
在企业业务领域,锦礼是针对福利、营销、激励等员工采购场景的一站式解决方案,包含面向员工、会员等弹性激励SAAS平台。由于其直接面向公司全体员工,其服务的高可用尤其重要,本文将介绍锦礼商城大促前夕,通过混沌工程实战演习,降低应用的MTTR。
MTTR(平均恢复时间)是从产品或系统故障中恢复所需的平均时间。 这包括整个中断时间——从系统或产品出现故障到其恢复完全运行为止。
如何在混沌演练的场景中降低应用的MTTR,必须需要根据监控定位,然后人工进行反馈进行处理吗?是否可以自动化,是否有方案可以降低混沌演练过程中的影响?以此达到快速止血,进一步提高系统的稳定性。
本篇文章将根据一些思考和实践来解答以上问题。
故障无处不在,而且无法避免。
我们将从宿主机重启问题以及底层服务混沌演练的排查与举措说起。
背景
【客户端视角】:出现大量接口(包括提单)超时报错、可用率跳点,部分客户命中,产生客诉。
通过定位发现大促备战前期宿主机重启及底层服务混沌演练原因,较长时间影响我侧系统可用率及性能。尤其是核心接口的部署应用,会大范围的影响到多个接口的可用率,进一步影响采购端客户的体验问题。
特别在TOB领域,本身就存在大客户的口碑效应,如果恰好头部客户碰到该问题,那么极易被放大和激化。
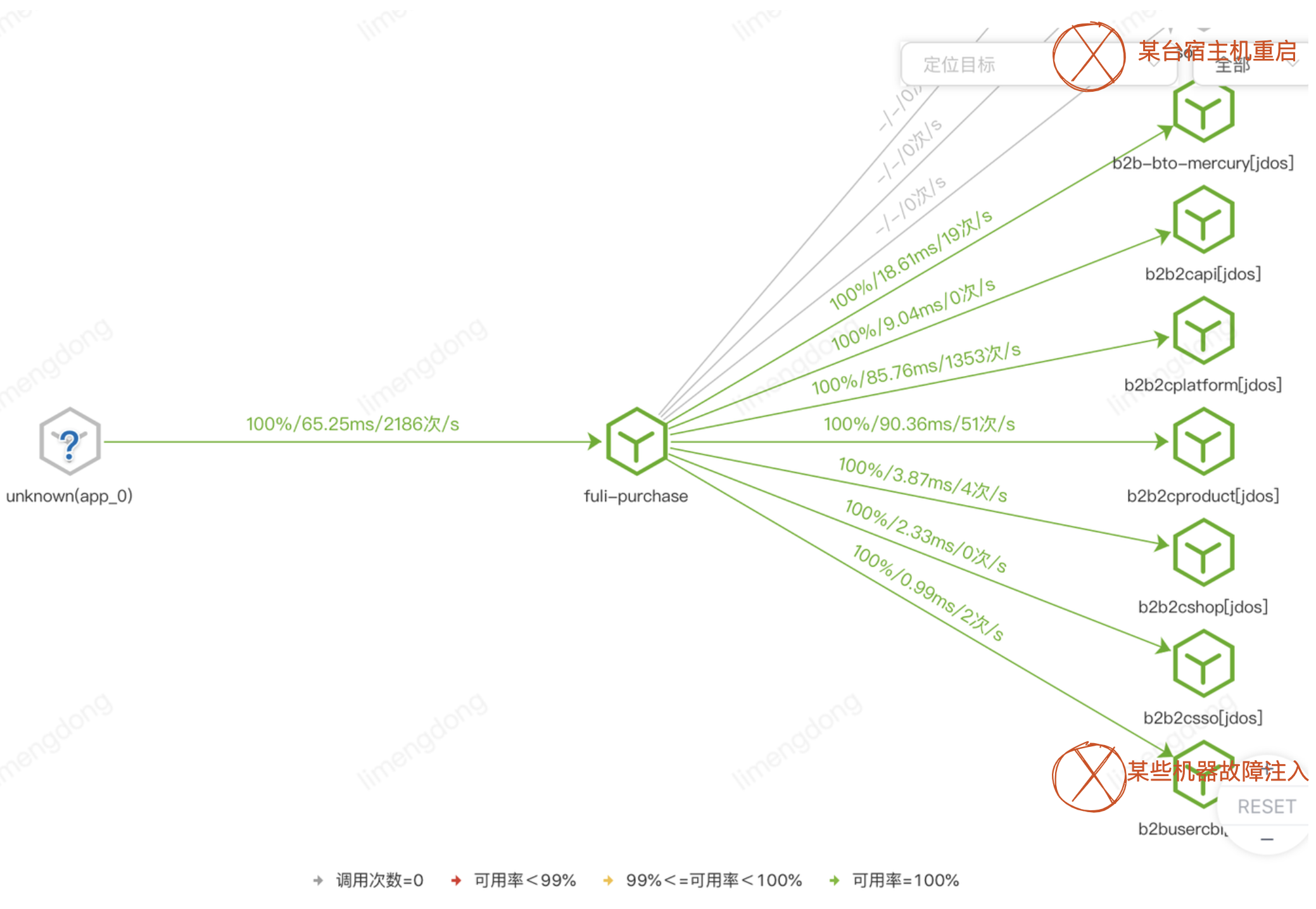 )
)临时举措
一方面协同运维组确认宿主机重启未及时通知的情况,另一方面与底层服务提供者同步演练影响,建议其遵守演练原则最小化爆炸半径,控制影响范围,保证演练是可控的。
