阅读更多
问题:明明order by的字段建立了索引,结果还是Using FileSort?
Using filesort表示在索引之外,需要额外进行外部的排序动作。导致该问题的原因一般和order by有者直接关系,一般可以通过合适的索引来减少或者避免。
explain SELECT * FROM table_item WHERE user_id = 2 ORDER BY item_id LIMIT 0, 5
user_id 和 item_id 分别建立一个索引,对此语句MySQL选择了 user_id索引,那么 item_id 的索引没有起到任何用处。当排序时记录数较多,内存中的排序 buffer满了,只能 Using filesort 进行外部排序。
解决方式为对这两列建立组合索引。
explain SELECT * FROM table_item WHERE user_id = 2 and user_age > 20 ORDER BY item_id LIMIT 0, 5
建立组合索引(user_id, user_age, item_id),看似非常完美。但由于user_age规则不是确定值,使用该组合索引的话实际上需要先按索引找出一个个user_age下的东西后再对其进行排序,仍然会filesort。
解决方式是使用组合索引(user_id, item_id),对排序好的item_id再过滤到不满足user_age > 20的条目,不会出现filesort。
explain SELECT * FROM table_item WHERE user_id = 2 ORDER BY item_attr desc, item_id LIMIT 0, 5
建立了组合索引(user_id, item_attr, item_id),因为item_attr是降序而item_id是升序,从而仍然需要外部排序。
如果item_attr和item_id都是升序或者都是降序,则不会出现filesort;建立组合索引(user_id, item_attr desc, item_id)现象依旧。
Mysql5.1 在线文档“13.1.4. CREATE INDEX语法”中提到:“一个index_col_name规约可以以ASC或DESC为结尾。这些关键词将来可以扩展,用于指定递增或递减索引值存 储。目前,这些关键词被分析,但是被忽略;索引值均以递增顺序存储。”
可以看出无法通过修改索引来避免这个filesort,只能是如果可能的话修改查询的排序条件。
总结:主要的是,oder by 的字段要与where条件中的字段一致(也可以是联合索引)。
下面是我的实践:
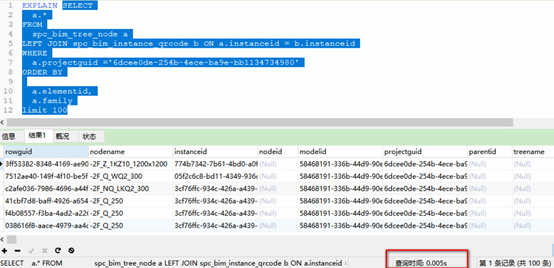
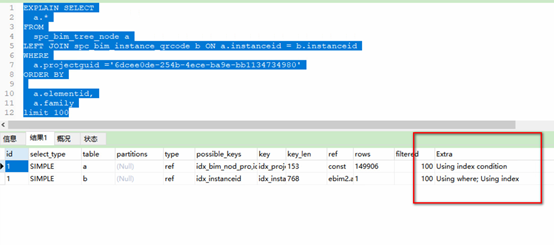
建立联合索引前:
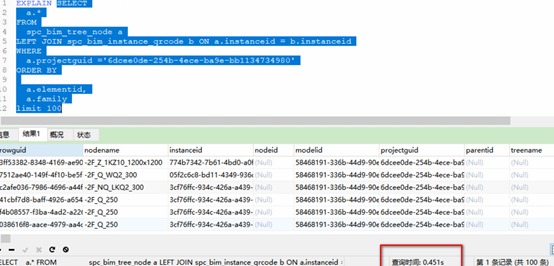
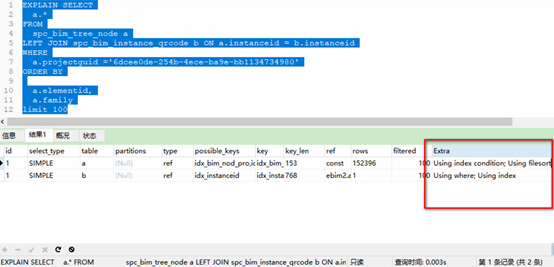
建立联合索引后: