
一、背景
在京东到家购物车系统中,用户基于门店能够对商品进行加车操作。用户与门店商品使用Redis的Hash类型存储,如下代码块所示。不知细心的你有没有发现,如果单门店加车商品过多,或者门店过多时,此Key就会越来越大,从而影响线上业务。
userPin:{
storeId:{门店下加车的所有商品基本信息},
storeId:{门店下加车的所有商品基本信息},
......
}
二、BigKey的界定和如何产生
2.1、BigKey的界定
BigKey称为大Key,通常以Key对应Value的存储大小,或者Key对应Value的数量来进行综合判断。对于大Key也没有严格的定义区分,针对String与非String结构,给出如下定义:
- String:String类型的 Key 对应的 Value 超过 10KB
- 非String结构(Hash,Set,ZSet,List):Value的数量达到10000个,或者Vaule的总大小为100KB
- 集群中Key的总数超过1亿
2.2、如何产生
1、数据结构设置不合理,例如集合中元素唯一时,应该使用Set替换List;
2、针对业务缺少预估性,没有预见Value动态增长;
3、Key没有设置过期时间,把缓存当成垃圾桶,一直再往里面扔,但是从不处理。
三、BigKey的危害
3.1、数据倾斜
redis数据倾斜分为数据访问倾斜和数据量倾斜,会导致该Key所在的数据分片节点CPU使用率、带宽使用率升高,从而影响该分片上所有Key的处理。
数据访问倾斜:某节点中key的QPS高于其他节点中的Key
数据量倾斜:某节点中key的大小高于其他节点中的Key,如下图,实例1中的Key1存储高于其他实例。

3.2、网络阻塞
Redis服务器是一个事件驱动程序,有文件事件和时间事件,文件事件和时间事件都是主线程完成。其中文件事件就是服务器对套接字操作的抽象,客户端与服务端的通信会产生相应的文件事件,服务器通过监听并处理这些事件来完成一系列网络通信操作。
Redis基于Reactor模式开发了自己的网络事件处理器,即文件事件处理器,该处理器内部使用I/O多路复用程序,可同时监听多个套接字,并根据套接字执行的任务来关联不同的事件处理器。文件事件处理器以单线程的方式运行,但是通过I/O多路复用程序来监听多个套接字,既实现了高性能网络通信模型,又保持了内部单线程设计的简单性。文件事件处理器构成如下图:
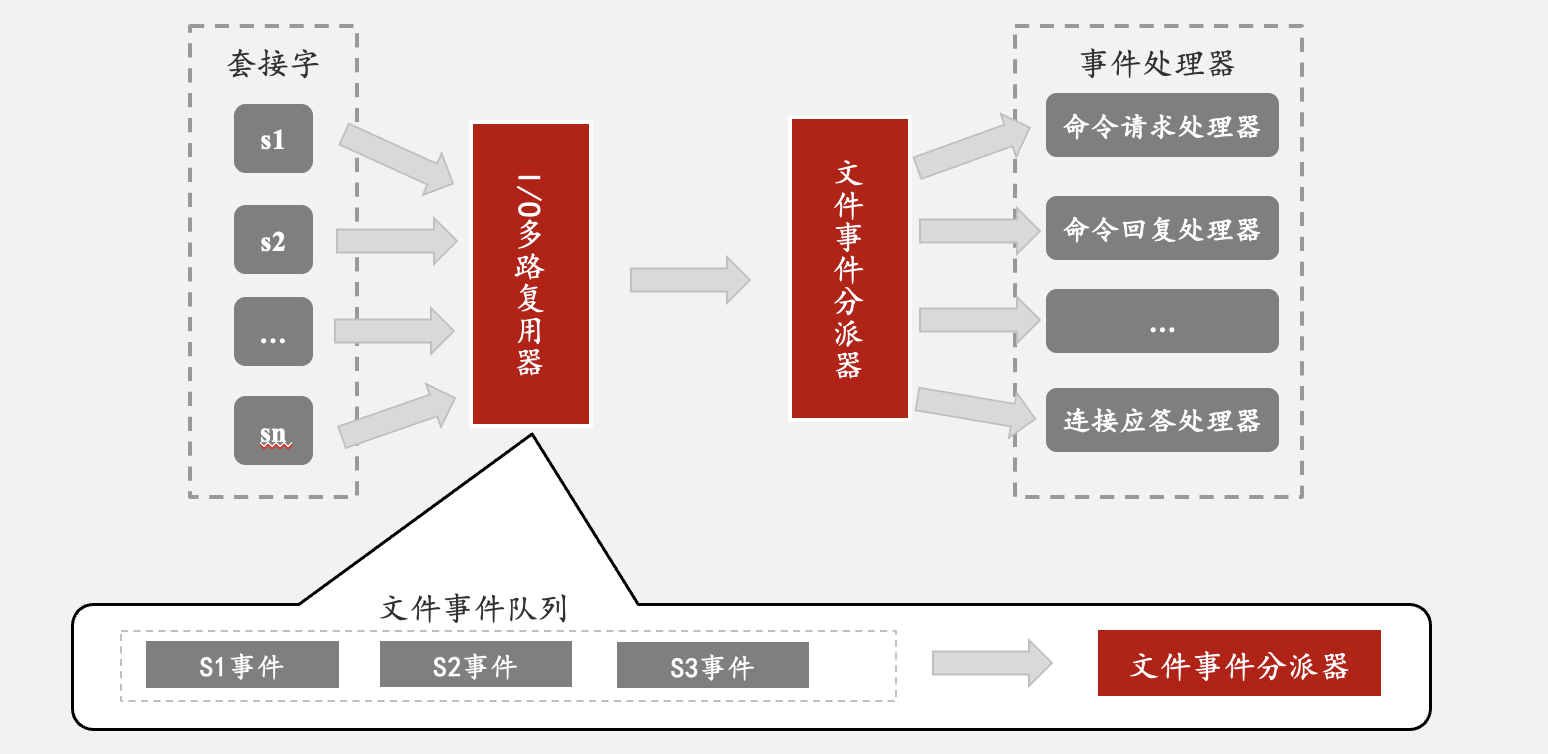