除了以上协同外部的情况外,我们内部也产生了思考,首先情况故障本身就是不可控的,无论宿主机还是混沌演练,真实场景也是有概率发生的(并且已发生)。那么我们只能通过监控定位,然后手动摘除机器或者通知服务提供者处理吗?是否可以自动化,是否有方案可以降低影响?以此达到快速止血,进一步提高系统的稳定性。
长期方案——JSF中间件能力实践
既然无法避免故障,那么就拥抱故障,通过一些技术手段来构建获取应用故障的能力,从而保证应用的高可用。
由于内部的调用90+%为(JSF)RPC调用,所以我们还是把目光放到了JSF中间件的容错能力上,以下主要介绍通过JSF中间件的超时与重试、自适应负载均衡、服务熔断来进行故障转移的理论与实践。
实践是检验真理的唯一标准。
关于超时和重试
实际开发过程中,相信大家也见过太多由于超时未设置、设置有误导致的故障。当超时未设置或者设置不合理,会导致请求响应变慢,慢请求的不断累计叠加,就会引起连锁反应,甚至产生应用雪崩。
不仅我们自身的服务,还有外部的依赖服务,不仅HTTP服务,还是中间件服务,都应该设置合理的超时重试策略,并且重视起来。
首先读写服务的超时重试策略也是大不相同的,读服务天生适合重试(如设置合理超时时间后重试两次),但是写服务大多是不能重试的,不过如果均是幂等设计,也是可以的。
另外设置调用方的超时时间之前,需要先了解清楚依赖服务的TP99响应时间是多少(如果依赖服务性能波动大,也可以看TP95),调用方的超时时间可以在此基础上加50%Buff。当然服务的响应时间并不是恒定的,在某些长尾条件下可能需要更多的计算时间,所以为了有足够的时间等待这种长尾请求响应,我们需要把超时设置足够合理。
