
######一.上文回顾
上回我们主要从图片的合并、压缩等方面介绍前端性能优化问题(详见Java Web 前端高性能优化(一))
本次我们主要从图像BASE64 编码、GZIP压缩、懒加载与预加载以及 OneAPM Browser Insight 的定位分析功能四个方面介绍前端优化方法
######二.图像的 BASE64 编码
不管如何,图片的下载始终都要向服务器发出请求,要是图片的下载不用向服务器发出请求,而可以随着 HTML 的下载同时下载到本地那就太好了。而目前,浏览器已经支持了该特性,我们可以将图片数据编码成 BASE64 的字符串,使用该字符串代替图像地址。
假设用 S代表这个 BASE64 字符串,那么就可以使用<img src="data:image/png;base64,S"> 来显示这个图像。可以看出,图像的数据包含在了 HTML 代码里,无需再次访问服务器。那么图像要如何编码成 BASE64 字符串呢?
可以使用 在线的工具---“Base64 Online”,这个工具可以上传图片将图片转换为 BASE64 字符串。当然,如果读者有兴趣,完全可以自己实现一个 BASE64 编码工具,比如使用 Java 开发,它的代码就如清单 1 所示。
清单 1. BASE64 的 Java 代码
public static String getPicBASE64(String picPath) { String content = null; try { FileInputStream fis = new FileInputStream(picPath); byte\[\] bytes = new byte\[fis.available()\]; fis.read(bytes); content = new sun.misc.BASE64Encoder().encode(bytes); // 具体的编码方法 fis.close(); } catch (Exception e) { e.printStackTrace(); } return content; }
本文编码了一个图像,并且将编码获得的 BASE64 字符串,写到了 HTML 之中,如下清单 2 所示。
清单 2. 嵌入 BASE64 的测试 HTML 代码
<html>
<body>
<img src="data:image/png;base64,
iVBORw0KGgoAAAANSUhEUgAAAeQAAAB8BAMAAABKwt5QAAAAA3NCSVQICAjb4U/gAAAAGFBMVEX/
……(省略了大部分编码)… BJRU5ErkJggg==">
</body>