文件事件是对套接字操作的抽象,包括连接应答,写入,读取,关闭,因为一个服务器会连接多个套接字,所以文件事件可能并发出现,即使文件事件并发的出现,但是I/O多路复用程序会将套接字放入一个队列,通过队列有序的,同步的每次一个套接字的方式向文件事件分派器传送套接字,当让一个套接字产生的事件被处理完毕后,I/O多路复用程序才会继续向文件事件分派器传送下一个套接字,当有大key时,单次操作时间延长,导致网络阻塞。
3.3、慢查询
严重影响 QPS 、TP99 等指标,对大Key进行的慢操作会导致后续的命令被阻塞,从而导致一系列慢查询。
3.4、CPU压力
当单Key过大时,每一次访问此Key都可能会造成Redis阻塞,其他请求只能等待了。如果应用中设置了超时等,那么上层就会抛出异常信息。最后删除的时候也会造成redis阻塞,到时候内存中数据量过大,就会造成CPU负载过高。单个分片cpu占用率过高,其他分片无法拥有cpu资源,从而被影响。此外,大 key 对持久化也有些影响。fork 操作会拷贝父进程的页表项,如果过大,会占用更多页表,主线程阻塞拷贝需要一定的时间。
四、如何检测BigKey
4.1、redis-cli --bigkeys
首先我们从运行结果出发。首先通过脚本插入一些数据到redis中,然后执行redis-cli的--bigkeys选项
$ redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.01 to sleep 0.01 sec
# per SCAN command (not usually needed).
-------- 第一部分start -------
[00.00%] Biggest string found so far 'key-419' with 3 bytes
[05.14%] Biggest list found so far 'mylist' with 100004 items
[35.77%] Biggest string found so far 'counter:__rand_int__' with 6 bytes
[73.91%] Biggest hash found so far 'myobject' with 3 fields
-------- 第一部分end -------
-------- summary -------
-------- 第二部分start -------
Sampled 506 keys in the keyspace!