最后重试次数不宜太多(高并发时可能引发一系列问题(一般2次,最多3次),虽然重试次数越大,服务可用性越高,但是高并发情况下会导致多倍的请求流量,类似模拟DDOS攻击,严重情况下甚至于加速故障的连锁发生。因此超时重试最好是和熔断、快速失败等机制配合使用,效果更佳,这个后面会提到。
除了引入手段,重要的是验证手段的有效性。
模拟场景(后续另两个手段也是用该场景)
方案:采用故障注入(50%机器网络延迟3000-5000ms)的方式模拟类似场景,并验证。
机器部署如下:
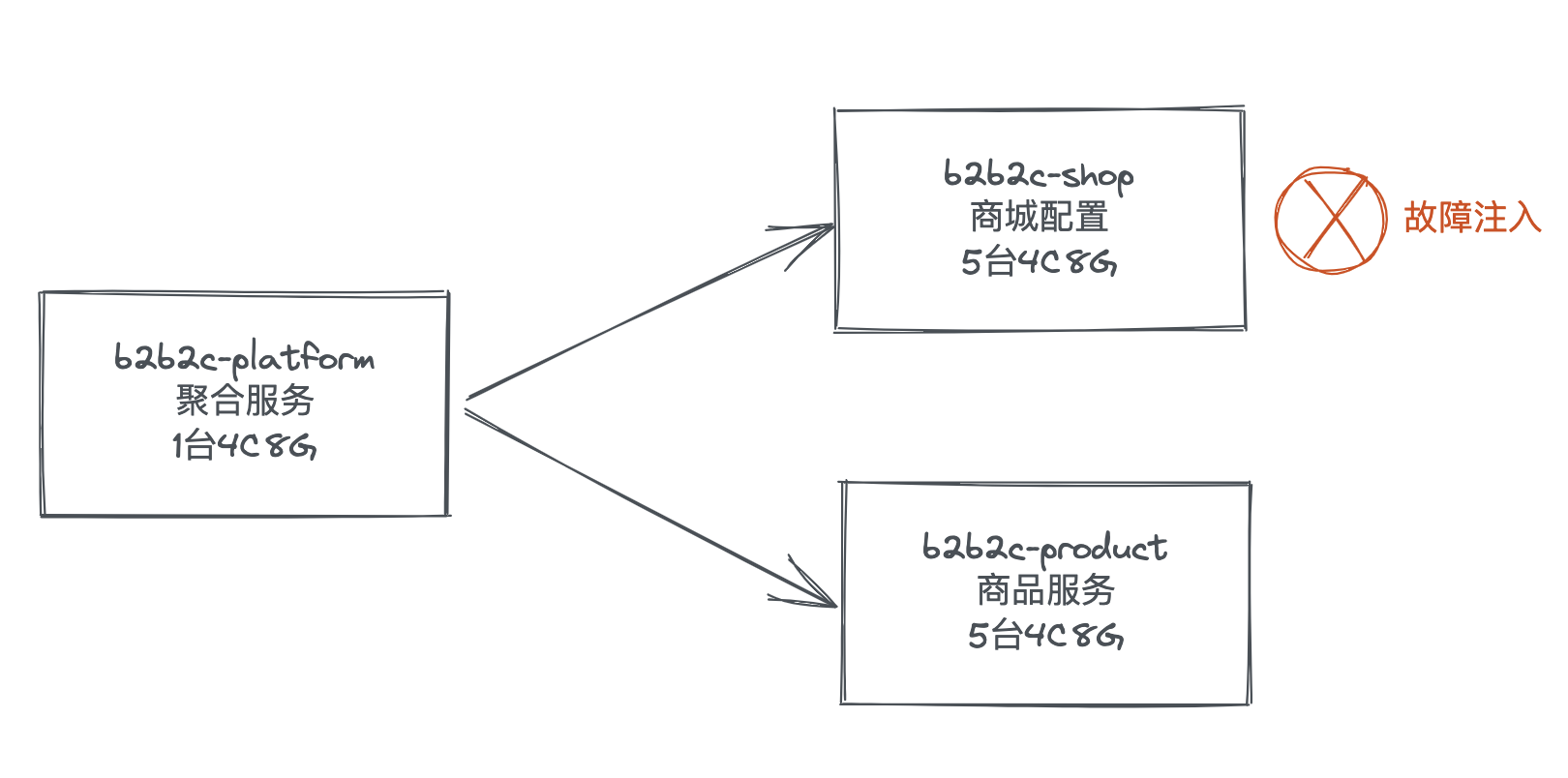 )
)压测接口(QPS-300)及故障接口监控Key值:
1、压测接口:jdos_b2b2cplatform.B2b2cProductProviderImpl.queryProductBpMap
2、服务消费:jdos_b2b2cplatform.ActivityConfigServiceRPCImpl.queryActivityConfig
3、服务提供:jdos_b2b2cshop.com.jd.ka.b2b2c.shop.service.impl.sdk.ActivityConfigServiceImpl.queryActivityConfig
【注意】网络场景不支持如下情形:
1、应用容器所在机房:xxx
2、物理机的内核版本:xxx
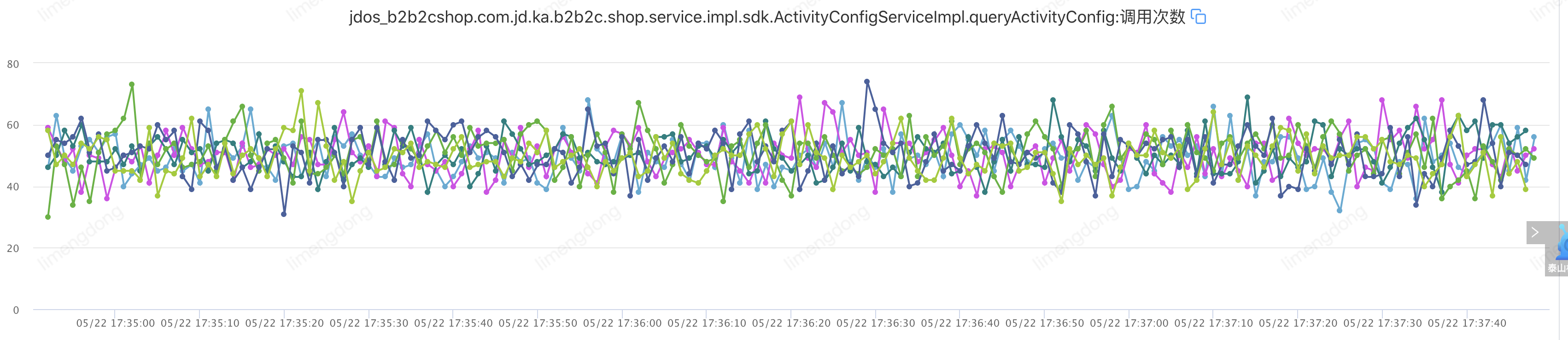
正常情况(未注入故障)
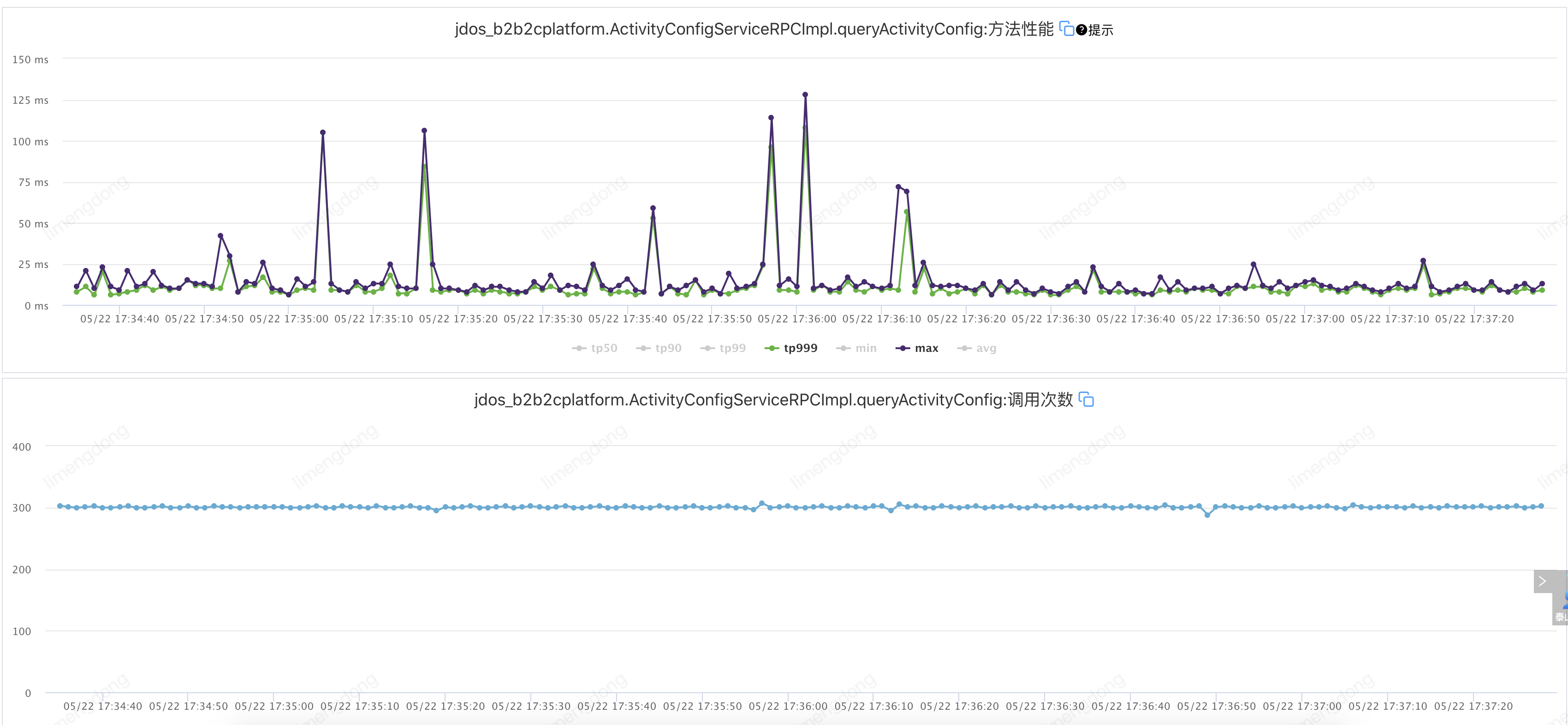 )
)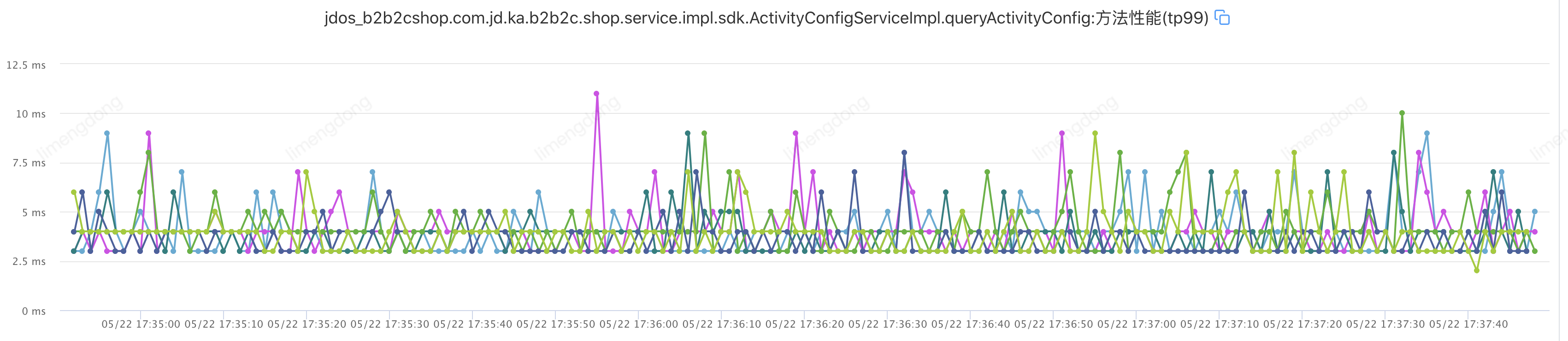 )
) )