</html>
由于图片数据包含在了 BASE64 字符串中,因此无需向服务器请求图像数据,结果显示如下图所示。
图 1. BASE64 显示图像

然而这种策略并不能滥用,它适用的情况是浏览器连接服务器的时间 > 图片下载时间,也就是发起连接的代价要大于图片下载,那么这个时候将图片编码为 BASE64 字符串,就可以避免连接的建立,提高效率。如果图片较大的话,使用 BASE64 编码虽然可以避免连接建立,但是相对于图像下载,请求的建立只占很小的比例,如果用 BASE64,对于动态网页来说图像缓存就会失效(静态网页可以缓存),而且 BASE64 字符串的总大小要大于纯图片的大小,这样一算就非常不合适了。
因此,如果你的页面已经静态化,图像又不是非常大,可以尝试 BASE64 编码,客户端会将网页内容和图片的 BASE64 编码一起缓存;而如果你的页面是动态页面,图像还较大,每次都要下载 BASE64 字符串,那么就不能用 BASE64 编码图像,而正常引用图像,从而使用到浏览器的图像缓存,提高下载速度。从现实我们接触的角度看,如一些在线 HTML 编辑器,里面的小图标,如笑脸等,都使用到了 BASE64 编码,因为它们非常小,数量多,BASE64 可以帮助网页减少图标的请求数,提高效率。
######三.Browser Insight 定位分析
作为一个网站的前端运维人员或者优化人员,大多数情况下并不一定要注重每一位用户的访问情况,只要大部分用户访问网站的时候处于一个满意的程度就可以了。
现在大多数前端性能优化工具往往注重的是某个时间段内的页面平均响应时间,这就造成可能因为某个用户偶然性的网络卡顿而延长整个时间段内的页面加载时间。
前一段时间发现 OneAPM 的Browser Insight 推出了定位分析功能,可以从响应时间分布来查看用户的整体响应分布,并可以针对不同时间分布内的用户确定影响其响应时间的因素。
图 2.Browser Insight 定位分析
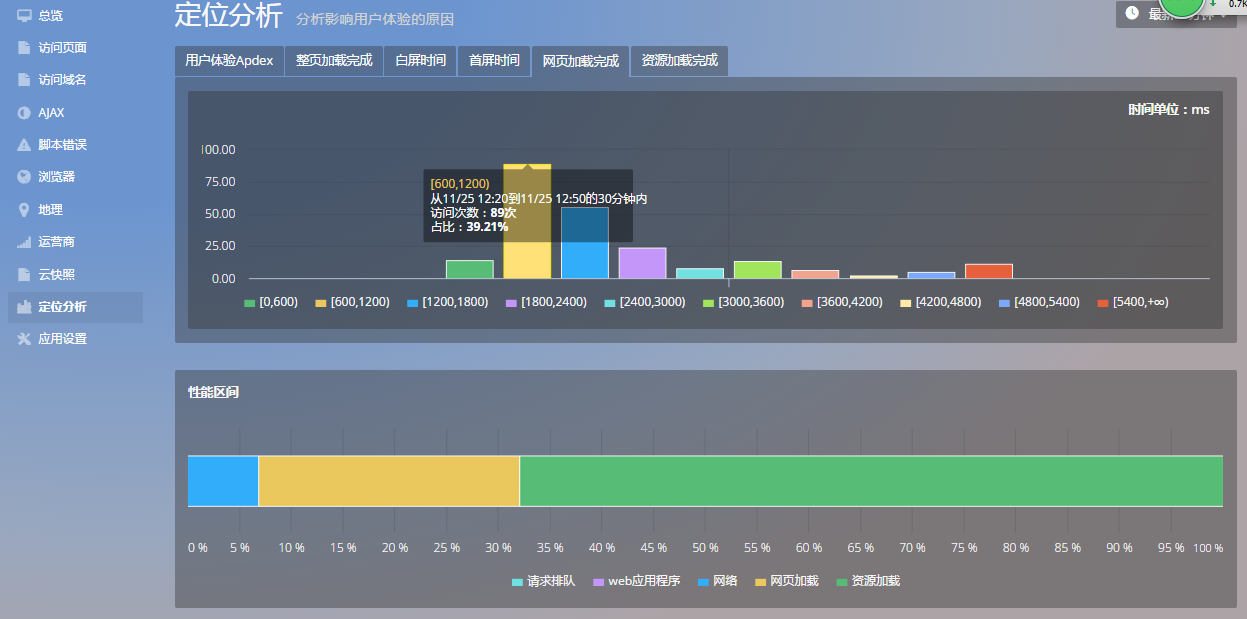
这个功能确实对于前段优化人员来说非常实用,并且它的维度还很丰富。
######四.GZIP 压缩
为了减少传输的数据,压缩是一个不错的选择,而 HTTP 协议支持 GZIP 的压缩格式,服务器响应的报头包含 Content-Encoding: gzip,它告诉浏览器,这个响应的返回数据,已经压缩成 GZIP 格式,浏览器获得数据后要进行解压缩操作。这在一定程度可以减少服务器传输的数据,提高系统性能。
那么如何给服务器响应添加 Content-Encoding: gzip 报头,同时压缩响应数据呢?