Total key length in bytes is 3452 (avg len 6.82)
Biggest string found 'counter:__rand_int__' has 6 bytes
Biggest list found 'mylist' has 100004 items
Biggest hash found 'myobject' has 3 fields
-------- 第二部分end -------
-------- 第三部分start -------
504 strings with 1403 bytes (99.60% of keys, avg size 2.78)
1 lists with 100004 items (00.20% of keys, avg size 100004.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
1 hashs with 3 fields (00.20% of keys, avg size 3.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
-------- 第三部分end -------
以下我们分三步对bigkeys选项源码原理进行解析,简要流程如下图:
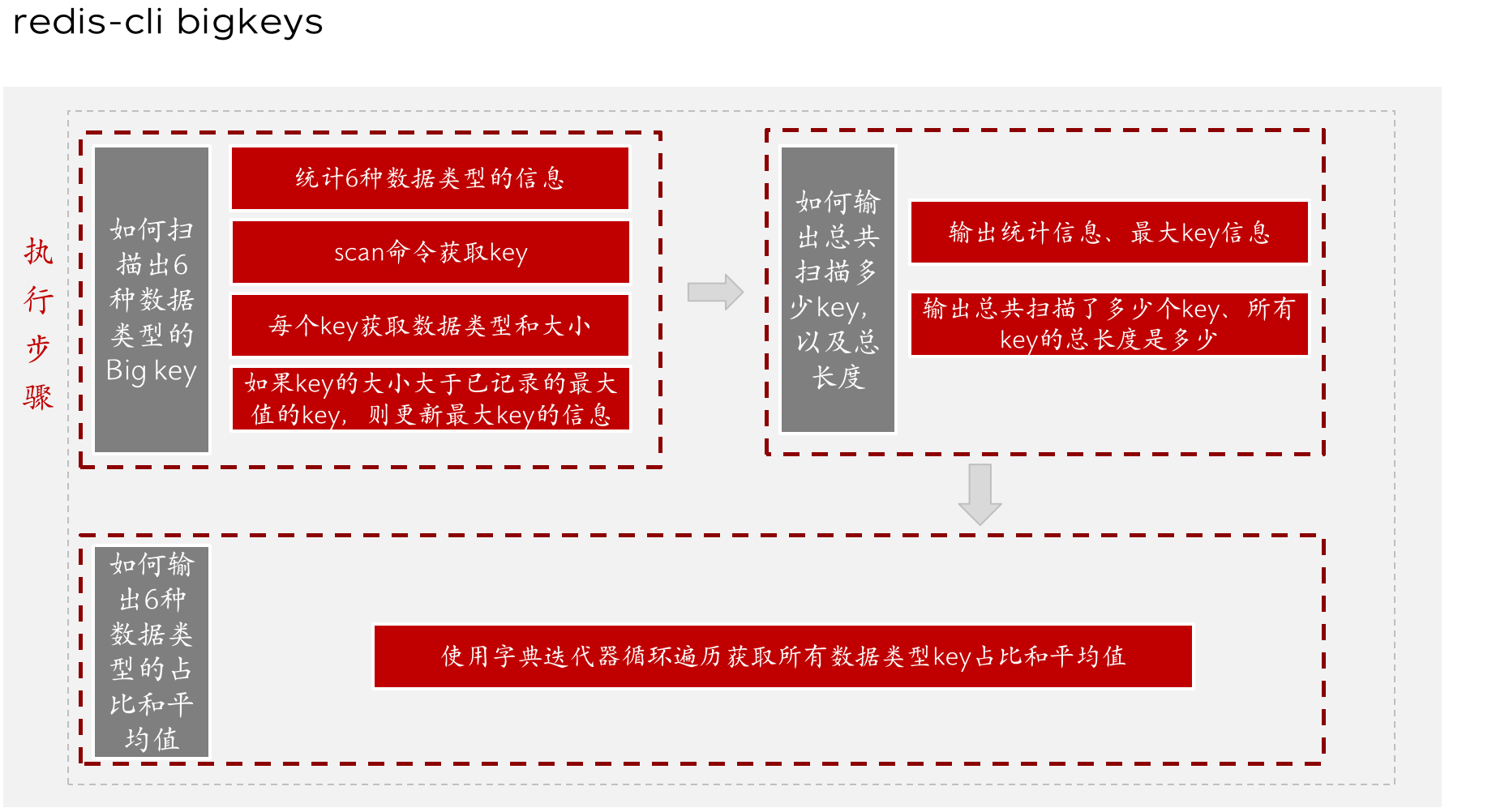
4.1.1、第一部分是如何进行找key的呢?
