可;其次是 Metrics,最难是 Tracing 数据,在有了协议支撑的情况下,依然要定义许多数据点,以完成链路追踪必须的元数据定义收集;
- OpEx:表示运维成本,一般指存储成本,这个之前已经讨论过;
- Reaction:表示异常情况的响应灵敏度,显然聚合之后的数据可以呈现出波动情况,因此 Metrics 是对异常情况最灵敏的;Logging 次之,也可以从 Logging 清洗之中发现异常量;而 Tracing 在响应灵敏度上面似乎沾不上边,最多还是用在排障定位的场景;
- Investigation:标准故障定位能力,这个维度是 Tracing 的强项,可以直观看出链路当中的故障,精确定位;Logging 次之;Metrics 维度只能反馈波动,对定位故障帮助不大;

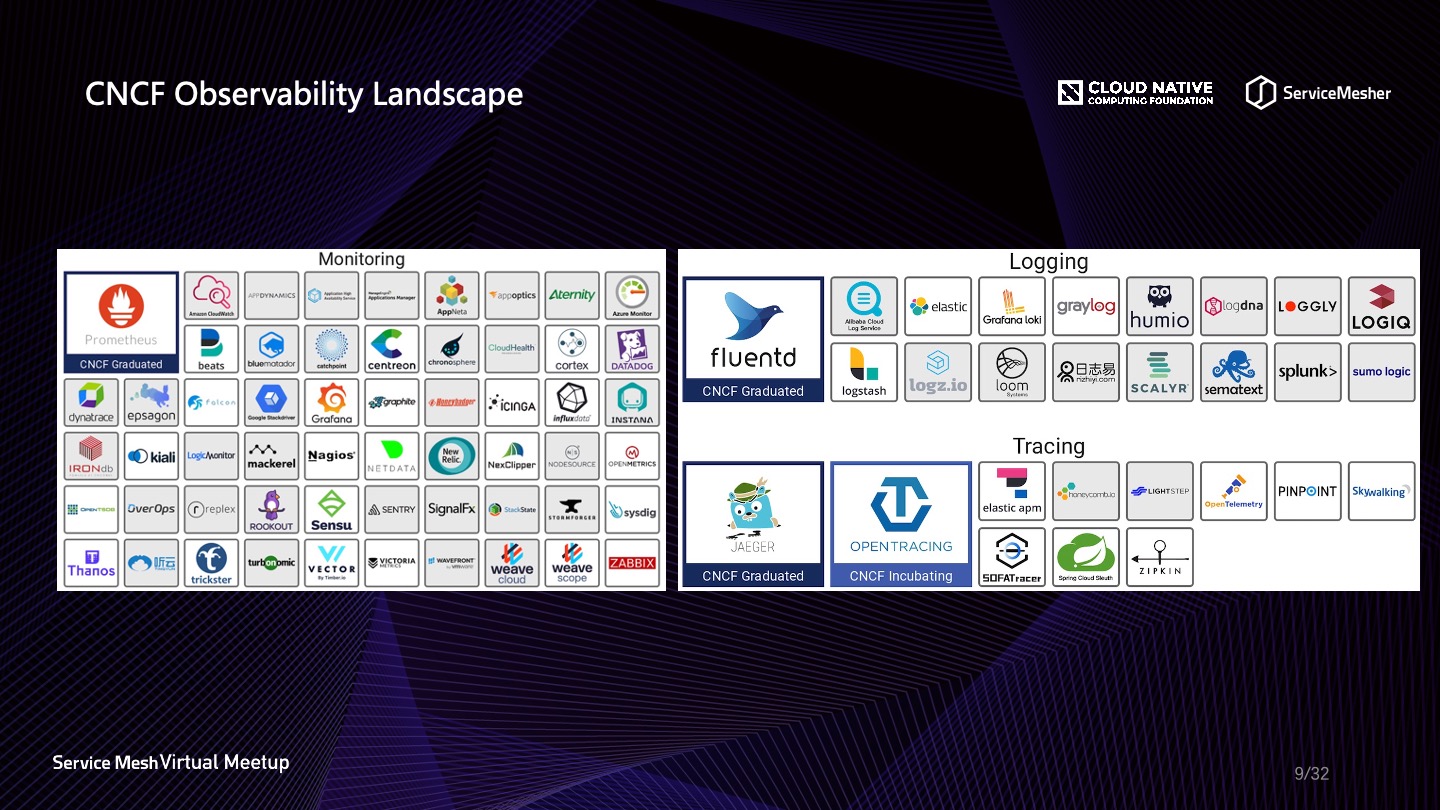
在 CNCF Landscape 当中,有一块区域专门用作展示云原生场景下的可观察性解决方案,里面又分为好几个维度,图中是截至2020年5月14日的最新版图,未来还会有更多优秀的解决方案涌现出来。CNCF 目前毕业的10个项目库当中,有3个是和可观察性有关的,可见 CNCF 对可观察性的重视程度。
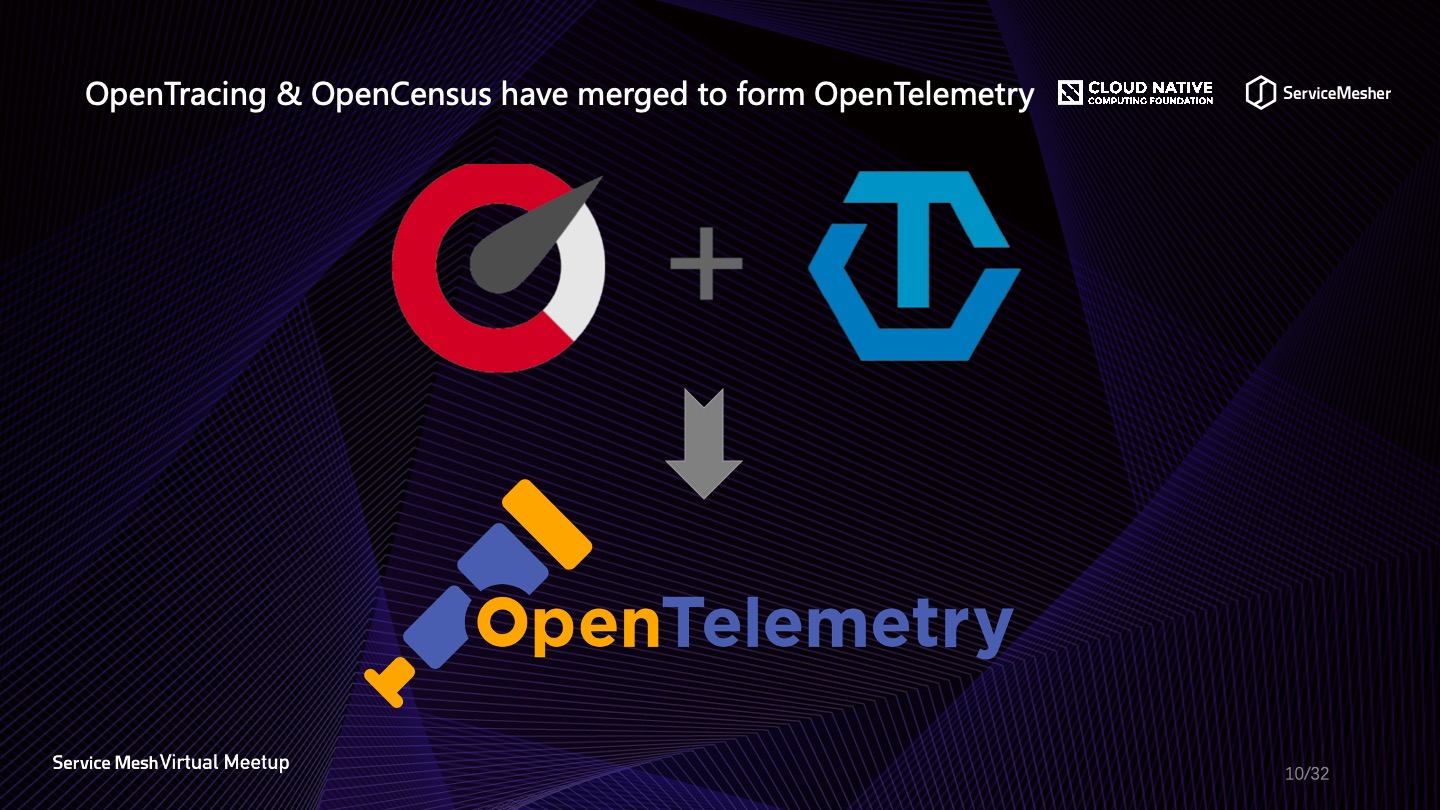
谈到这里,很多同学也许对于可观察性相关的协议比较感兴趣。目前比较火的有好几个,OpenTracing、OpenCensus、OpenTelemetry、OpenMetrics 等等,目前比较火的是前三个。OpenMetrics 这个项目已经不维护了。
OpenTracing 可以说是目前使用最广的分布式链路追踪协议了,大名鼎鼎的 SkyWalking 就是基于它实现的,它定义了与厂商无关,与语言无关的链路追踪协议 API,使得构建跨平台的链路追踪成为一件比较轻松的事情,目前它在 CNCF 的孵化器当中茁壮成长。
OpenCensus 是谷歌提出的一个针对 Tracing 和 Metrics 场景的协议,背靠 Dapper 的加持与历史背景,就连微软也十分拥护,目前在商用领域十分流行。
其他的协议比如 W3C Trace Context,呼声也很高,它甚至对数据在头部进行了压缩,与实现层无关。也许 CNCF 意识到各种协议又在层出不穷,以后各成气候,群雄逐鹿,每一个中间件都要做许多兼容,这对整个技术生态本身不利,因此 OpenTelemetry 横空出世。从字面意思就知道,CNCF 会将可观察性的“遥测”进行到底,它融合了 OpenTracing 和 OpenCensus 的协议内容,旨在提高云原生时代可观察性指标的统一收集与处理,目前 OpenTelemetry 已经进入 beta 版本,其中令人欣喜的是,Java 版本的 SDK 已经有一个类似 SkyWalking 的基于 byte-buddy 框架的无侵入式探针。