
本文分享自天翼云开发者社区《Ceph PG状态介绍》,作者:wwwdl
一、基本概念 size:副本数(如三副本,size=3); min_size:支持可读写的最小副本数(如三副本,min_size=2); upset:pg的目标osd列表; actset:pg可接受读写osd列表。 如下为osd异常,重新选择osd,pg的osd列表变化过程:
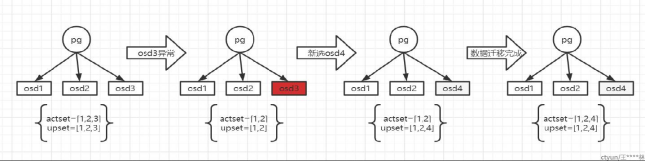
二、pg各个状态 (1)creating:创建pool时,自动创建pg,此时会出现该状态; (2)active:pg活跃态,表示pg可以接受读写业务,当pg状态不是active时,集群将业务异常,会导致上层业务大面积瘫痪; (3)clean:pg处于健康态,三个副本的数据是一致的; (4)recovering:pg增量恢复,根据日志条目,复原数据; (5)backfilling:pg全量恢复,根据全量扫描对象,比较差异,还原差异数据; (6)recovery-wait / backfill-wait:pg需要增量/全量恢复,当前等待状态,由于每个OSD并发恢复pg个数的限制(默认值为1); (7)recovery-toofull / backfill-toofull:OSD出现容量使用超过门限值95%,无法数据迁移; (8)scrubbing:扫描pg副本的元数据,副本之间进行比较,保证元数据一致,默认开启,一般一周扫描一次; (9)deep+scrubbing:扫描pg副本的元数据与数据,副本之间进行对比,保证元数据和数据一致,默认关闭,由于扫描数据相当耗时,影响业务; (10)inconsistent:扫描数据之后出现数据不一致,默认没有开启自动修复; (11)repair:数据不一致时,修复数据的状态,默认关闭,需要手动出发修复,修复的原理:将正常的OSD的数据推送给异常的OSD。 (12)peering:协商副本之间数据一致性; (13)degraded:降级态,peering完成后,检查到PG有对象需要修复; (14)remapped:upset 不等于 actset; (15)undersized:actset 小于副本数(size); (16)activating:peering完成之后,同步固化peering的结果(info、log); (17)peered:peering已经完成,当出现actset < min_size; (18)down:peering过程中检查到,当前在线的osd无法完成数据修复; (19)imcomplete:peering过程中,无法选取权威日志。 (20)stale:未刷新态,mon将osd标记为down,可能由于网络原因,osd没有感知mon把自己标记为down,osd主动上报pg的列表还包含自己,被mon发现,将被标记为stale; (21)snaptrim:删除快照; (22)snaptrim-wait:由于每个osd并发的限制,已经有pg在做删除快照,那么其他的pg必须等待; (23)snap-error:删除快照时,遇到异常情况, 如果出现snap-error,问题很严重,意味着丢失数据了。