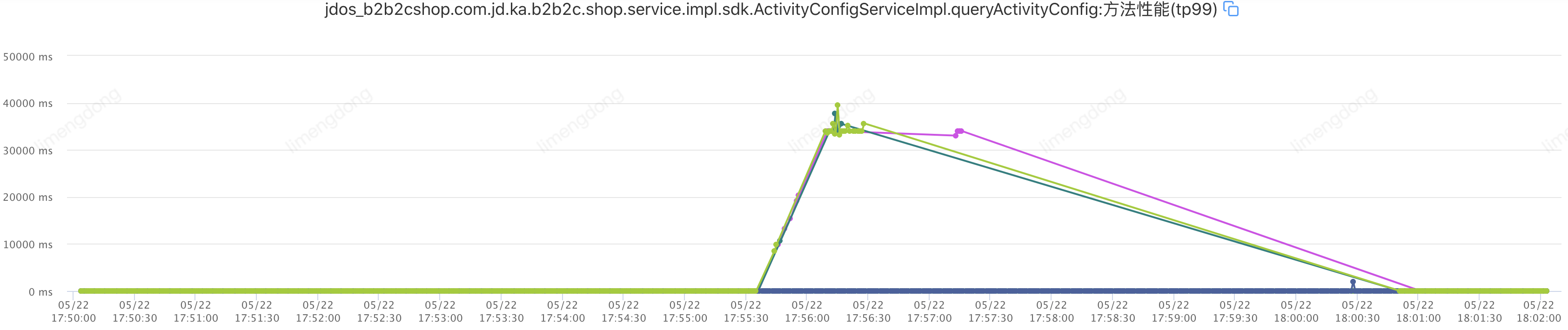
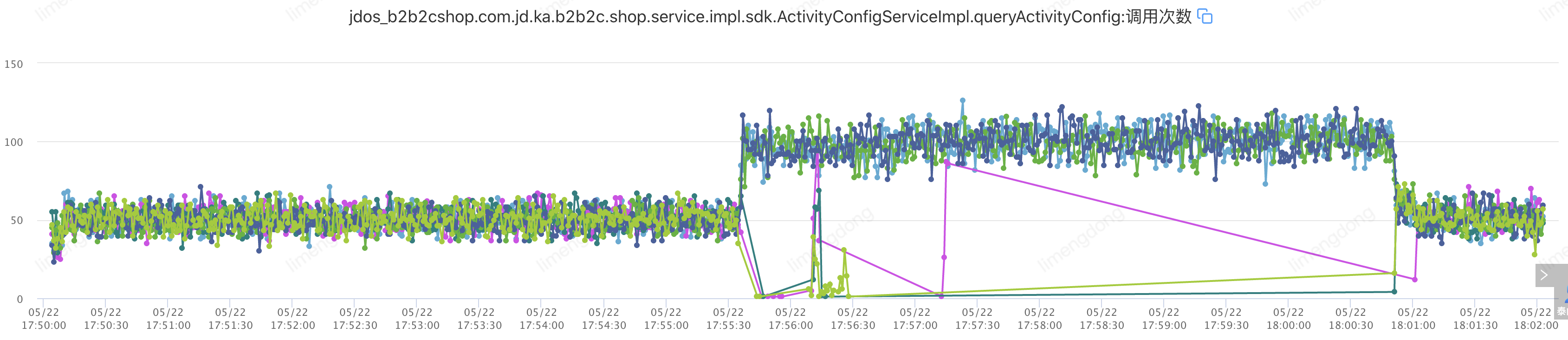
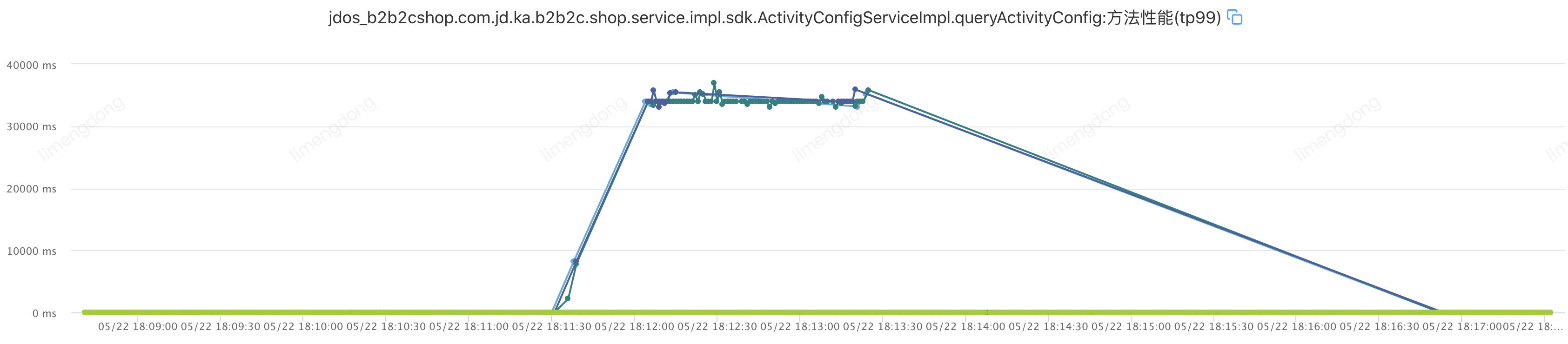
)注入故障——超时设置不合理情况下(超时2000ms,重试2)
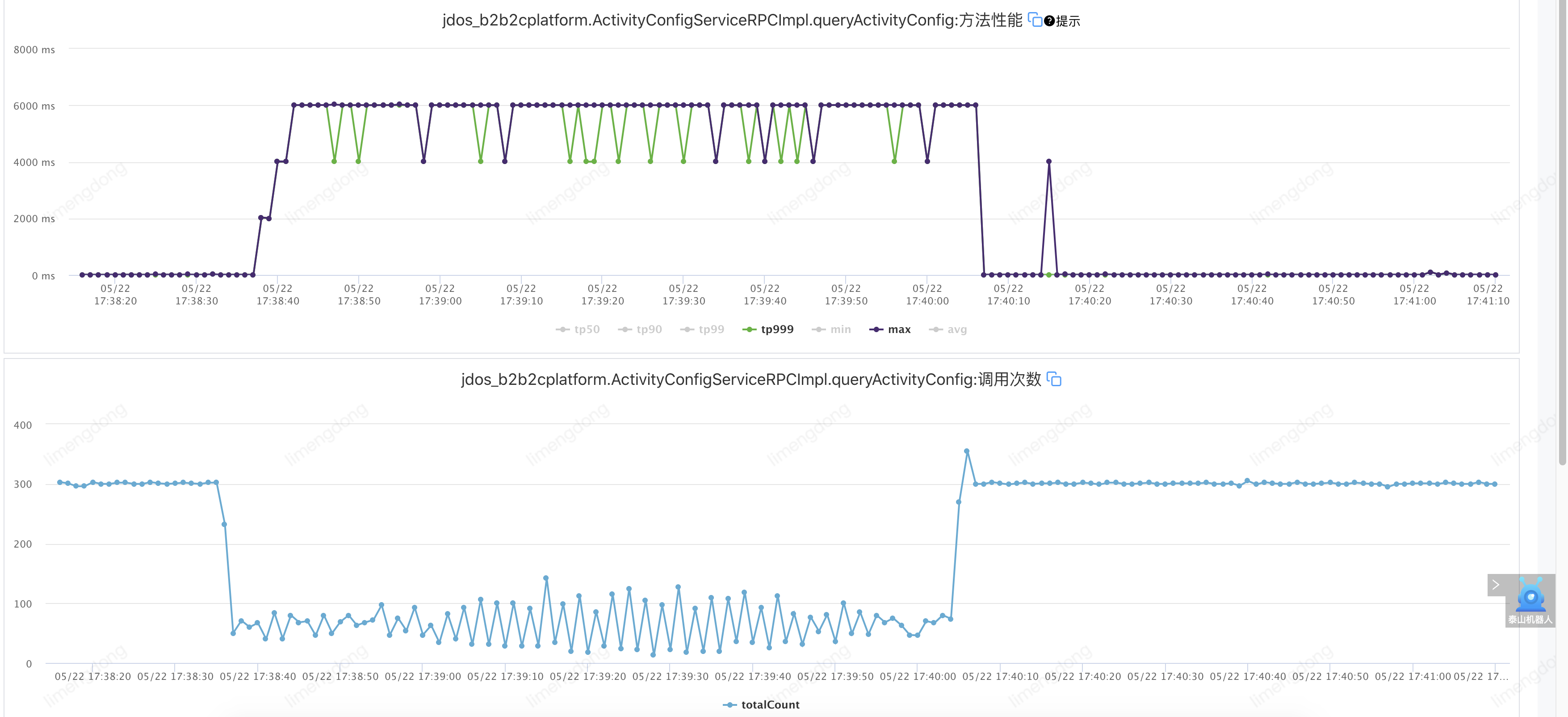 )
) )
)注入故障——超时设置合理情况下(超时10ms,重试2)
该接口TP99在6ms,设置超时10ms,重试2。即:jsf:methodname="queryActivityConfig"timeout="10"retries="2"/
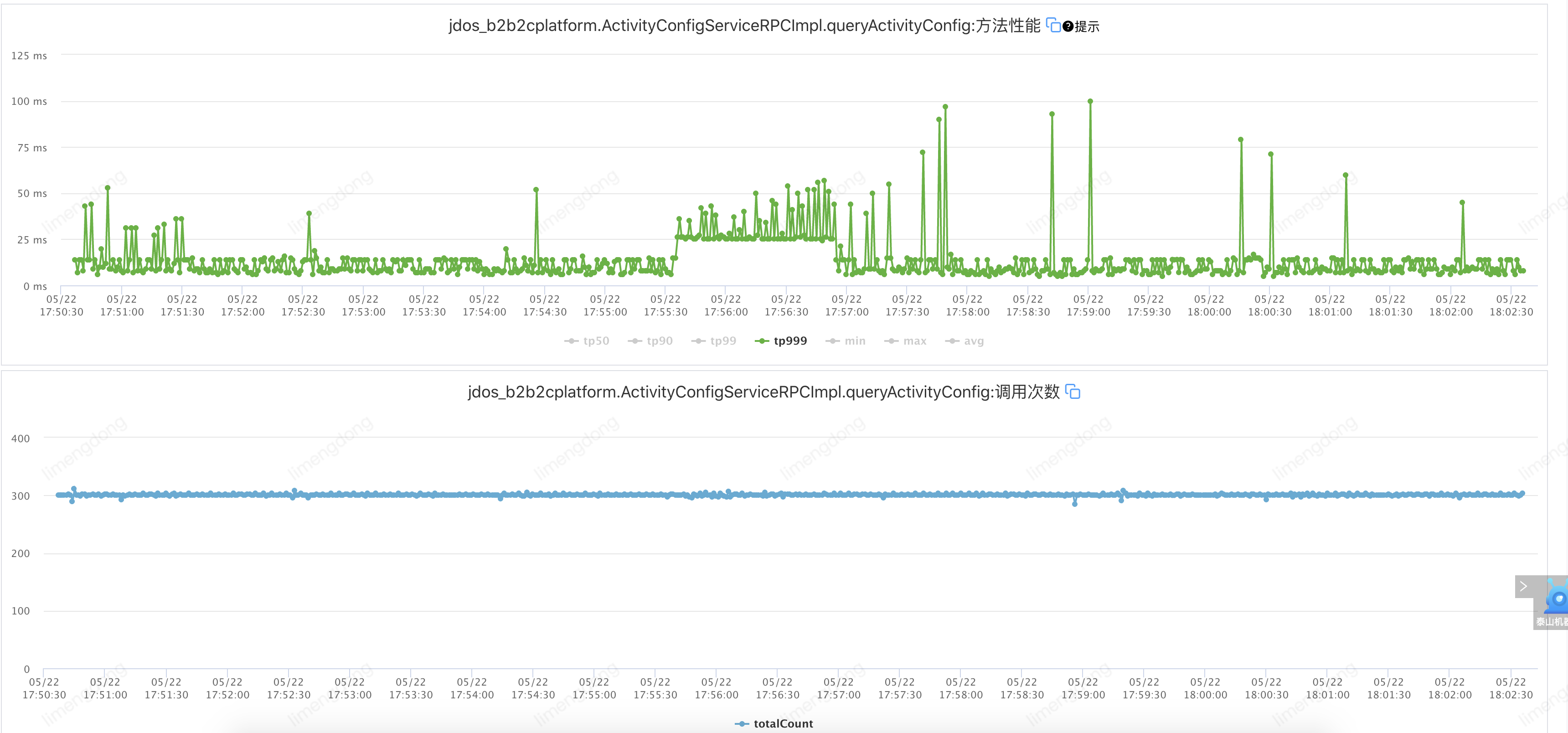 )
) )
) )
)超时重试小结
通过合理的超时重试,整体请求平稳,重试后的故障转移,大幅提升接口可用率。
超时重试补充
在接口维度拆分不合理的情况下,我们可以更细粒度的使用方法维度的超时重试配置,不过这里有一个注意项JSF当前注解方式不支持方法维度的超时重试设置,仅支持接口维度,如已使用注解类,可进行迁移XML方式进行配置使用,
关于自适应负载均衡
对于shortestresponse自适应负载均衡设计目的是解决在 provider 节点能力不均的场景下,让处理能力较弱的provider少接受些流量,不会因个别性能较差的 provider 影响到 consumer 整体调用的请求耗时和可用率。
能者多劳拙者闲,智者多忧愚者无所虑。
但是该策略下也是存在一些问题的:
- 流量的过度集中高性能实例,服务提供者的单机限流或成为瓶颈。