Redis找bigkey的函数是static void findBigKeys(int memkeys, unsigned memkeys_samples),因为--memkeys选项和--bigkeys选项是公用同一个函数,所以使用memkeys时会有额外两个参数memkeys、memkeys_sample,但这和--bigkeys选项没关系,所以不用理会。findBigKeys具体函数框架为:
1.申请6个变量用以统计6种数据类型的信息(每个变量记录该数据类型的key的总数量、bigkey是哪个等信息)
typedef struct {
char *name;//数据类型,如string
char *sizecmd;//查询大小命令,如string会调用STRLEN
char *sizeunit;//单位,string类型为bytes,而hash为field
unsigned long long biggest;//最大key信息域,此数据类型最大key的大小,如string类型是多少bytes,hash为多少field
unsigned long long count;//统计信息域,此数据类型的key的总数
unsigned long long totalsize;//统计信息域,此数据类型的key的总大小,如string类型是全部string总共多少bytes,hash为全部hash总共多少field
sds biggest_key;//最大key信息域,此数据类型最大key的键名,之所以在数据结构末尾是考虑字节对齐
} typeinfo;
dict *types_dict = dictCreate(&typeinfoDictType);
typeinfo_add(types_dict, "string", &type_string);
typeinfo_add(types_dict, "list", &type_list);
typeinfo_add(types_dict, "set", &type_set);
typeinfo_add(types_dict, "hash", &type_hash);
typeinfo_add(types_dict, "zset", &type_zset);
typeinfo_add(types_dict, "stream", &type_stream);
2.调用scan命令迭代地获取一批key(注意只是key的名称,类型和大小scan命令不返回)
/* scan循环扫描 */
do {
/* 计算完成的百分比情况 */
pct = 100 * (double)sampled/total_keys;//这里记录下扫描的进度
/* 获取一些键并指向键数组 */
reply = sendScan(&it);//这里发送SCAN命令,结果保存在reply中
keys = reply->element[1];//keys来保存这次scan获取的所有键名,注意只是键名,每个键的数据类型是不知道的。
......
} while(it != 0);
3.对每个key获取它的数据类型(type)和key的大小(size)
/* 检索类型,然后检索大小*/
getKeyTypes(types_dict, keys, types);
getKeySizes(keys, types, sizes, memkeys, memkeys_samples);
4.如果key的大小大于已记录的最大值的key,则更新最大key的信息
/* Now update our stats */
for(i=0;i<keys->elements;i++) {
......//前面已解析
//如果遍历到比记录值更大的key时
if(type->biggest<sizes[i]) {
/* Keep track of biggest key name for this type */
if (type->biggest_key)
sdsfree(type->biggest_key);
//更新最大key的键名
type->biggest_key = sdscatrepr(sdsempty(), keys->element[i]->str, keys->element[i]->len);
if(!type->biggest_key) {
fprintf(stderr, "Failed to allocate memory for key!\n");
exit(1);
}
//每当找到一个更大的key时则输出该key信息
printf(
"[%05.2f%%] Biggest %-6s found so far '%s' with %llu %s\n",
pct, type->name, type->biggest_key, sizes[i],
!memkeys? type->sizeunit: "bytes");
/* Keep track of the biggest size for this type */
//更新最大key的大小
type->biggest = sizes[i];
}
......//前面已解析
}
5.对每个key更新对应数据类型的统计信息
/* 现在更新统计数据 */
for(i=0;i<keys->elements;i++) {
typeinfo *type = types[i];
/* 跳过在SCAN和TYPE之间消失的键 */
if(!type)
continue;
//对每个key更新每种数据类型的统计信息
type->totalsize += sizes[i];//某数据类型(如string)的总大小增加
type->count++;//某数据类型的key数量增加
totlen += keys->element[i]->len;//totlen不针对某个具体数据类型,将所有key的键名的长度进行统计,注意只统计键名长度。
sampled++;//已经遍历的key数量
......//后续解析
/* 更新整体进度 */
if(sampled % 1000000 == 0) {
printf("[%05.2f%%] Sampled %llu keys so far\n", pct, sampled);
}
}
4.1.2、第二部分是如何执行的?
1.输出统计信息、最大key信息
/* We're done */
printf("\n-------- summary -------\n\n");
if (force_cancel_loop) printf("[%05.2f%%] ", pct);
printf("Sampled %llu keys in the keyspace!\n", sampled);
printf("Total key length in bytes is %llu (avg len %.2f)\n\n",
totlen, totlen ? (double)totlen/sampled : 0);
2.首先输出总共扫描了多少个key、所有key的总长度是多少。
/* Output the biggest keys we found, for types we did find */
di = dictGetIterator(types_dict);
while ((de = dictNext(di))) {
typeinfo *type = dictGetVal(de);
if(type->biggest_key) {
printf("Biggest %6s found '%s' has %llu %s\n", type->name, type->biggest_key,
type->biggest, !memkeys? type->sizeunit: "bytes");
}
}
dictReleaseIterator(di);
4.1.3、第三部分是如何执行的?