目前已经可以从47种 Java 库当中自动探测获取遥测数据,另外推出了可供使用的 Erlang、Go、Java、JavaScript、Python 的 API 和 SDK。此外,数据收集器 OpenTelemetry Collector 也可以使用了,可以用它接收 OpenTelemetry client 发射过来的数据,统一收集处理。目前 CNCF 对 Logging 相关的协议制定暂缓,但是有一个工作小组也在做这方面规范的事情。
Service Mesh 与可观察性
要说 Service Mesh 与可观察性的关系,那就是可观察性是 Service Mesh 的功能子集。Service Mesh 是当今最为火爆的技术理念之一,它致力于为云原生时代运行在容器当中的大规模服务提供统一的服务发现、边缘路由、安全、流量控制、可观察性等能力,它是对 Kubernetes 服务治理能力的补充强化。可以说,Service Mesh 是云原生容器化时代的必然产物,它将对云上服务架构产生深远的影响。Service Mesh 的架构理念是将容器服务运行单元当成一个个网格,在每组运行单元中劫持流量,然后由一个统一的控制面板做统一处理,所有网格与控制面板维持一定的联系,这样,控制面板就得以作为可观察性解决方案与容器环境之间的桥梁。
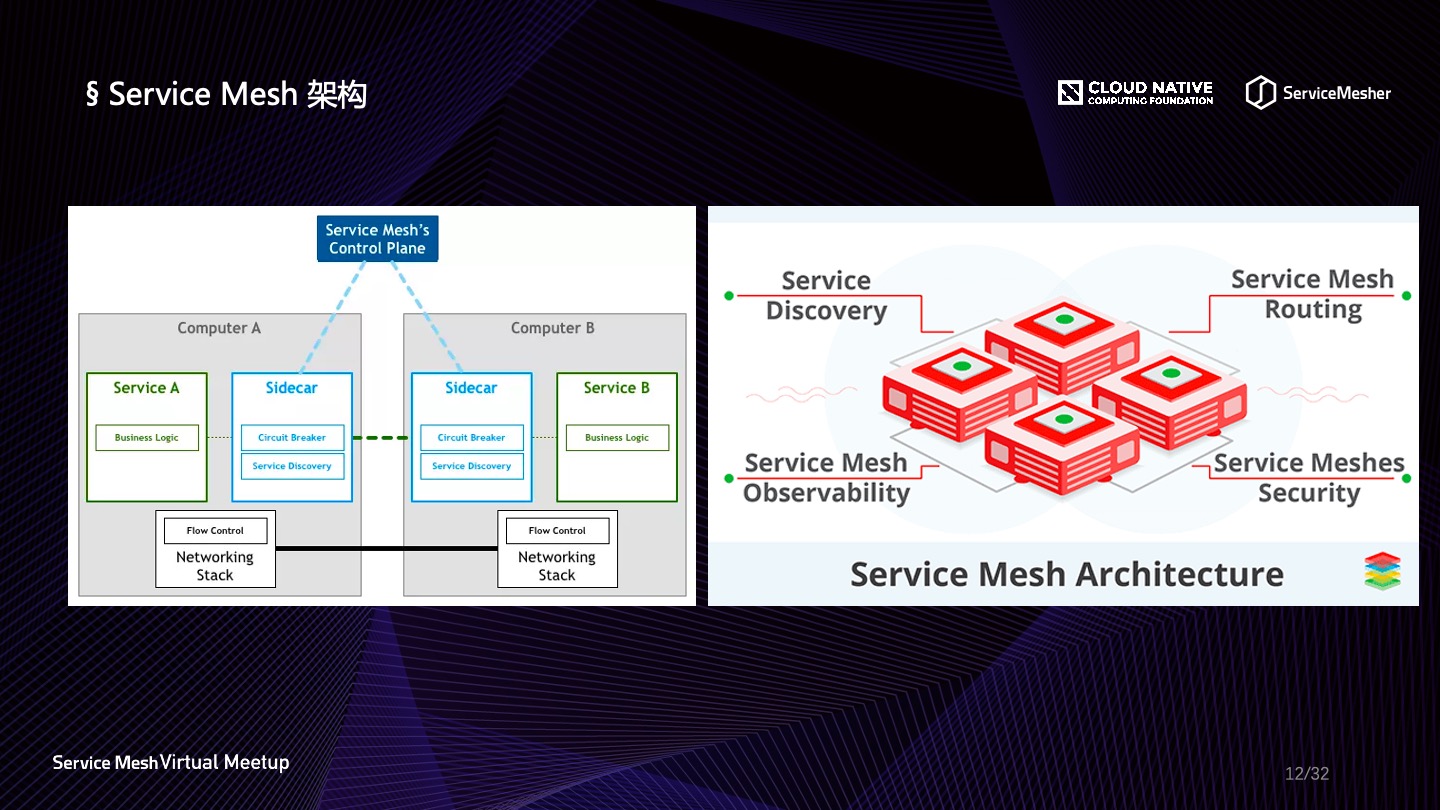
市面上最为常见的 Service Mesh 技术有 Linkerd、Istio、Conduit 等,但是要在生产环境落地必须要经受住严苛的性能、合理的架构、社区活跃度的评估。
Linkerd 是由 Buoyant 开发维护,算是 Service Mesh 领域第一代的产品,Linkerd1.x 基于 Scala 编写,可基于主机运行,大家都知道 Scala 运行环境依赖 JDK,因此对资源的消耗相对较大。随后官方进行了整改,推出了新一代的数据平面组件 Conduit,基于 Rust 和 Go 编写,与 Linkerd 双剑合璧,成为 Linkerd2.x。总体来说,Linkerd2.x 性能有了较大的提升,也有可视化界面供操作,但是在国内就是不愠不火的,社区始终发展不起来。
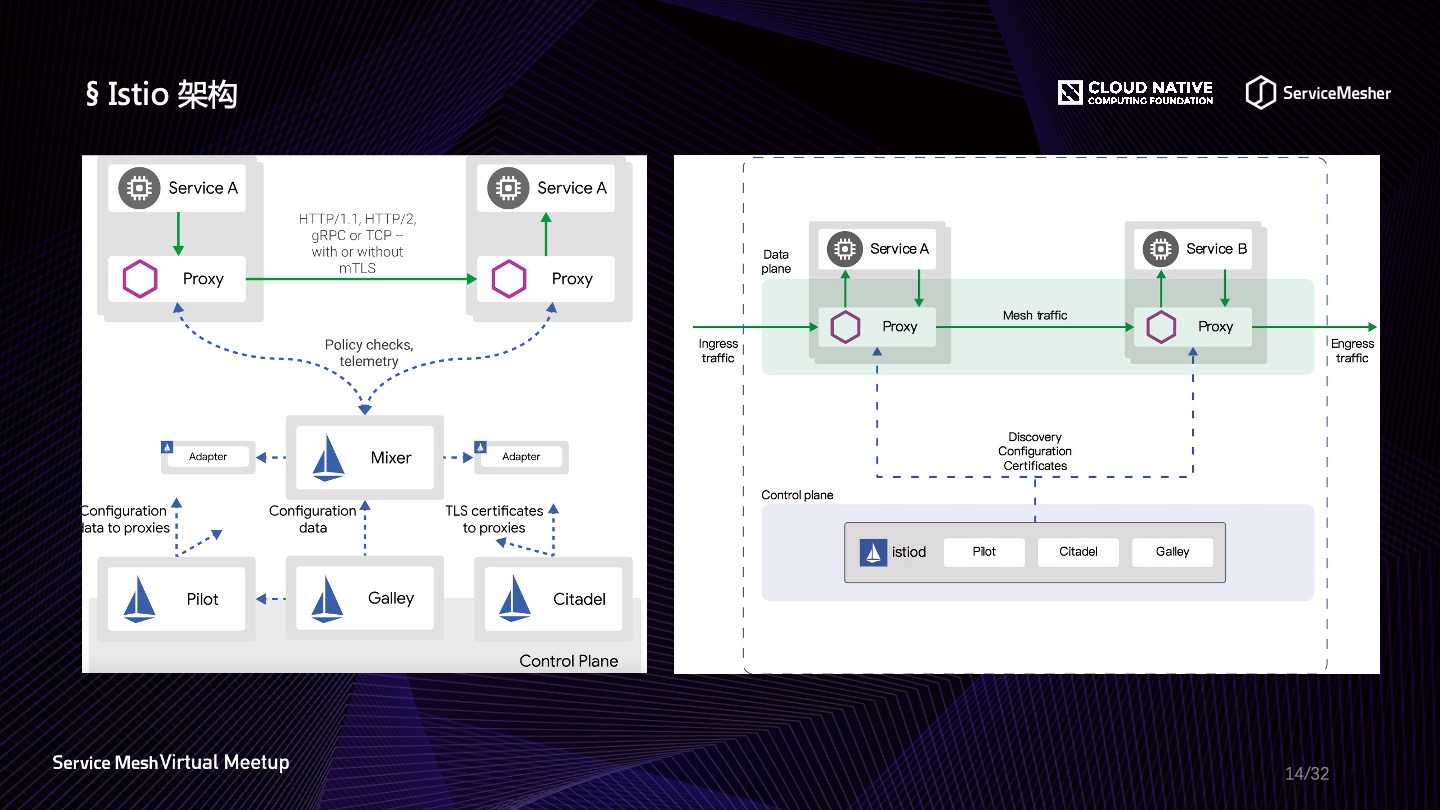
转头看2017年出现的 Istio,也算是含着金汤匙出生的,由谷歌、IBM、Lyft 发起,虽然晚了 Linkerd 一年,但是一经推出,就受到广泛的关注与追捧。Istio 基于 Golang 编写,完美契合 Kubernetes 环境,数据平面整合 Envoy,在服务治理方面职责分明,国内落地案例相较 Linkerd 更加广泛。

Istio 目前总体还算是一个年轻的开源中间件,大版本之间的组件架构有比较大的区别,比如 1.0 引入了Galley(如图左),1.5 去掉了 Mixer,并且控制平面整合成单体,增加了 WASM 扩展机制(如图右)。总体的架构形式没有太大变化,数据面还是关注流量的劫持与转发策略的执行,控制面依然做遥测收集、策略下发、安全的工作。目前国内业界对于 Istio 的使用上,云商与头部公司处于领先位置,比如蚂蚁金服自研了自己基于 Golang 的数据平面 MOSN,兼容 Istio,做了许多优化工作,对 Istio 在国内落地做出了表率,更多的信息可以深入了解,看如何打造更适合国内互联网的 Service Mesh 架构。
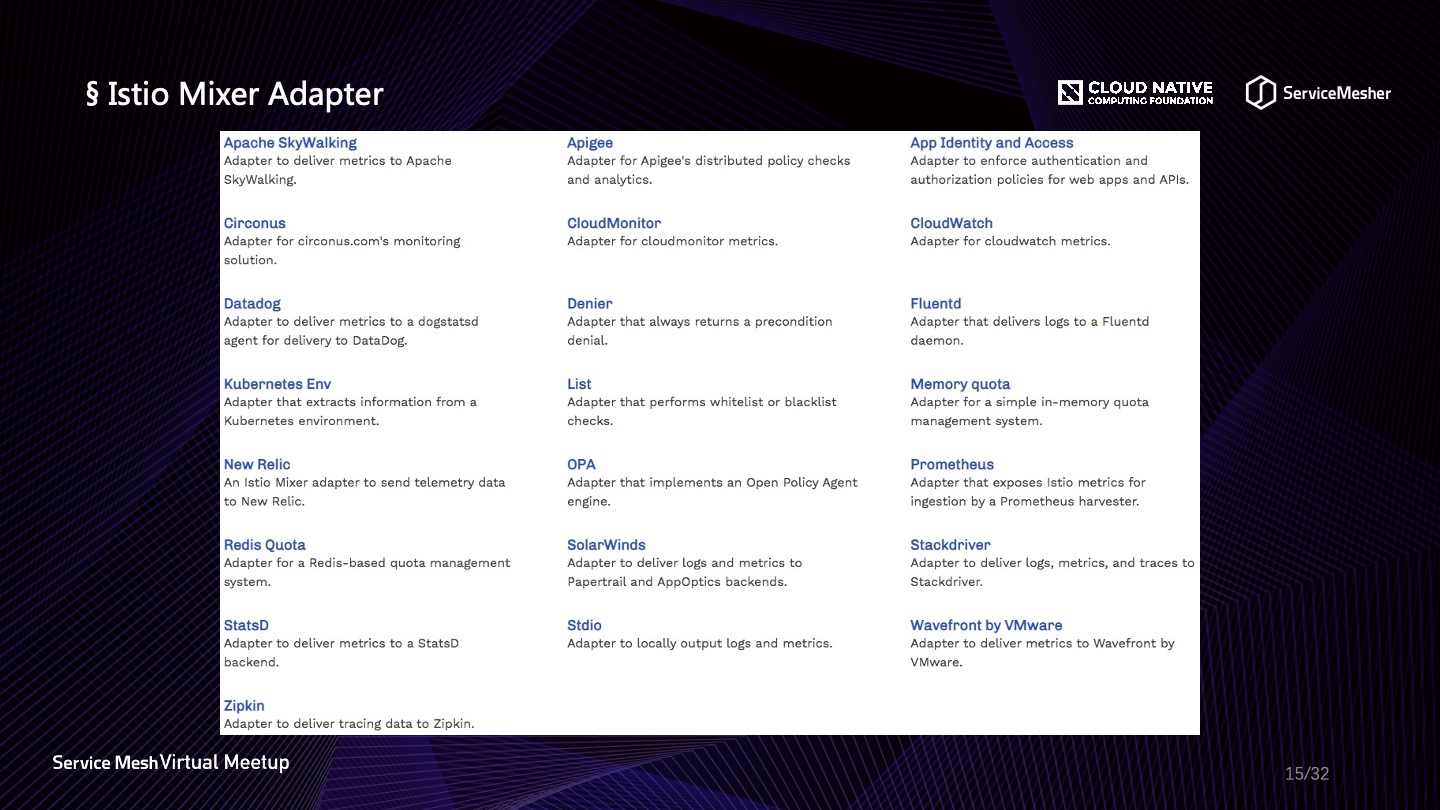
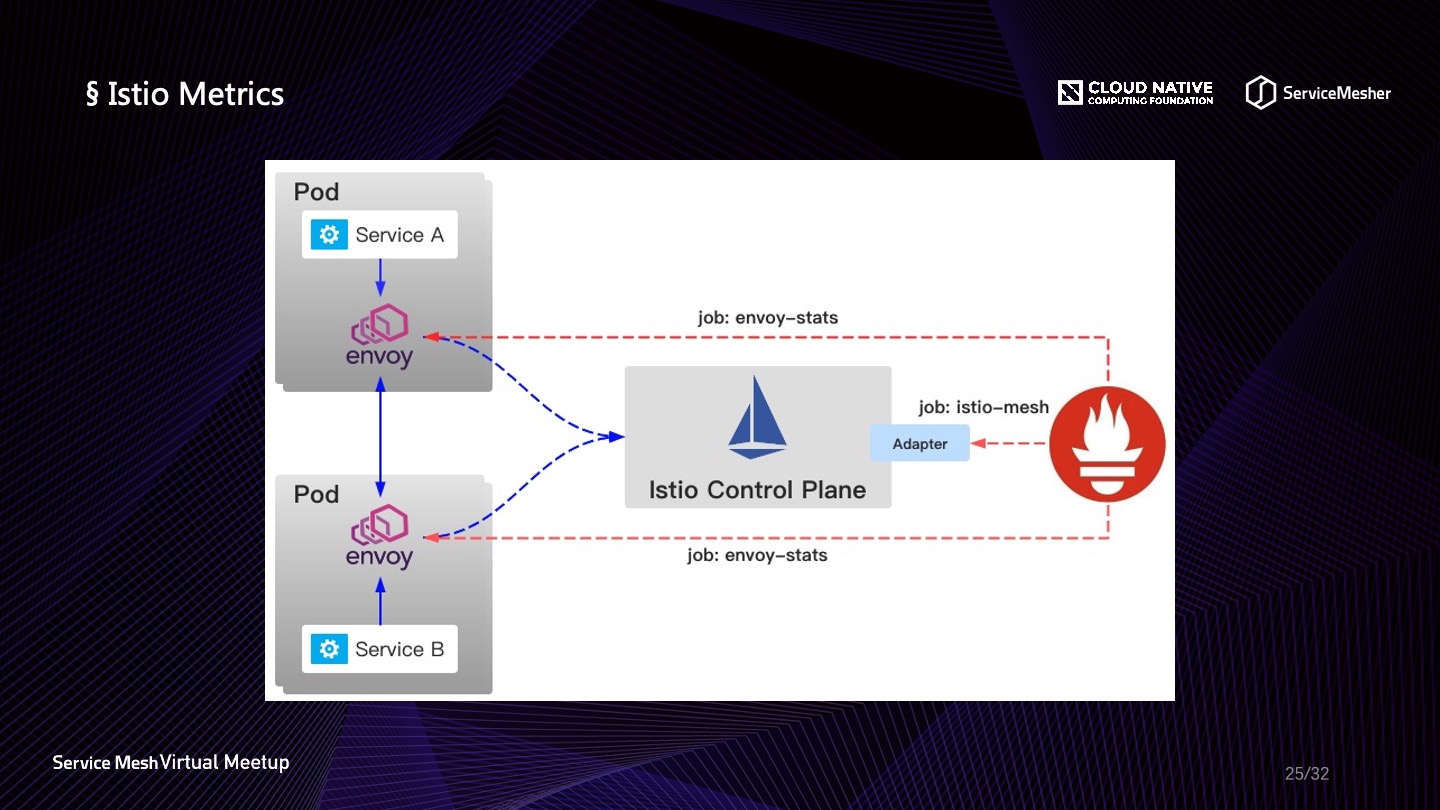
虽然在 1.5 版本当中 Mixer 已经基本被废弃掉,进入维护阶段直到 1.7 版本,默认情况下 Mixer 完全关闭,但是目前多数落地方案还是基于 1.0-1.4 这个版本区间,所以在没有整体升级的情况下,以及 WASM 性能不明朗的似乎还,始终还是离不开 Mixer 的。前面说到 Service Mesh 是云原生容器环境与可观察性之间的桥梁,Mixer 的 Adapter 可以算得上是这个桥梁的钢架主体了,并且具有良好的可扩展性。Mixer Adapter 除了为流量做 Check 之外,更重要的是在预检阶段和报告阶段收集遥测数据,遥测数据通过 Adapter 暴露或发射数据到各种观察端,观察端基于数据绘制丰富的流量轨迹与事件快照。常用的用于可观察性的 Adapter 有对各种商用方案的适配,比如 Datadog、New Relic 等,开源方案 Apache SKyWalking、Zipkin、Fluentd、Prometheus 等,相关内容会在下文展开。
数据平面比如 Envoy 会向 Mixer 上报日志信息(Log)、链路数据(Trace),监控指标(Metric)等数据,Envoy 上报的原始数据都是一些属性信息(Attributes),属性信息是名称和类型的元数据,用来描述入口和出口流量和流量产生时的环境信息,然后 Mixer 会依照 LogEntry、Metric 或者 TraceSpan 模板配置的格式对属性进行格式化,最后再交给 Mixer Adapter 做进一步处理,当然对于数据量庞大的 Log 信息和 Trace 信息可以选择直接上报处理端,Envoy 也原生支持一些特定组件。不同的 Adapter 需要不同的 Attributes,模板定义了 Attributes 到 Adapter 输入数据映射的 schema,一个 Adapter 可以支持多个模板。Mixer 当中又可以抽象出三种配置模型:
- Handler:表示一个配置好的 Adapter 实例;
- Instance:定义 Attributes 信息的映射规则;
- Rule:为 Handler 分配 Instance 以及触发规则;
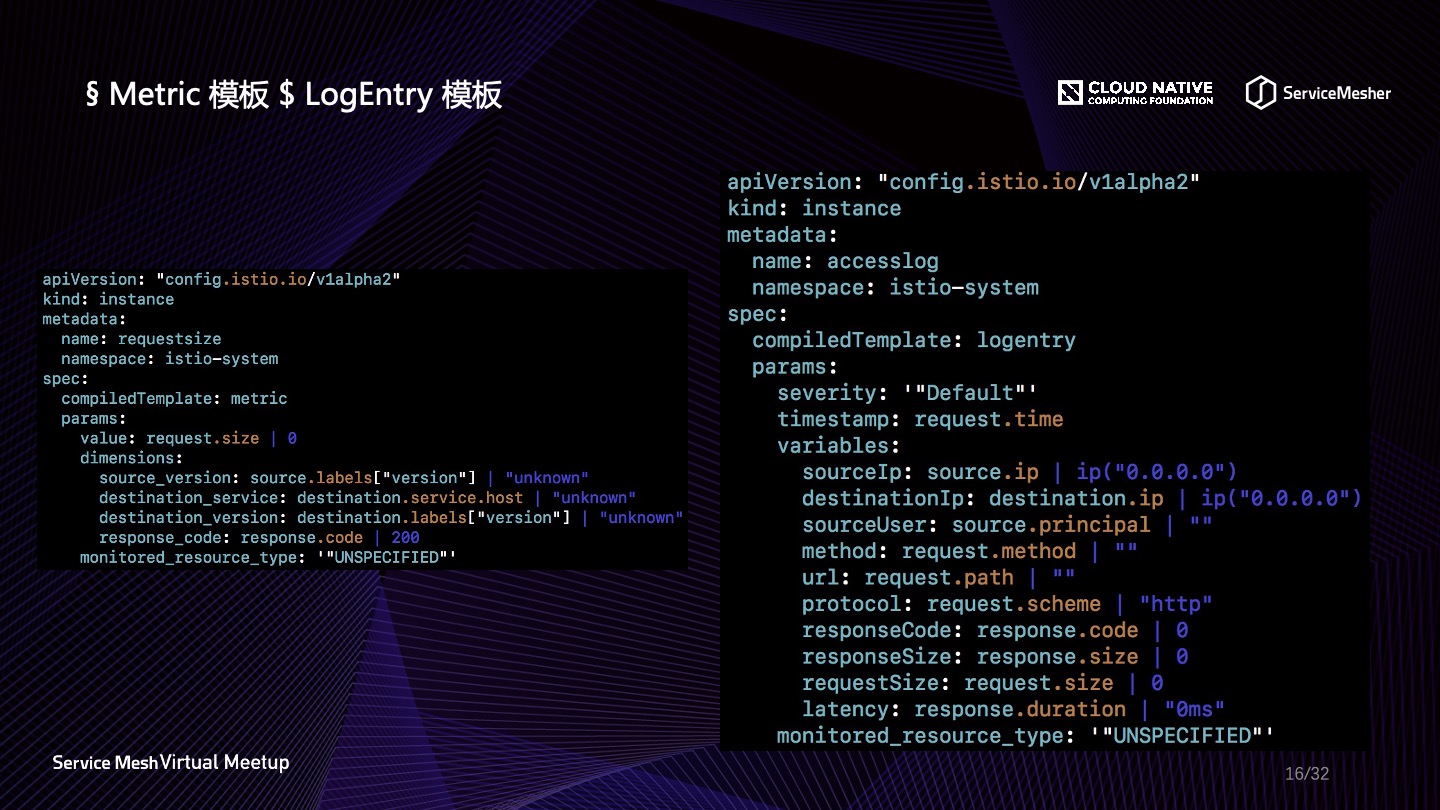
下图是 Metric 模板与 LogEntry 模板,在映射关系之上还可以设定默认值,更多的设定可以查看官方文档。
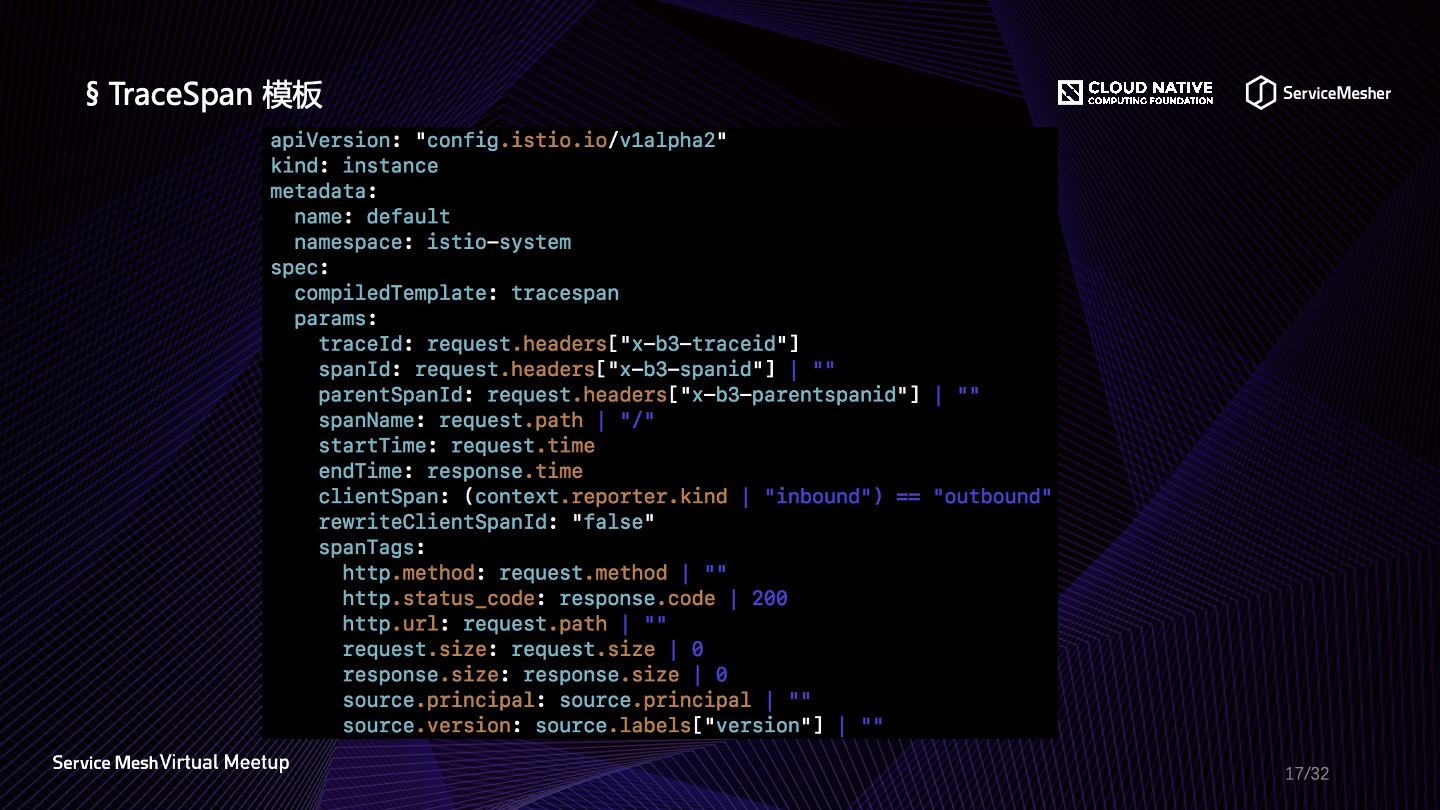
下图是 TraceSpan 模板,熟悉 OpenTracing 的同学可能对映射内容比较熟悉,很多信息都是 OpenTracing 协议的标准值,比如 Span 的各种描述信息以及 http.method、http.status_code 等等,感兴趣的同学也可以去看看 OpenTracing 的标准定义。 另外在Service Mesh中对于链路追踪普遍有一个问题,就是无论你在数据平面如何做流量劫持,如何透传信息,以及如何生成或者继承Span,入口流量和出口流量都有一个无法串联的问题,这个问题要解决还是需要服务主容器来埋点透传,将链路信息透传到下一次请求当中去,这个问题是无法避免的,而OpenTelemetry的后续推行,可以解决这方面的标准化问题。
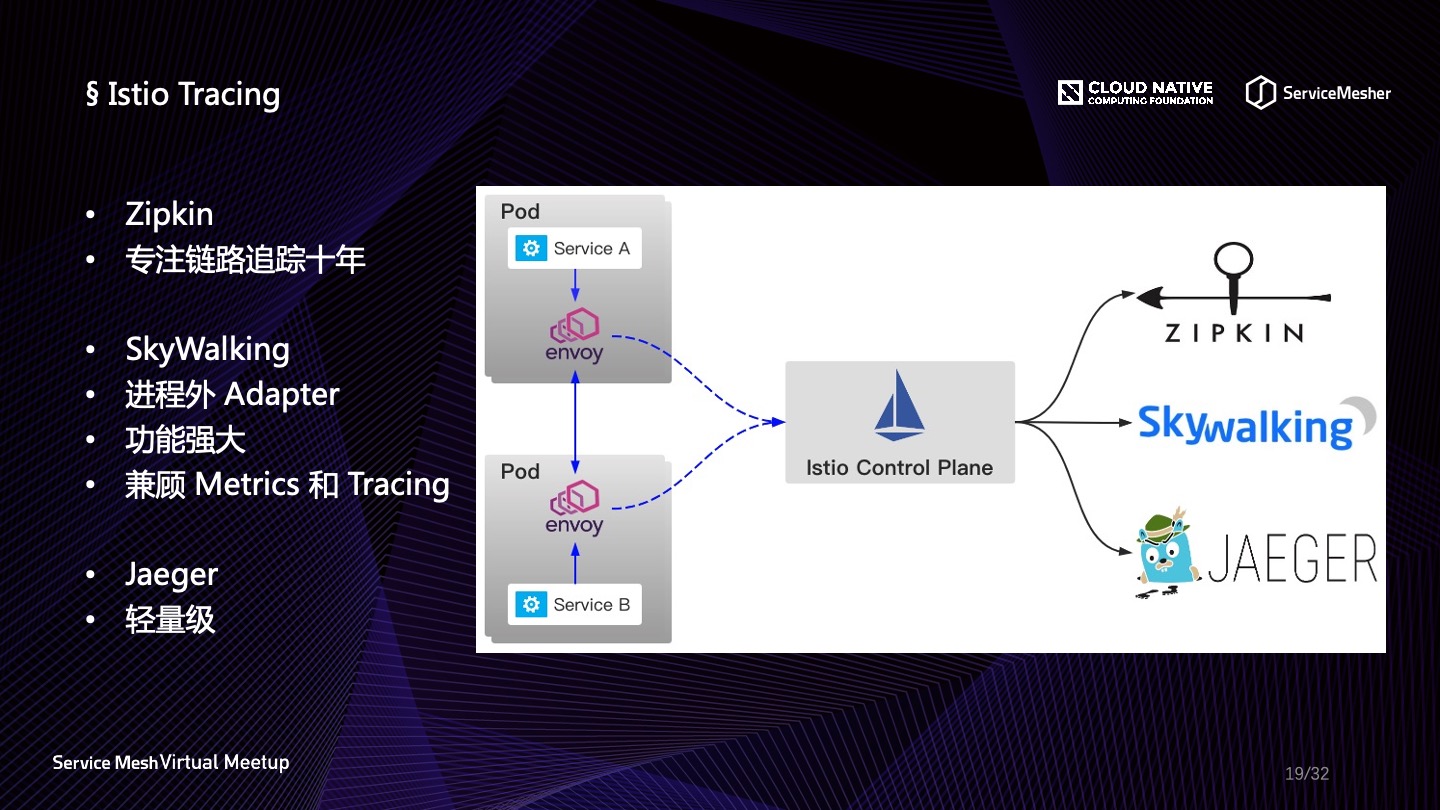
Istio 可观察性实践
在 Istio Mixer Adapter 当中我们可以获知,Istio 支持 Apache SKyWalking、Zipkin、Jaeger 的链路追踪,这三个中间件都支持 OpenTracing 协议,所以使用 TraceSpan 模板同时接入也没有什么问题。三者稍有不同的地方是:
- Zipkin 算是老牌的链路追踪中间件了,项目发起时间是2012年,新版的功能也比较好用;
- Jaeger 是2016年发起的新兴项目,使用 Go 编写,但是由于云原生的加持,致力于解决云原生时代的链路追踪问题,所以发展很快,它在 Istio 中集成极为简易,也是 Istio 官方推荐的方案
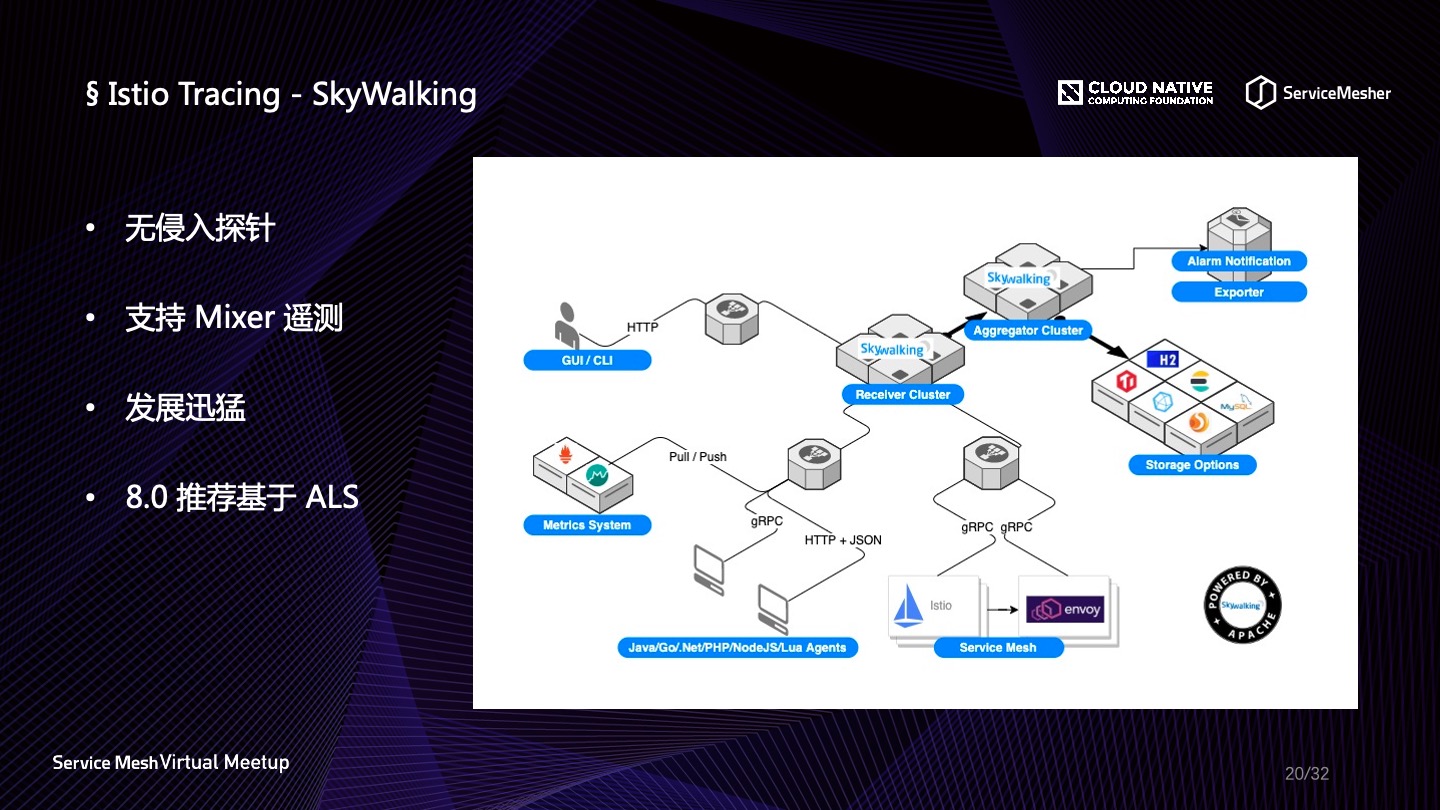
- SkyWalking 是2015年开始开源,目前正在蓬勃发展的一个项目,但是稍有不同的是,目前它与 Istio 的结合是通过进程外适配的方式,接入损耗稍微大一些,在最新的8.0版本(还未发布)当中有相应的解决方案;
说到这里要提一下 SkyWalking,它是由国人吴晟自主研发并开源的 APM 中间件了,可以说是国人的骄傲吧。本次的分享第二场由高洪涛老师,SkyWalking 的核心贡献者之一,也对 SkyWalking 做了题为《Apache SkyWalking 在 Service Mesh 中的可观察性应用》的分享,感兴趣的同学可以关注一下。
Skywalking 提供了 Java、.NET、NodeJS、PHP、Python 的无侵入式插桩 SDK,另外提供 Golang 和 Lua 的有侵入式 SDK。
为什么 Golang 不能做成无侵入式的?这还得从语言特性说起,通常编程语言分为编译型语言、解释型语言、中间型语言,像 Java 这种语言,在编译的时候是编译成字节码,然后运行时再通过 JVM 去运行字节码,这样就可以在这其中做很多的事情,可以在编译的过程中把原本的代码改掉。而像 Python、PHP、JS 和 Erlang,是使用的时候才会进行逐行翻译,所以也可以在用的时候去加入一些额外的代码。Golang、C、C++ 则是编译型语言,在编译与链接的时候已经将源码转换成了机器码,所以在运行的时候是很难去改动的,这也就是 Golang 为什么不能做自动探针的原因。另外 SkyWalking 是由国人发起的,所以用户群体基数非常大,迭代也非常地快,7.0版本以前支持基于 Mixer 的遥测与显示,8.0之后又加入了从 Prometheus 或 Spring Sleuth 当中收集数据,另外8.0之后支持 Envoy ALS(access log service),不过需要开启 ALS 接收器。
在 SkyWalking 的使用上,基本是使用 ES 来做存储,但是有一些改动,将 service、endpoint、instance 这些信息放到关系数据库,各个插桩 SDK 也加入到基础镜像,也可以基于 SkyWalking 轻松实现服务接口粒度的调用次数统计。
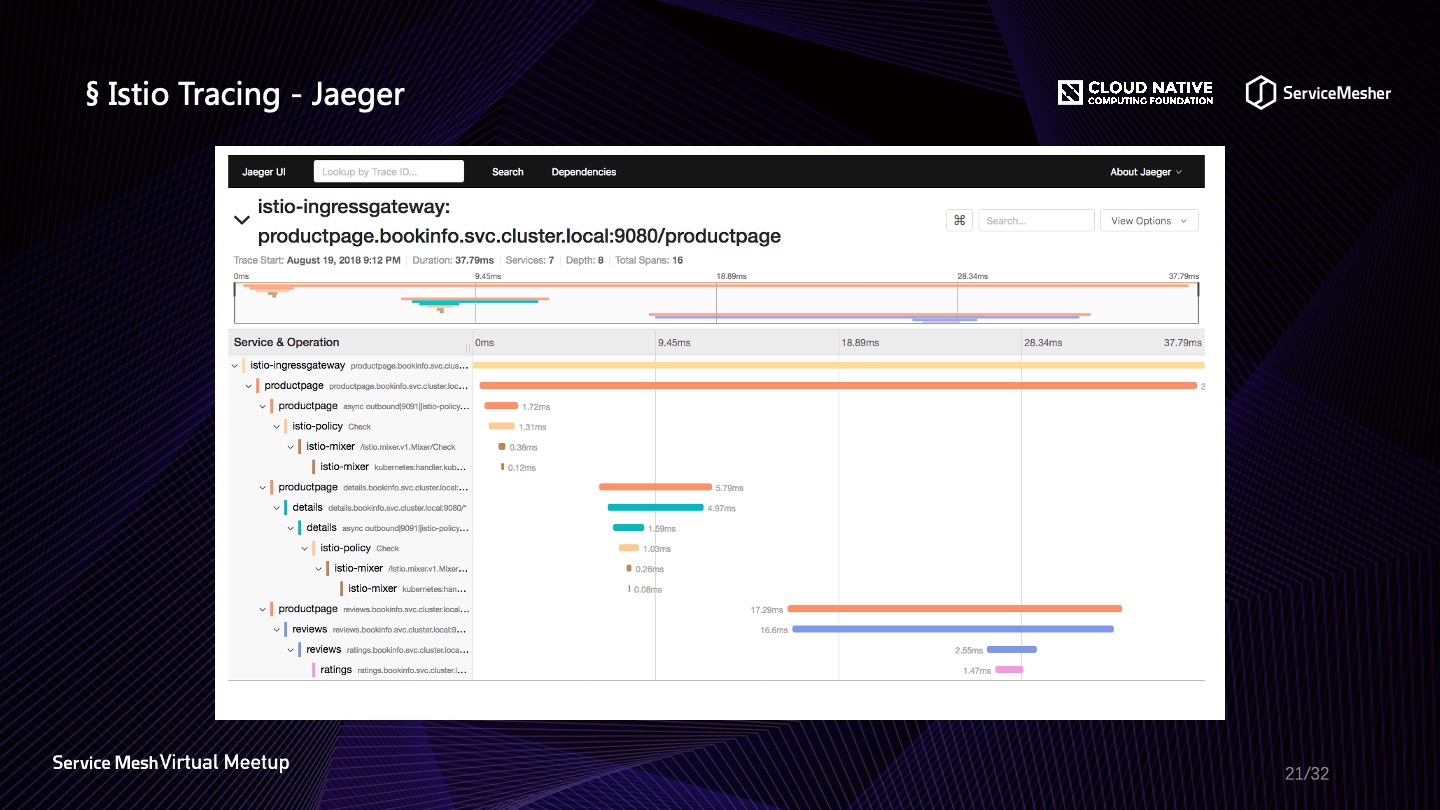
另外一个在云原生链路追踪领域收到广泛使用的是中间件是 Jaeger,它是由 Uber 开源,被 CNCF 接纳,目前已经是一个毕业项目。它原生支持 OpenTracing 协议,与市面上的其他中间件也具有互通性,支持多种后端存储以及具备灵活的扩展性。在 Envoy 中原生支持 Jaeger,当请求到达 Envoy 的时候,Envoy 会选择创建 Span 或继承 Span,以保证链路的连贯性,它支持 Zipkin 的 B3 系列 Header 透传,以及 Jaeger 与 LightStep 的 Header。下图是 Jaeger 当中对链路的展示,可以通过 TraceId 准确定位某一次请求。
