
Dubbo在众多的微服务框架中脱颖而出,占据RPC服务框架的半壁江山,非常具有普适性,熟练掌握 Dubbo的应用技巧后深刻理解其内部实现原理,让大家能更好的掌控工作,助力职场,特别能让大家在面试中脱颖而出。
那Dubbo内部的设计理念,实现原理是什么呢?
本文将结合官方提供的3张图,从如下三个方面介绍其内部的核心实现、以及如何指导实践。
1、服务注册与发现机制
Dubbo的服务注册与发现机制如下图所示:
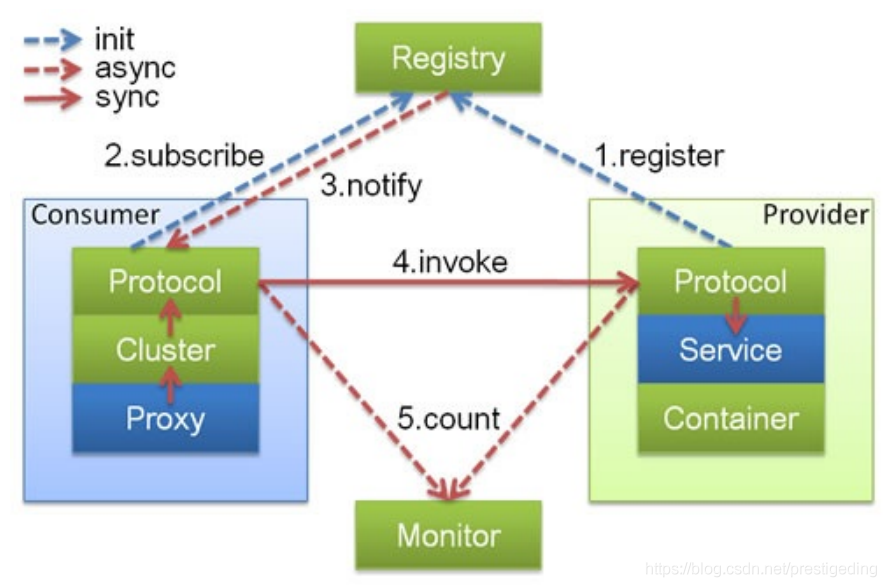
在Dubbo中存在4类角色:
- Registry 注册中心。
- Consumer 服务调用者、消费端。
- Provider 服务提供者。
- Monitor 监控中心。
具体的交互流程包括如下关键步骤:
- 服务提供者在启动的时候向注册中心进行注册。
- 消息消费者在启动的时候向注册中心订阅指定服务,注册中心将以某种机制(推或拉)模式告知消费端服务提供者列表。
- 当服务提供者数量变化(服务提供者扩容、缩容、宕机等因素),注册中心需要以某种方式(推或拉)告知消费端,以便消费端进行正常的负载均衡。
- 服务提供者、服务消费者向监控中心汇报TPS等调用数据,以便监控中心进行可视化展示等。
Dubbo官方提供了多种注册中心,接下来将以使用最为普遍的Zookeeper进一步介绍注册中心的原理。
首先我们来看一下Zookeeper注册中心中的数据存储目录结构,从目录结构来窥探其实现机制。 
Dubbo Zookeeper注册中心,其目录组织结构为 /dubbo/{ServiceName},再每一个服务名称下会有4个目录:
- providers 服务提供者列表。
- consumers 消费者列表
- routers 路由规则列表,关于一个服务可以设置多个路由规则。
- configurators 动态配置条目。在Dubbo中可以在不重启消费者、服务提供者的前提下动态修改服务提供者、服务消费者的配置,例如修改线程的数量,超时时间等参数。
基于Zookeeper注册中心的实现细节如下:
- 服务提供者启动时会向注册中心注册,主要是在对应服务的providers目录下增加一条记录(临时节点),同时监听 configurators节点。
- 服务消费者启动时会向注册中心订阅,主要是在对应服务的consumers目录下增加一条记录(临时节点),同时监听 configurators、routers 目录。
- 由于当有新的服务提供者上线后 providers 目录会增加一条记录,消费者能立马收到一个服务提供者列表变化的通知,得以将最新的服务提供者列表推送给服务调用方(消费端);如果一个服务提供者宕机,由于创建的节点是临时节点,Zookeeper会将该节点移除,同样会触发事件,消费端得知最新的服务提供者列表,从而实现路由的动态注册与发现。
- 当Dubbo新版本上线后,如果需要进行灰度发布,可以通过dubbo-admin等管理平台添加路由规则,最终会写入到指定服务的router节点(持久节点),服务调用方会监听该节点的变化,从而感知最新的路由规则,将其用于服务提供者的筛选,从而实现灰度发布等功能。
- configurators 节点的运作机制与 router 节点一样,就不重复介绍。
扩展思考:
1、如果注册中心全部宕机,对整个服务体系会有什么影响?