如果你用的是 Tomcat 服务器,打开 $tomcat_home$/conf/server.xml 文件,对 Connector 进行配置,配置如清单 3 所示。
清单 3. TOMCAT 配置清单
<Connector port ="80" maxHttpHeaderSize ="8192"
maxThreads ="150" minSpareThreads ="25" maxSpareThreads ="75"
enableLookups ="false" redirectPort ="8443" acceptCount ="100"
connectionTimeout ="20000" disableUploadTimeout ="true" URIEncoding ="utf-8"
compression="on"
compressionMinSize="2048"
noCompressionUserAgents="gozilla, traviata"
compressableMimeType="text/html,text/xml" />
我们为 Connector 添加了如下几个属性,他们意义分别是:
compression="on" 打开压缩功能
compressionMinSize="2048" 启用压缩的输出内容大小,这里面默认为 2KB
noCompressionUserAgents="gozilla, traviata" 对于以下的浏览器,不启用压缩
compressableMimeType="text/html,text/xml, image/png" 压缩类型
有时候,我们无法配置 server.xml,比如如果我们只是租用了别人的空间,但是它并没有启用GZIP,那么我们就要使用程序启用 GZIP 功能。我们将需要压缩的文件,放到指定的文件夹,使用一个过滤器,过滤对这个文件夹里文件的请求。
清单 4. 自定义 Filter 压缩 GZIP
// 监视对 gzipCategory 文件夹的请求 @WebFilter(urlPatterns = { "/gzipCategory/\*" }) public class GZIPFilter implements Filter { @Override public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { String parameter = request.getParameter("gzip"); // 判断是否包含了 Accept-Encoding 请求头部 HttpServletRequest s = (HttpServletRequest)request; String header = s.getHeader("Accept-Encoding"); //"1".equals(parameter) 只是为了控制,如果传入 gzip=1,才执行压缩,目的是测试用 if ("1".equals(parameter) && header != null && header.toLowerCase().contains("gzip")) { HttpServletResponse resp = (HttpServletResponse) response; final ByteArrayOutputStream buffer = new ByteArrayOutputStream(); HttpServletResponseWrapper hsrw = new HttpServletResponseWrapper( resp) { @Override public PrintWriter getWriter() throws IOException { return new PrintWriter(new OutputStreamWriter(buffer, getCharacterEncoding())); } @Override public ServletOutputStream getOutputStream() throws IOException { return new ServletOutputStream() { @Override public void write(int b) throws IOException { buffer.write(b); } }; } }; chain.doFilter(request, hsrw); byte\[\] gzipData = gzip(buffer.toByteArray()); resp.addHeader("Content-Encoding", "gzip"); resp.setContentLength(gzipData.length); ServletOutputStream output = response.getOutputStream(); output.write(gzipData); output.flush(); } else { chain.doFilter(request, response); } } // 用 GZIP 压缩字节数组 private byte\[\] gzip(byte\[\] data) { ByteArrayOutputStream byteOutput = new ByteArrayOutputStream(10240); GZIPOutputStream output = null; try { output = new GZIPOutputStream(byteOutput); output.write(data); } catch (IOException e) { } finally { try { output.close(); } catch (IOException e) { } } return byteOutput.toByteArray(); } …… }
该程序的主体思想是:在响应流写回之前,对响应的字节数据进行 GZIP 压缩。