传统的日志解决方案,ELK 可以说是家喻户晓的,从 Spring Cloud 盛行开始,它便是日志解决方案的优良选择。随着技术的发展,近几年又出现了 EFK 这种解决方案,存储组件 ElasticSearch 和界面 Kibana 倒是没有什么特别大的变化,但是在严苛的线上环境与容器环境中,以及各种对资源敏感的场景下,对于日志采集组件的要求也越来越高,目前比较流行的方案是使用 Fluentd 或者 Filebeat 替代 Logstash,下面是它们三者的一些介绍:
- Logstash:Java 编写,资源消耗大,现在一般不主张用作日志采集;
- Fluentd:主体由 C 编写,插件由 Ruby 编写,2019年4月从 CNCF 毕业,资源消耗非常小,通常占用内存在30MB左右,可以将日志发射到多个缓冲器,也就是多个接收端,目前在容器内比较常用的组件;
- Filebeat:Go 编写,但是线上出现过拉高底层资源 load average 的问题以及资源消耗较大,是 Fluentd 的10倍左右,在 Fluentd 出现之前,其被广泛运用在虚拟机当中;
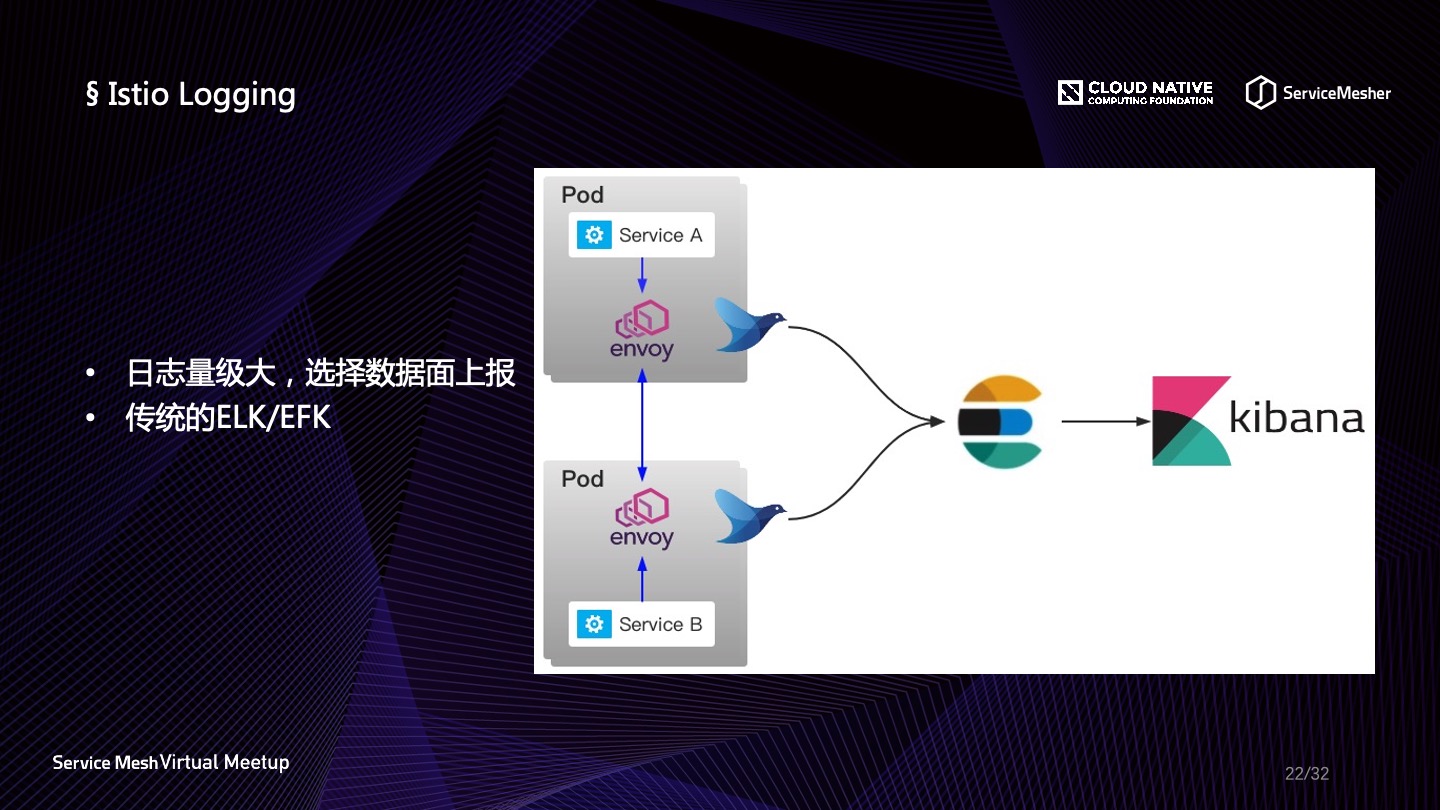
对于 Istio 中的日志解决方案,尽管 Mixer 当中有提供 Fluentd Adapter,但是日志的量级大家也知道,这种方式并不好,所以从 Envoy 去拿到原始的属性日志再进行加工发射到存储端对应用是比较友好的,可以节省出很大一部分资源。
在日志维度中,如果要定位问题,最好与请求绑定起来,而绑定请求与日志,需要一个特定的标识,可以是 TransactionId 或者是 TraceId,所以链路追踪与日志融合是一个势在必行的行业诉求,因此在选择链路追踪中间件的时候,一定要考虑到如何更好地获取 TraceId 并与日志结合起来。
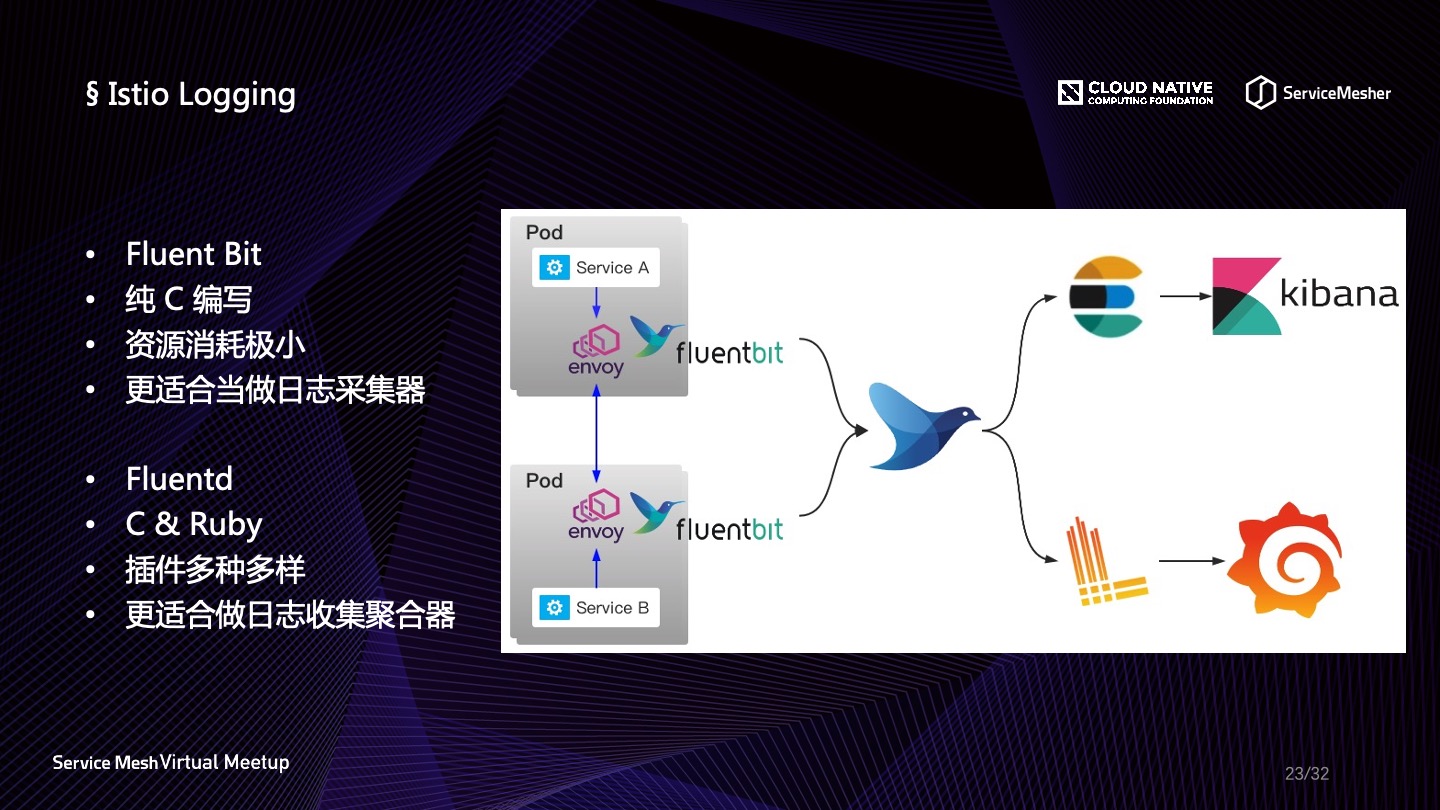
那么 Fluentd 就是最好的日志收集和发射解决方案了吗?
不是。Fluentd 的研发团队又推出了更加轻量级的 Fluent Bit,它是使用纯C编写的,占用资源更加少,从Fluentd 的 MB 级别直接降为 KB 级别,更加适合作为日志收集器。而 Fluentd 插件种类非常繁多,目前共有接近上千种的插件了,所以它更适合作为日志的聚合处理器,在日志收集之后的加工与传输中使用。在实际应用中,使用 Fluent Bit 可能会遇到一些问题,使用比较早期的版本可能会有配置动态加载的问题,解决方法就是另起一个进程控制 Fluent Bit 的启停,同时监听配置的变化,有变化则 reload。