如果整个注册中心全部宕机,整个服务调用能正常工作,不会影响现有的服务消费者调用,但消费端无法发现新注册的服务提供者。
2、如果注册中心内存溢出或频繁发生 Full Gc,对整个集群又会带来什么影响呢?
如果频繁发生Full GC,并且如果Full GC的时间超过了Zookeeper会话的过期时间,将会造成非常严重的影响,会触发所有临时节点被删除,消费端将无法感知服务提供者的存在,影响服务调用,将大面积抛出 No provider 等错误。正所谓成也临时节点、败也临时节点。
为了避免Full Gc带来的严重后果,用于Dubbo注册中心的Zookeeper,一定会要独享,并及时做好内存、CPU等的监控与告警。
2、服务调用
Dubbo的服务调用设计十分优雅,其实现原理如下图所示: 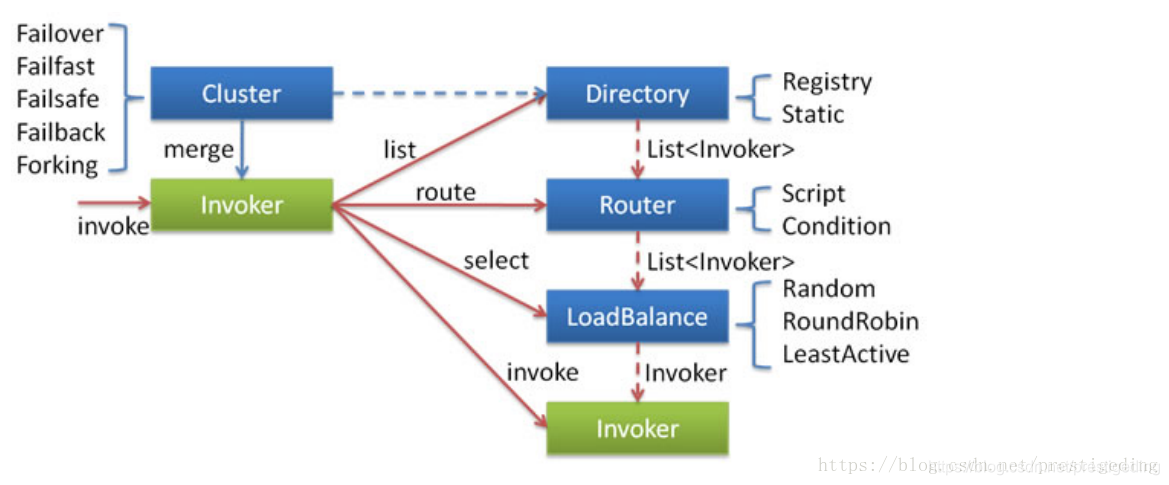
服务调用,重点阐述客户端发起一个RPC服务调用时的所有实现细节,包括服务发现、故障转移、路由转发、负载均衡等方面,是Dubbo实现灰度发布的理论基础。
2.1 服务发现
客户端在向服务端发起请求时,首先需要知道的是当前有哪些可用的服务提供者,通常有两种服务发现机制:
静态化配置 不妨回想一下,在Dubbo等微服务框架出现之前,一个模块调用另外一个模块通常的做法是使用一个配置文件,将服务提供的列表配置配置在配置文件中,客户端从按照配置文件中的列表进行沦陷。
其弊端也非常明显:如果需要调用的服务众多,配置文件会变得臃肿,对扩容缩容的管理、机器宕机等变更不友好,管理非常困难。
动态发现
通常基于注册中心实现服务的注册与动态发现,由于上文已详细介绍,在这里就不累述。