- response的时间长短有时也并不能代表机器的吞吐能力。
- 大多数的场景下,不同provider的response时长在没有非常明显的区别时,shortestresponse同random(随机)。
现有的shortestresponse的实现机制,类似P2C(Power of Two Choice)算法,不过计算方式不是采用当前正在处理的连接数,而是默认随机选择两个服务提供者参与最快响应比较计算,即:统计请求每个provider的请求耗时、访问量、异常量、请求并发数,比较平均响应时间 * 当前请求数,用于最快响应负载计算。选取优胜者来避免羊群效应。以此自适应的衡量 provider 端机器的吞吐能力,然后将流量尽可能分配到吞吐能力高的机器上,提高系统整体服务的性能。
<jsf:consumer id="activityConfigService"
interface="com.jd.ka.b2b2c.shop.sdk.service.ActivityConfigService"
alias="${jsf.activityConfigService.alias}" timeout = "3000" filter="jsfLogFilter,jsfSwitchFilter"
loadbalance="shortestresponse">
<jsf:method name="queryActivityConfig" timeout="10" retries="2"/>
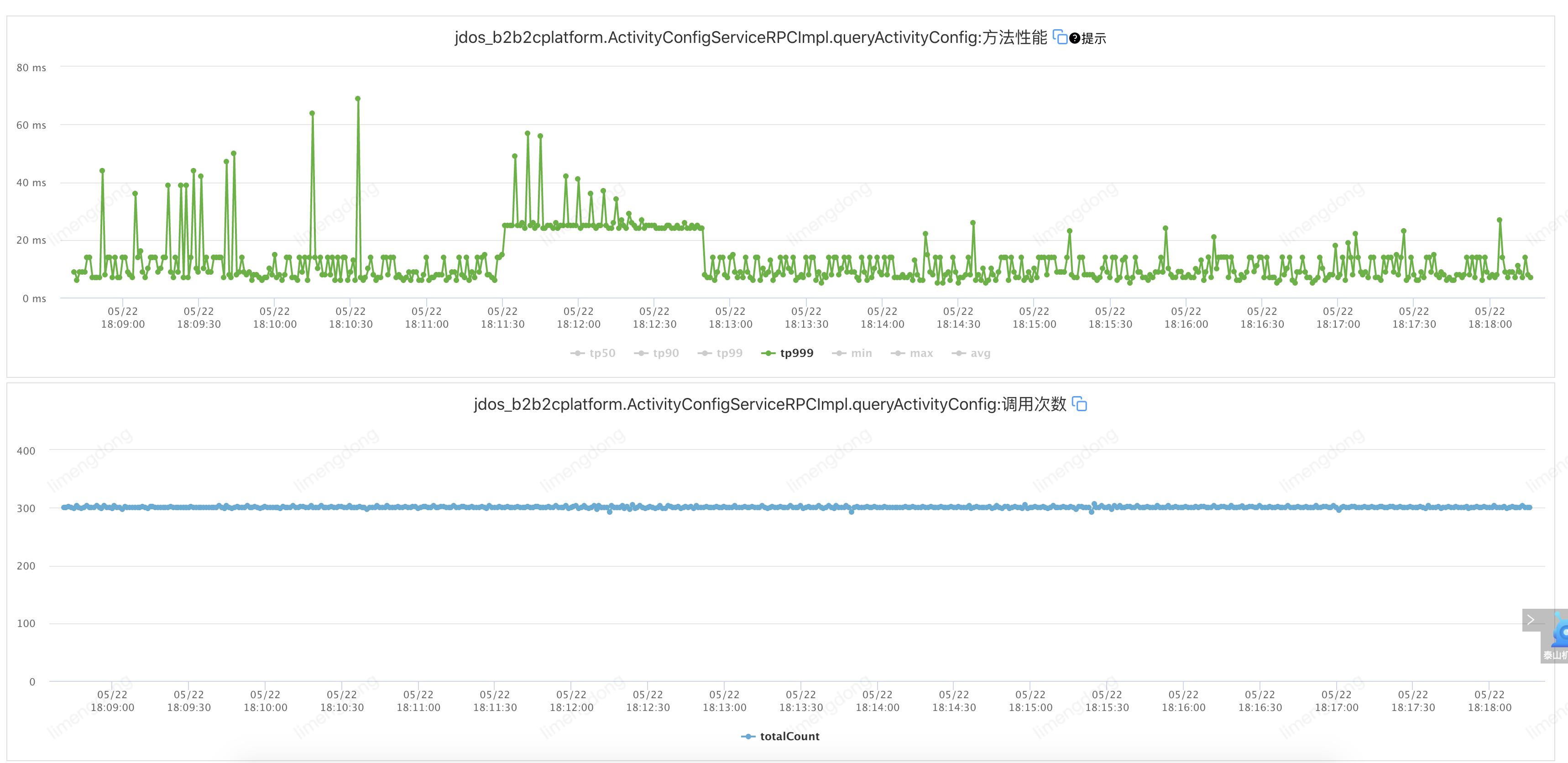