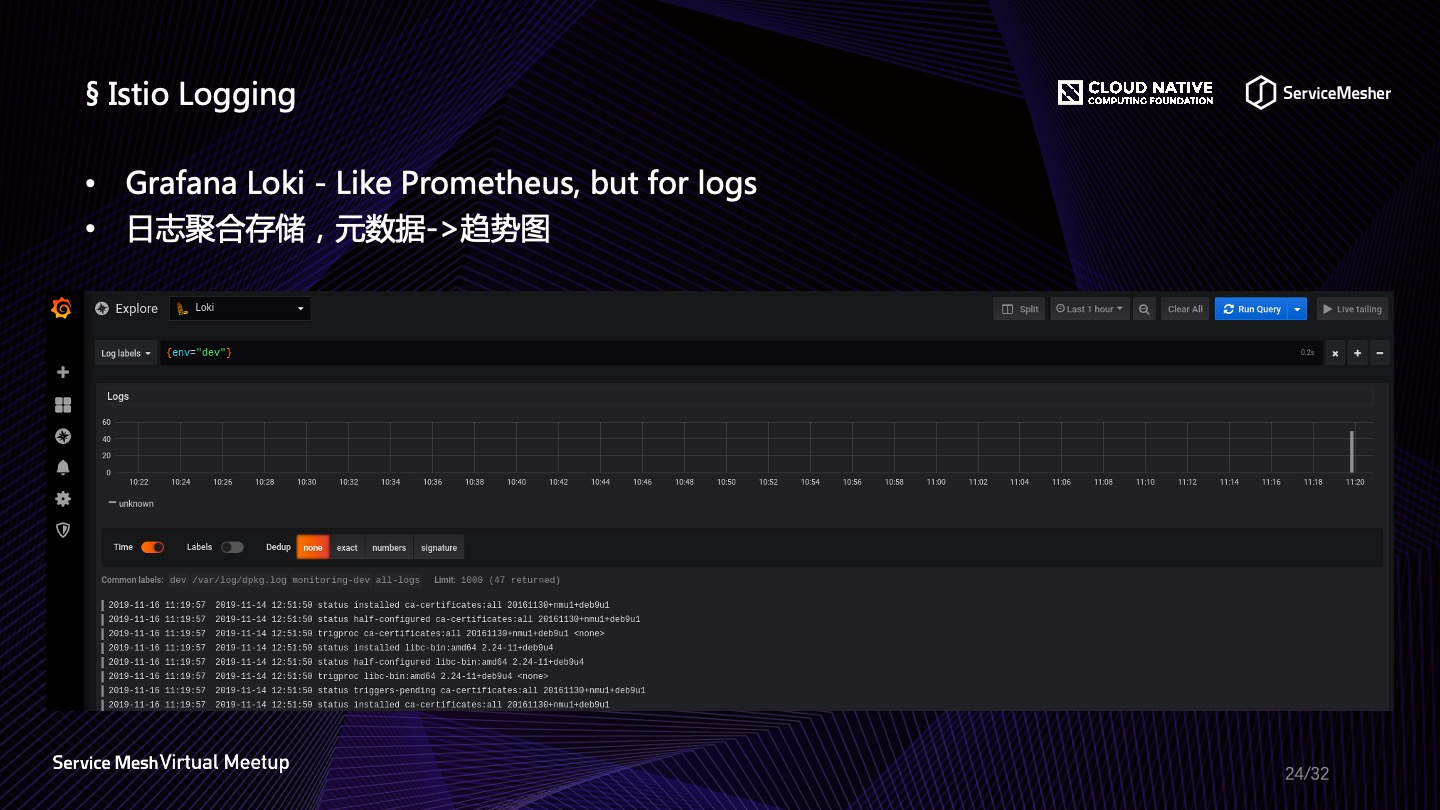
关于上图中的 Loki,它的核心思想正如项目介绍,“Like Prometheus, but for logs”,类似于 prometheus 的聚合日志解决方案,2018年12月开源,短短两年,却已有接近1万个 Star 了!它由 Grafana 团队开发,由此可以看出 Grafana 对于一统云原生可观察性的目的。
在云原生时代,像以前那样用昂贵的全文索引,如 ES,或者列式存储,如 HBase,将大量的原始日志直接存储到昂贵的存储介质之中的做法,似乎已经不太妥当。因为原始日志99%是不会被查询到的,所以日志也是需要做一些归并,归并之后压缩成 gzip,并且打上各式标签,这样可能会更加符合云原生时代精细化运作的原则。
而 Loki 可以将大量的日志存储于廉价的对象存储中,并且它为日志打标归并成日志流的这种方式得以让我们快速地检索到对应的日志条目。但是注意一点,想要使用 Loki 替代 EFK 是不明智的,它们针对的场景不一样,对数据的完整性保证和检索能力也有差别。
自从 Prometheus 出现以来,就牢牢占据着监控指标的主要地位。Prometheus 应该是当前应用最广的开源系统监控和报警平台了,随着以 Kubernetes 为核心的容器技术的发展,Prometheus 强大的多维度数据模型、高效的数据采集能力、灵活的查询语法,以及可扩展、方便集成的特点,尤其是和云原生生态的结合,使其获得了越来越广泛的应用。
Prometheus 于2015年正式发布,于2016年加入 CNCF,并于2018年成为第2个从 CNCF 毕业的项目(第一个是 Kubernetes,其影响力可见一斑)。目前 Envoy 支持 TCP 和 UDP statsd 协议,首先让 Envoy 推送指标到 statsd,然后可以使用 Prometheus 从 statsd 拉取指标,以供 Grafana 可视化展示。另外我们也可以提供 Mixer Adapter,接收处理遥测数据供 Prometheus 采集。
在 Prometheus 的实际使用当中可能会存在一些问题,比如 pod 被杀掉需要另外启一个,导致 Prometheus 数据丢失,这就需要一个 Prometheus 的数据可持久化的高可用方案。CNCF 的沙箱项目里面有一个项目叫做 Thanos,它的核心思想相当于是在 Prometheus 之上做了一个类似数据库 sharding 的方案,它有两种架构模式:Sidecar 与 Receiver。目前官方的架构图用的 Sidecar 方案,Receiver 是一个暂时还没有完全发布的组件,Sidecar 方案相对成熟一些,更加高效也更容易扩展。