2.2 负载均衡
客户端通过服务发现机制,能动态发现当前存活的服务提供者列表,接下来要考虑的是如果从服务提供者列表中选择一个服务提供者发起调用,这就是所谓的负载均衡,即 LoadBalance。
在Dubbo中默认提供了随机、加权随机、最少活跃连接、一致性Hash等负载均衡算法。
2.3 路由机制
其实Dubbo中不仅提供了负载均衡机制,还提供了智能路由机制,这是实现Dubbo灰度发布的理论基础。
所谓的路由机制,是在服务提供者列表中,再设置一定的规则,进行过滤选择,负载均衡时只从路由过滤规则筛选出来的服务提供者列表中选择,为了更加形象的阐述路由机制的工作原理,给出如下示意图:
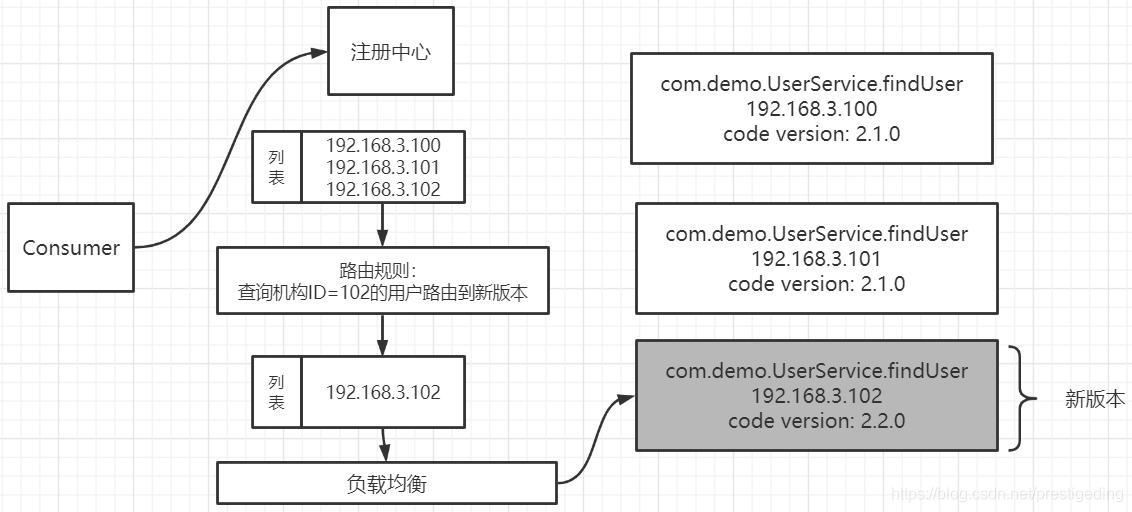 上述设置了一条路由规则,即查询机构ID为102的查询用户请求信息,请发送到新版本,即192168.3.102上,那主要在进行负载均衡之前先执行路由规则,从原始的服务提供者列表者按照路由规则进行过滤,从中挑选出符合要求的提供者列表,然后再进行负载均衡。
上述设置了一条路由规则,即查询机构ID为102的查询用户请求信息,请发送到新版本,即192168.3.102上,那主要在进行负载均衡之前先执行路由规则,从原始的服务提供者列表者按照路由规则进行过滤,从中挑选出符合要求的提供者列表,然后再进行负载均衡。
路由机制的核心理念:在进行负载均衡之前先对服务提供者列表运用路由规则,得出一个参与负载均衡的提供者列表。
2.4 故障转移
远程服务调用通常涉及到网络等因素,客户端向服务提供者发起RPC请求调用时并不一定100%成功,当调用失败后该采用何种策略呢?