di为字典迭代器,用以遍历types_dict里面的所有dictEntry。de = dictNext(di)则可以获取下一个dictEntry,de是指向dictEntry的指针。又因为typeinfo结构体保存在dictEntry的v域中,所以用dictGetVal获取。然后就是输出typeinfo结构体里面保存的最大key相关的数据,包括最大key的键名和大小。
di = dictGetIterator(types_dict);
while ((de = dictNext(di))) {
typeinfo *type = dictGetVal(de);
printf("%llu %ss with %llu %s (%05.2f%% of keys, avg size %.2f)\n",
type->count, type->name, type->totalsize, !memkeys? type->sizeunit: "bytes",
sampled ? 100 * (double)type->count/sampled : 0,
type->count ? (double)type->totalsize/type->count : 0);
}
dictReleaseIterator(di);
4.2、使用开源工具发现大Key
在不影响线上服务的同时得到精确的分析报告。使用redis-rdb-tools工具以定制化方式找出大Key,该工具能够对Redis的RDB文件进行定制化的分析,但由于分析RDB文件为离线工作,因此对线上服务不会有任何影响,这是它的最大优点但同时也是它的最大缺点:离线分析代表着分析结果的较差时效性。对于一个较大的RDB文件,它的分析可能会持续很久很久。
redis-rdb-tools的项目地址为:https://github.com/sripathikrishnan/redis-rdb-tools
五、如何解决Bigkey
5.1、提前预防
- 设置过期时间,尽量过期时间分散,防止同一时间过期;
- 存储为String类型的JSON,可以删除不使用的Filed;
例如对象为{"userName":"京东到家","ciyt":"北京"},如果只需要用到userName属性,那就定义新对象,只具有userName属性,精简缓存中数据
- 存储为String类型的JSON,利用@JsonProperty注解让FiledName字符集缩小,代码例子如下。但是存在缓存数据识别性低的缺点;
import org.codehaus.jackson.annotate.JsonProperty;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.IOException;
public class JsonTest {
@JsonProperty("u")
private String userName;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public static void main(String[] args) throws IOException {
JsonTest output = new JsonTest();
output.setUserName("京东到家");
System.out.println(new ObjectMapper().writeValueAsString(output));
String json = "{\"u\":\"京东到家\"}";
JsonTest r1 = new ObjectMapper().readValue(json, JsonTest.class);
System.out.println(r1.getUserName());
}
}
{"u":"京东到家"}
京东到家
- 采用压缩算法,利用时间换空间,进行序列化与反序列化。同时也存在缓存数据识别性低的缺点;
- 在业务上进行干预,设置阈值。比如用户购物车的商品数量,或者领券的数量,不能无限的增大;
5.2、如何优雅删除BigKey
5.2.1、DEL
此命令在Redis不同版本中删除的机制并不相同,以下分别进行分析:
redis_version < 4.0 版本:在主线程中同步删除,删除大Key会阻塞主线程,见如下源码基于redis 3.0版本。那针对非String结构数据,可以先通过SCAN命令读取部分数据,然后逐步进行删除,避免一次性删除大key导致Redis阻塞。
// 从数据库中删除给定的键,键的值,以及键的过期时间。
// 删除成功返回 1,因为键不存在而导致删除失败时,返回 0
int dbDelete(redisDb *db, robj *key) {
// 删除键的过期时间
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
// 删除键值对
if (dictDelete(db->dict,key->ptr) == DICT_OK) {
// 如果开启了集群模式,那么从槽中删除给定的键
if (server.cluster_enabled) slotToKeyDel(key);