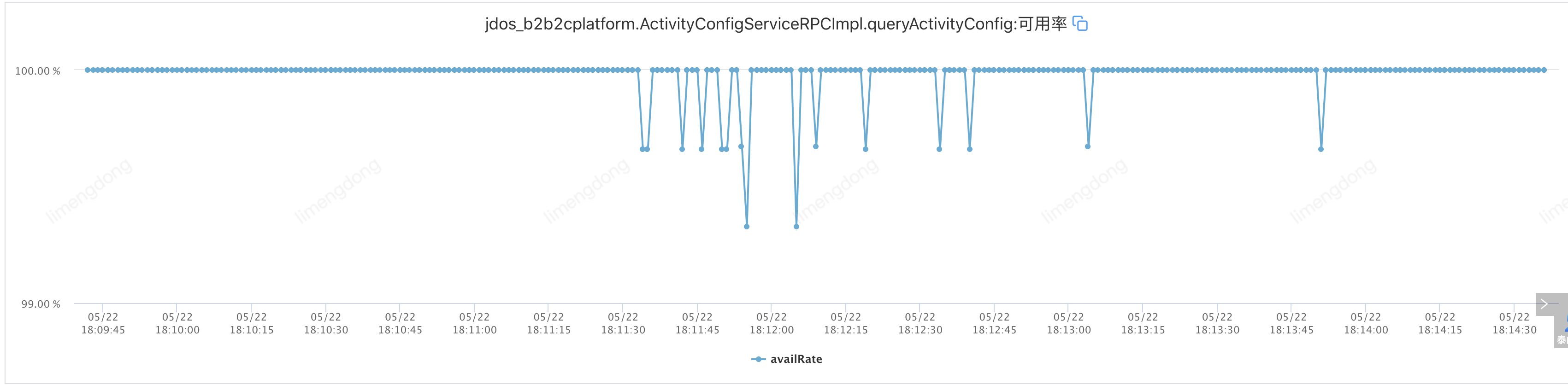
</jsf:consumer>注入故障(设置自适应负载均衡)
 )
) )
) )
)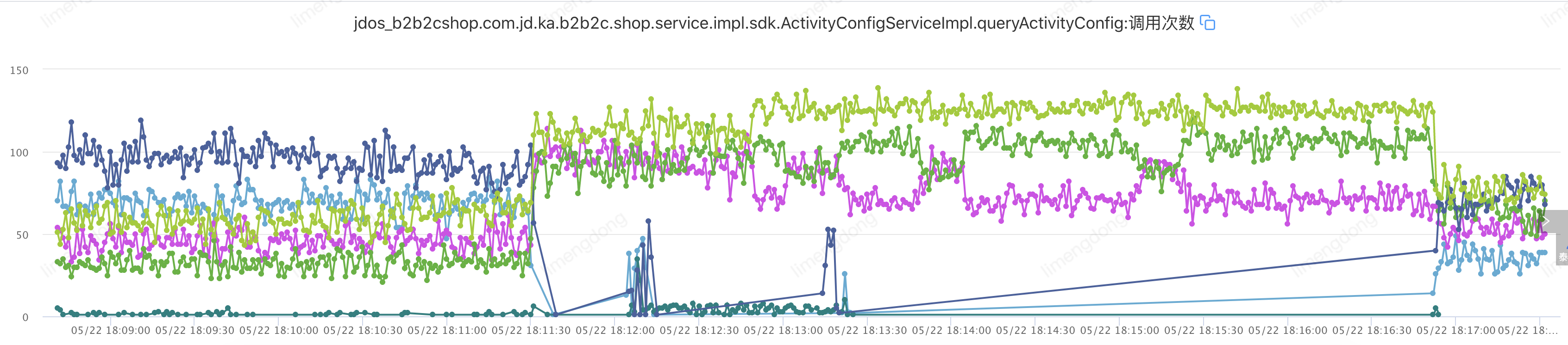 )
)自适应负载均衡小结
通过引入自适应负载均衡,从接口最初调用就开始了”能者多劳“模式,选举出的机器承载着更高的流量,故障注入后,接口可用率短时间窗口消失,变成可用率跳点,进一步保障了服务的高可用及性能。
关于服务熔断
当电路发生短路或严重过载时,熔断器中的熔断体将自动熔断,对电路进行保护。避免对设备产生重大影响,甚至火灾。
服务熔断是面向不稳定服务场景的一种链路保护机制。
其背后的基本思想非常简单,将受保护的函数调用包装在熔断对象中,该对象会监视故障。当调用链路的某个服务不可用或者响应时间太长导致故障达到设定阈值时,会进行服务熔断,熔断窗口内不再有该节点服务的调用,以此来最大限度避免下游服务不稳定对上游服务带来的影响。
<!-- 服务熔断策略配置 -->
<jsf:reduceCircuitBreakerStrategy id="demoReduceCircuitBreakerStrategy"
enable="true" <!-- 熔断策略是否开启 -->
rollingStatsTime="1000" <!-- 熔断器指标采样滚动窗口时长,单位 ms,默认 5000ms -->
triggerOpenMinRequestCount="10" <!-- 单位时间内触发熔断的最小访问量,默认 20 -->