因为并不是所有的浏览器都支持 GZIP 解压缩,如果浏览器支持 GZIP 解压缩,会在请求报头的 Accept-Encoding 里包含 gzip。这是告诉服务器浏览器支持 GZIP 解压缩,因此如果用程序控制压缩,为了保险起见,还需要判断浏览器是否发送 accept-encoding: gzip 报头,如果包含了该报头,才执行压缩。为了验证压缩前后的情况,使用 Firebug 监控请求和响应报头。
清单 5. 压缩前请求
GET /testProject/gzipCategory/test.html HTTP/1.1 Accept: \*/\* Accept-Language: zh-cn Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) Host: localhost:9090 Connection: Keep-Alive
清单 6. 不压缩的响应
HTTP/1.1 200 OK Server: Apache-Coyote/1.1 ETag: W/"5060-1242444154000" Last-Modified: Sat, 16 May 2009 03:22:34 GMT Content-Type: text/html Content-Length: 5060 Date: Mon, 18 May 2009 12:29:49 GMT
清单 7. 压缩后的响应
HTTP/1.1 200 OK Server: Apache-Coyote/1.1 ETag: W/"5060-1242444154000" Last-Modified: Sat, 16 May 2009 03:22:34 GMT Content-Encoding: gzip Content-Type: text/html Content-Length: 837 Date: Mon, 18 May 2009 12:27:33 GMT
可以看到,压缩后的数据比压缩前数据小了很多。压缩后的响应报头包含 Content-Encoding: gzip。
同时 Content-Length 包含了返回数据的大小。GZIP 压缩是一个重要的功能,前面提到的是对单一服务器的压缩优化,在高并发的情况,多个 Tomcat 服务器之前,需要采用反向代理的技术,提高并发度,而目前比较火的反向代理是 Nginx(这在后续的文章会进行详细的介绍)。
对 Nginx 的 HTTP 配置部分里增加如下配置。
清单 8. Nginx 的 GZIP 配置
gzip on; gzip\_min\_length 1000; gzip\_buffers 4 8k; gzip\_types text/plain application/x-javascript text/css text/html application/xml;
由于 Nginx 具有更高的性能,利用该配置可以更好的提高性能。在高性能服务器上该配置将非常有用。
######五.懒加载与预加载
预加载和懒加载,是一种改善用户体验的策略,它实际上并不能提高程序性能,但是却可以明显改善用户体验或减轻服务器压力。
预加载原理是在用户查看一张图片时,就将下一张图片先下载到本地,而当用户真正访问下一张图片时,由于本地缓存的原因,无需从服务器端下载,从而达到提高用户体验的目的。为了实现预加载,我们可以实现如下的一个函数。
清单 9. 预加载函数
function preload(callback) { var imageObj = new Image(); images = new Array(); images\[0\]="pre\_image1.jpg"; images\[1\]=" pre\_image2.jpg"; images\[2\]=" pre\_image3.jpg"; for(var i=0; i<=2; i++) { imageObj.src=images\[i\]; if (imageObj.complete) { // 如果图片已经存在于浏览器缓存,直接调用回调函数 callback.call(imageObj); } else { imageObj.onload = function () {// 图片下载完毕时异步调用 callback 函数 callback.call(imageObj);// 将回调函数的 this 替换为 Image 对象 }; } } } function callback() { alert(this.src + “已经加载完毕 , 可以在这里继续预加载下一组图片”); }
上面的代码,首先定义了 Image 对象,并且声明了需要预加载的图像数组,然后逐一的开始加载(.src=images[i])。如果已经在缓存里,则不做其他处理;如果不在缓存,监听 onload 事件,它会在图片加载完毕时调用。
而懒加载则是在用户需要的时候再加载。当一个网页中可能同时有上百张图片,而大部分情况下,用户只看其中的一部分,如果同时显示上百张,则浪费了大量带宽资源,因此可以当用户往下拉动滚动条时,才去请求下载被查看的图像,这个原理与 word 的显示策略非常类似。
在 JavaScript 中,它的基本原理是首先要有一个容器对象,容器里面是 img 元素集合。用隐藏或替换等方法,停止 img 的加载,也就是停止它去下载图像。然后历遍 img 元素,当元素在加载范围内,再进行加载(也就是显示或插入 img 标签)。
加载范围一般是容器的视框范围,即浏览者的视觉范围内。当容器滚动或大小改变时,再重新历遍元素判断。如此重复,直到所有元素都加载后就完成。当然对于开发来讲,选择已有的成熟组件,并不失为一个上策,Lazy Load Plugin for jQuery 是基于 JQuery 的懒加载组件,它有自己的官方网站。
这是一个不错的免费插件。可以帮助程序员快速的开发懒加载应用。
######小结
Java Web 前端高性能优化(一)、(二)总结了前端性能问题定位以及图片优化的几种方式,将它们归结起来,在读者需要的时候,可以查看本文的内容,相信按照本文的方法,可以辅助读者进行前端性能优化。
注:本文转载自 IBM 社区,由 OneAPM 产品运营编辑整理,原文链接为: http://www.ibm.com/developerworks/cn/java/j-lo-javawebhiperf1/#icomments