return 1;
} else {
// 键不存在
return 0;
}
}
4.0 版本 < redis_version < 6.0 版本:引入lazy-free,手动开启lazy-free时,有4个选项可以控制,分别对应不同场景下,是否开启异步释放内存机制:
- lazyfree-lazy-expire:key在过期删除时尝试异步释放内存
- lazyfree-lazy-eviction:内存达到maxmemory并设置了淘汰策略时尝试异步释放内存
- lazyfree-lazy-server-del:执行RENAME/MOVE等命令或需要覆盖一个key时,删除旧key尝试异步释放内存
- replica-lazy-flush:主从全量同步,从库清空数据库时异步释放内存
开启lazy-free后,Redis在释放一个key的内存时,首先会评估代价,如果释放内存的代价很小,那么就直接在主线程中操作了,没必要放到异步线程中执行
redis_version >= 6.0 版本:引入lazyfree-lazy-user-del,只要开启了,del直接可以异步删除key,不会阻塞主线程。具体是为什么呢,现在先卖个关子,在下面进行解析。
5.2.2、SCAN
SCAN命令可以帮助在不阻塞主线程的情况下逐步遍历大量的键,以及避免对数据库的阻塞。以下代码是利用scan来扫描集群中的Key。
public void scanRedis(String cursor,String endCursor) {
ReloadableJimClientFactory factory = new ReloadableJimClientFactory();
String jimUrl = "jim://xxx/546";
factory.setJimUrl(jimUrl);
Cluster client = factory.getClient();
ScanOptions.ScanOptionsBuilder scanOptions = ScanOptions.scanOptions();
scanOptions.count(100);
Boolean end = false;
int k = 0;
while (!end) {
KeyScanResult< String > result = client.scan(cursor, scanOptions.build());
for (String key :result.getResult()){
if (client.ttl(key) == -1){
logger.info("永久key为:{}" , key);
}
}
k++;
cursor = result.getCursor();
if (endCursor.equals(cursor)){
break;
}
}
}
5.2.3、UNLINK
Redis 4.0 提供了 lazy delete (unlink命令) ,下面基于源码(redis_version:7.2版本)分析下实现原理
- del与unlink命令底层都调用了delGenericCommand()方法;
void delCommand(client *c) {
delGenericCommand(c,server.lazyfree_lazy_user_del);
}
void unlinkCommand(client *c) {
delGenericCommand(c,1);
}
- lazyfree-lazy-user-del支持yes或者no。默认是no;
- 如果设置为yes,那么del命令就等价于unlink,也是异步删除,这也同时解释了之前咱们的问题,为什么设置了lazyfree-lazy-user-del后,del命令就为异步删除。
void delGenericCommand(client *c, int lazy) {
int numdel = 0, j;
// 遍历所有输入键
for (j = 1; j < c->argc; j++) {
// 先删除过期的键
expireIfNeeded(c->db,c->argv[j],0);
int deleted = lazy ? dbAsyncDelete(c->db,c->argv[j]) :
dbSyncDelete(c->db,c->argv[j]);
// 尝试删除键
if (deleted) {
// 删除键成功,发送通知
signalModifiedKey(c,c->db,c->argv[j]);
notifyKeyspaceEvent(NOTIFY_GENERIC,"del",c->argv[j],c->db->id);
server.dirty++;
// 成功删除才增加 deleted 计数器的值
numdel++;
}
}
// 返回被删除键的数量
addReplyLongLong(c,numdel);
}
下面分析异步删除dbAsyncDelete()与同步删除dbSyncDelete(),底层同时也是调用dbGenericDelete()方法
int dbSyncDelete(redisDb *db, robj *key) {