triggerOpenErrorCount="0" <!-- 单位时间内的请求异常数达到阀值,默认 0,小于等于0 代表不通过异常数判断是否开启熔断 -->
triggerOpenErrorPercentage="50" <!-- 单位时间内的请求异常比例达到阀值,默认 50,即 默认 50% 错误率 -->
<!-- triggerOpenSlowRT="0" 判定请求为慢调用的请求耗时,单位 ms,请求耗时超过 triggerOpenSlowRT 则认为是慢调用 (默认为 0,即默认不判定)-->
<!-- triggerOpenSlowRequestPercentage="0" 采样滚动周期内触发熔断的慢调用率(默认为 0,即默认不触发慢调用熔断 -->
openedDuration="10000" <!-- 熔断开启状态持续时间,单位 ms,默认 5000ms -->
halfOpenPassRequestPercentage="30" <!-- 半闭合状态,单位时间内放行流量百分比,默认 40-->
halfOpenedDuration="3000" <!-- 半闭合状态持续时间设置,需要大于等于 rollingStatsTime ,默认为 rollingStatsTime -->
<!-- failBackType="FAIL_BACK_EXCEPTION" failBack策略, 取值:FAIL_BACK_EXCEPTION抛出异常、FAIL_BACK_NULL返回null、FAIL_BACK_CUSTOM配置自定义策略,配合 failBackRef 属性 -->