Service Mesh 解决方案当中的 Linkerd 和 Conduit 都有可视化界面。Istio 相对来说比较黑盒,一直被诟病,不过 Istio 社区联合 Kiali,共同推出了一个可视化方案,提供如下功能:
- Topology:服务拓扑图;
- Health:可视化健康检查;
- Metrics:指标可视化;
- Tracing:分布式链路追踪可视化;
- Validations:配置校验;
- Wizards:路由配置;
- Configuration:CRD 资源的可视化与编辑;

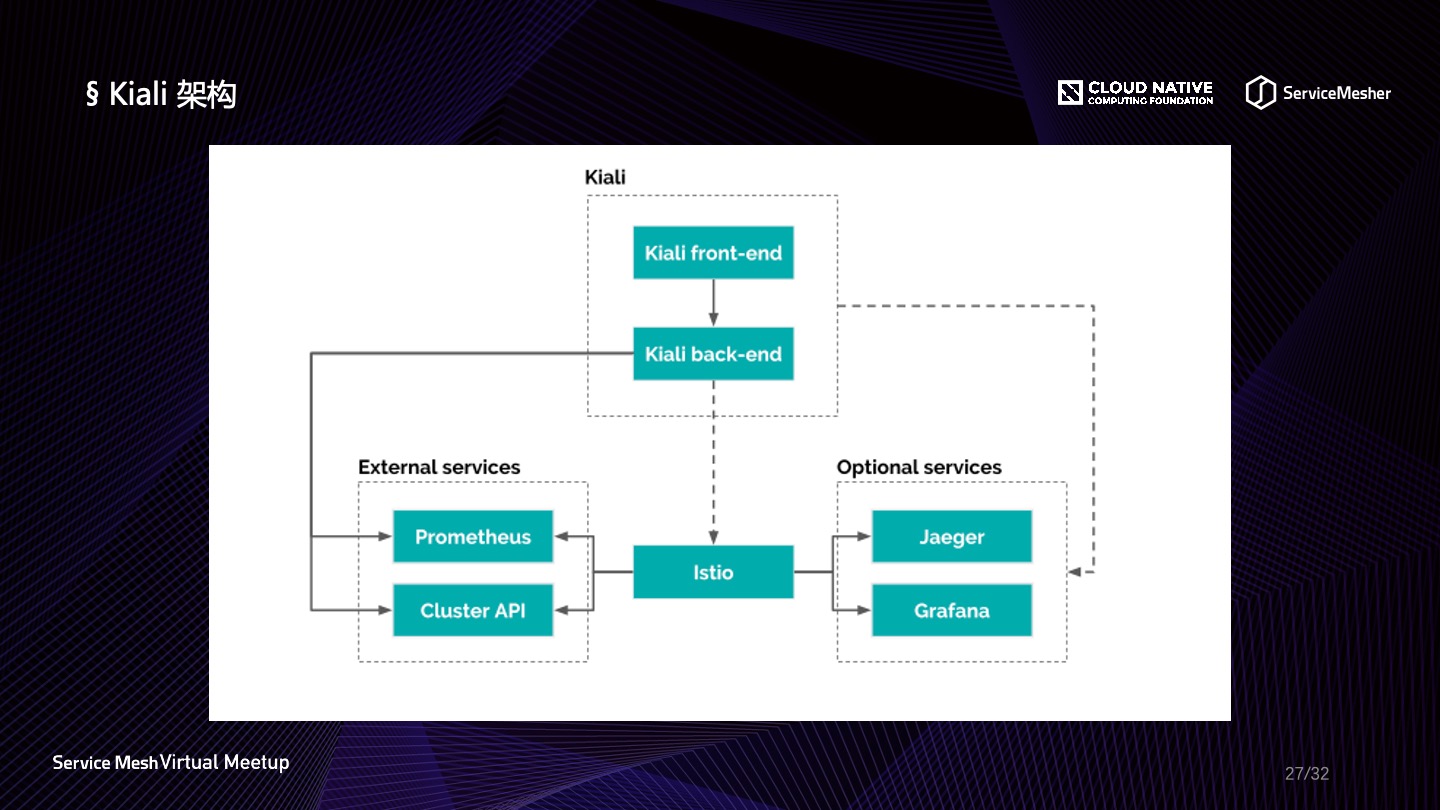
下面是 Kiali 的架构,可以比较清楚地看出,其本身是一个前后端分离的架构,并且可以从 Prometheus 或者集群特定 API 获取指标数据,另外也囊括了 Jaeger 链路追踪界面与 Grafana 展示界面,不过它们并非开箱即用,Kiali 依赖的三方组件需要单独部署。
总结
在许多的中小型公司内部,其实 Service Mesh 还是处于一个预研阶段,实际落地的时候需要考虑的因素繁多,如何才能获得较好的的投入产出效能比,是每一个做选型的人员都必须要经历的。其实不管落地情况,鉴于云原生的可观察性哲学来说,在落地的同时做好可观察性,可以同步解决很多问题,避免耗费过多的资源在无意义的事情上面,综合可观察性的三大支柱以及 Service Mesh 中对可观察性的支持来说,总结如下:
- Metrics:合理运用 Prometheus,并且做好持久化与高可用工作是关键;
- Tracing:选择合适的链路追踪中间件,关键在于集成契合度、整合 Logging、存储、展示来考量;
- Logging:什么场景使用原始日志,什么场景使用摘要日志,要明确;
嘉宾介绍
叶志远,G7 微服务架构师,Spring Cloud 中国社区联合创始人,ServiceMesher 社区成员,《重新定义 Spring Cloud 实战》作者,国内微服务领域早期实践者,云原生追随者。
回顾视频以及 PPT 下载地址
视频回顾:https://www.bilibili.com/video/BV13K4y1t7Co PPT 下载:https://github.com/servicemesher/meetup-slides/tree/master/2020/05/virtual