Dubbo提供了如下策略:
failover 失败后选择另外一台服务提供者进行重试,重试次数可配置,通常适合实现幂等服务的场景。
failfast
快速失败,失败后立即返回错误。
failsafe 调用失败后打印错误日志,返回成功,通常用于记录审计日志等场景。
failback 调用失败后,返回成功,但会在后台定时无限次重试,重启后不再重试。
forking 并发调用,收到第一个响应结果后返回给客户端。通常适合实时性要求比较高的场景,但浪费服务器资源,通常可以通过forks参数设置并发调用度。
3、线程派发机制
Dubbo的通信线程模型入下图所示: 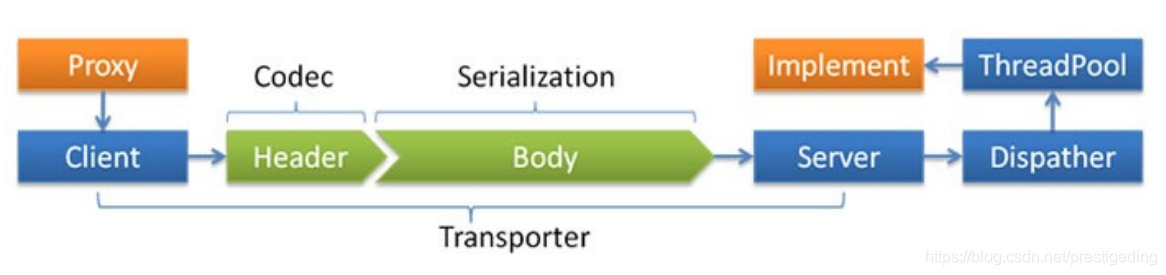
3.1 网络通信协议
网络传输通常需要自定义通信协议,通常采用 Header + Body 的协议设计理念,并且 Header 长度固定,并且包含一个长度字段,用于记录整个协议包的大小。
网络传输为了提高传输效率,可以采取对传输数据进行压缩,通常是对 body 进行序列化与压缩。
Dubbo支持目前支持 java、compactedjava、nativejava、fastjson、fst、hessian2、kryo等序列化协议。
3.2 线程派发机制
在Dubbo中默认会创建200个线程用于处理业务方法,所谓的线程派发机制就是IO线程如何决定何种请求转发到哪类线程中执行。
目前Dubbo中所有的心跳包、网络读写在IO线程中执行,无法通过配置进行修改。
Dubbo提供了如下几种线程派发机制(Dispatcher):
all 所有的请求转发到业务线程池中执行(除IO读写、心跳包)
message 只有请求事件在线程池中执行,其他在IO线程上执行。
connection 请求事件在线程池中执行,连接、断开连接事件排队执行(含一个线程的线程池)。
direct
所有请求直接在IO线程中执行。
> 温馨提示:有关线程模型,网络通信模式,可以参考笔者如下这篇文章。
线程派发机制之所有会有多种策略,主要是考虑线程切换带来的开销是否能容忍,即线程切换带来的开销小于多线程处理带来的提升。
例如在Dubbo中,对心跳包只需直接返回PONG包(OK),逻辑非常简单,如果将其转换到业务线程池,并不能带来性能提升,反而因为需要线程切换,带来性能损耗,故在IO线程中直接发送响应包是一个非常可取的做法。
在网络编程中需要遵循一条最佳实践:IO线程中不能有阻塞操作,阻塞操作需要转发到业务线程池。
更多优质文章请关注『中间件兴趣圈』,回复【专栏】获取12个JAVA主流中间件的源码剖析专栏,回复PDF可以获取海量学习资源,快速进阶打怪,实现职场的突破。