return dbGenericDelete(db, key, 0, DB_FLAG_KEY_DELETED);
}
int dbAsyncDelete(redisDb *db, robj *key) {
return dbGenericDelete(db, key, 1, DB_FLAG_KEY_DELETED);
}
int dbGenericDelete(redisDb *db, robj *key, int async, int flags) {
dictEntry **plink;
int table;
dictEntry *de = dictTwoPhaseUnlinkFind(db->dict,key->ptr,&plink,&table);
if (de) {
robj *val = dictGetVal(de);
/* RM_StringDMA may call dbUnshareStringValue which may free val, so we need to incr to retain val */
incrRefCount(val);
/* Tells the module that the key has been unlinked from the database. */
moduleNotifyKeyUnlink(key,val,db->id,flags);
/* We want to try to unblock any module clients or clients using a blocking XREADGROUP */
signalDeletedKeyAsReady(db,key,val->type);
// 在调用用freeObjAsync之前,我们应该先调用decrRefCount。否则,引用计数可能大于1,导致freeObjAsync无法正常工作。
decrRefCount(val);
// 如果是异步删除,则会调用 freeObjAsync 异步释放 value 占用的内存。同时,将 key 对应的 value 设置为 NULL。
if (async) {
/* Because of dbUnshareStringValue, the val in de may change. */
freeObjAsync(key, dictGetVal(de), db->id);
dictSetVal(db->dict, de, NULL);
}
// 如果是集群模式,还会更新对应 slot 的相关信息
if (server.cluster_enabled) slotToKeyDelEntry(de, db);
/* Deleting an entry from the expires dict will not free the sds of the key, because it is shared with the main dictionary. */
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
// 释放内存
dictTwoPhaseUnlinkFree(db->dict,de,plink,table);
return 1;
} else {
return 0;
}
}
如果为异步删除,调用freeObjAsync()方法,根据以下代码分析:
#define LAZYFREE_THRESHOLD 64
/* Free an object, if the object is huge enough, free it in async way. */
void freeObjAsync(robj *key, robj *obj, int dbid) {
size_t free_effort = lazyfreeGetFreeEffort(key,obj,dbid);
if (free_effort > LAZYFREE_THRESHOLD && obj->refcount == 1) {
atomicIncr(lazyfree_objects,1);
bioCreateLazyFreeJob(lazyfreeFreeObject,1,obj);
} else {
decrRefCount(obj);
}
}
size_t lazyfreeGetFreeEffort(robj *key, robj *obj, int dbid) {
if (obj->type == OBJ_LIST && obj->encoding == OBJ_ENCODING_QUICKLIST) {
quicklist *ql = obj->ptr;
return ql->len;
} else if (obj->type == OBJ_SET && obj->encoding == OBJ_ENCODING_HT) {
dict *ht = obj->ptr;
return dictSize(ht);
} else if (obj->type == OBJ_ZSET && obj->encoding == OBJ_ENCODING_SKIPLIST){
zset *zs = obj->ptr;
return zs->zsl->length;
} else if (obj->type == OBJ_HASH && obj->encoding == OBJ_ENCODING_HT) {
dict *ht = obj->ptr;
return dictSize(ht);
} else if (obj->type == OBJ_STREAM) {
...
return effort;
} else if (obj->type == OBJ_MODULE) {
size_t effort = moduleGetFreeEffort(key, obj, dbid);
/* If the module's free_effort returns 0, we will use asynchronous free
* memory by default. */
return effort == 0 ? ULONG_MAX : effort;
} else {
return 1; /* Everything else is a single allocation. */
}
}
分析后咱们可以得出如下结论:
- 当Hash/Set底层采用哈希表存储(非ziplist/int编码存储)时,并且元素数量超过64个
- 当ZSet底层采用跳表存储(非ziplist编码存储)时,并且元素数量超过64个
- 当List链表节点数量超过64个(注意,不是元素数量,而是链表节点的数量,List的实现是在每个节点包含了若干个元素的数据,这些元素采用ziplist存储)
- refcount == 1 就是在没有引用这个Key时
只有以上这些情况,在删除key释放内存时,才会真正放到异步线程中执行,其他情况一律还是在主线程操作。也就是说String(不管内存占用多大)、List(少量元素)、Set(int编码存储)、Hash/ZSet(ziplist编码存储)这些情况下的key在释放内存时,依旧在主线程中操作。
5.3、分而治之
采用经典算法“分治法”,将大而化小。针对String和集合类型的Key,可以采用如下方式:
- String类型的大Key:可以尝试将对象分拆成几个Key-Value, 使用MGET或者多个GET组成的pipeline获取值,分拆单次操作的压力,对于集群来说可以将操作压力平摊到多个分片上,降低对单个分片的影响。
- 集合类型的大Key,并且需要整存整取要在设计上严格禁止这种场景的出现,如无法拆分,有效的方法是将该大Key从JIMDB去除,单独放到其他存储介质上。
- 集合类型的大Key,每次只需操作部分元素:将集合类型中的元素分拆。以Hash类型为例,可以在客户端定义一个分拆Key的数量N,每次对HGET和HSET操作的field计算哈希值并取模N,确定该field落在哪个Key上。
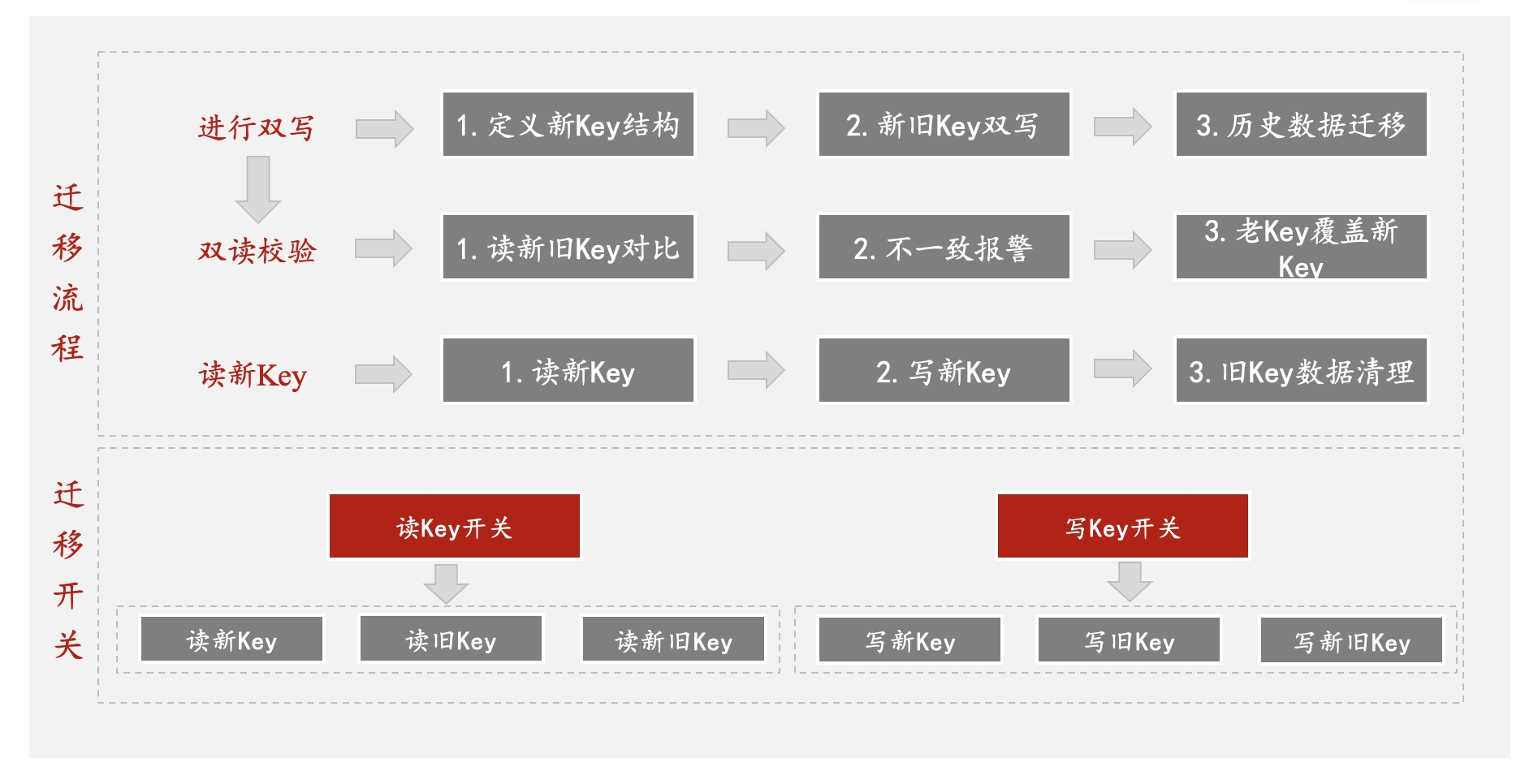
如果线上服务强依赖Redis,需要考虑到如何做到“无感”,并保证数据一致性。咱们基本上可以采用三步走策略,如下图所示。分别是进行双写,双读校验,最后读新Key。在此基础上可以设置开关,做到上线后的平稳迁移。
六、总结
综上所述,针对文章开头咱们购物车大Key问题,相信你已经有了答案。咱们可以限制门店数,限制门店中的商品数。如果不作限制,咱们也能进行拆分,将大Key分散存储。例如。将Redis中Key类型改为List,key为用户与门店唯一键,Value为用户在此门店下的商品。
存储结构拆分成两种:
第一种:
userPin:storeId的集合
第二种:
userPin_storeId1:{门店下加车的所有商品基本信息};
userPin_storeId2:{门店下加车的所有商品基本信息}
以上介绍了大key的产生、识别、处理,以及如何使用合理策略和技术来应对。在使用Redis过程中,防范大于治理,在治理过程中也要做到业务无感。
七、参考
https://github.com/redis/redis.git
https://github.com/huangz1990/redis-3.0-annotated.git
https://blog.csdn.net/ldw201510803006/article/details/124790121
https://blog.csdn.net/kuangd_1992/article/details/130451679
http://sd.jd.com/article/4930?shareId=119428&isHideShareButton=1
https://www.liujiajia.me/2023/3/28/redis-bigkeys
https://www.51cto.com/article/701990.html
https://help.aliyun.com/document_detail/353223.html
https://juejin.cn/post/7167015025154981895
https://www.jianshu.com/p/9e150d72ffc9
https://zhuanlan.zhihu.com/p/449648332
作者:京东零售 高凯
来源:京东云开发者社区 转载请注明来源