<!-- failBackRef="ref" 如果 failBackStrategy 配置为 FAIL_BACK_CUSTOM 则必填,用户自定义的failback策略com.jd.jsf.gd.circuitbreaker.failback.FailBack<Invocation> 接口实现类 -->
/>
<jsf:consumerid="activityConfigService"interface="com.jd.ka.b2b2c.shop.sdk.service.ActivityConfigService"
alias="${consumer.alias.com.jd.ka.b2b2c.shop.sdk.service.ActivityConfigService}" timeout="2000"check="false"
serialization="hessian"loadbalance="shortestresponse"
connCircuitBreakerStrategy="demoCircuitBreakerStrategy">
<jsf:methodname="queryActivityConfig"timeout="10"retries="2"/>
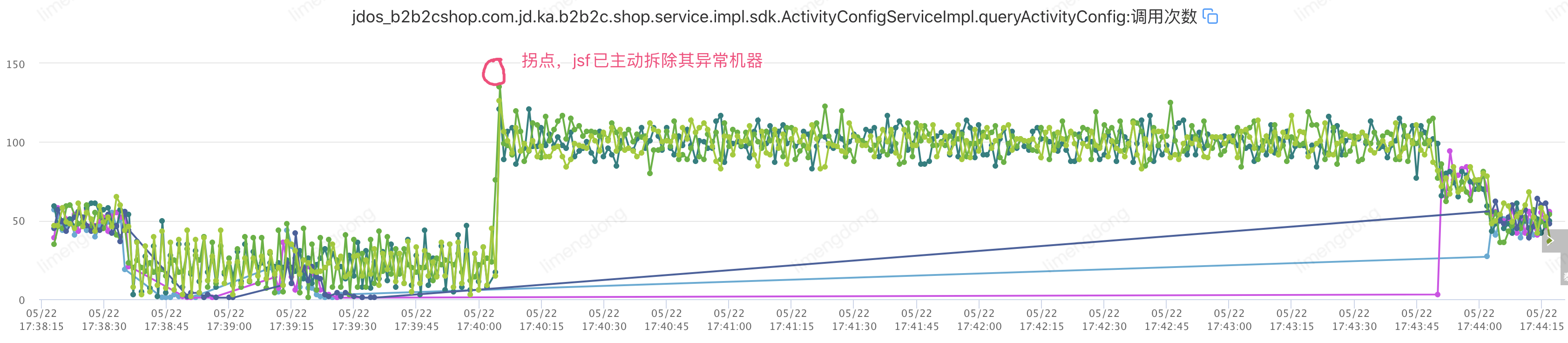
</jsf:consumer>这里来了一个小插曲,由于JSF本身的心跳机制,检测故障后,自动(30s检测一次,三次均异常则摘除)摘除了对应的机器,我们自身设置的熔断机制并不明显,因此重新设置故障(网络延迟800-1500ms)进行重新演练。
注入故障(服务熔断)
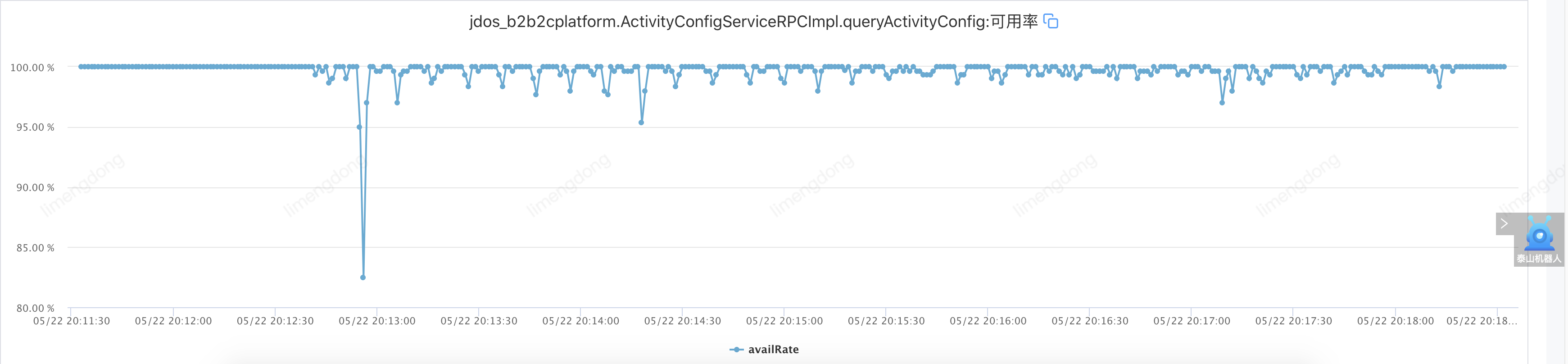 )
)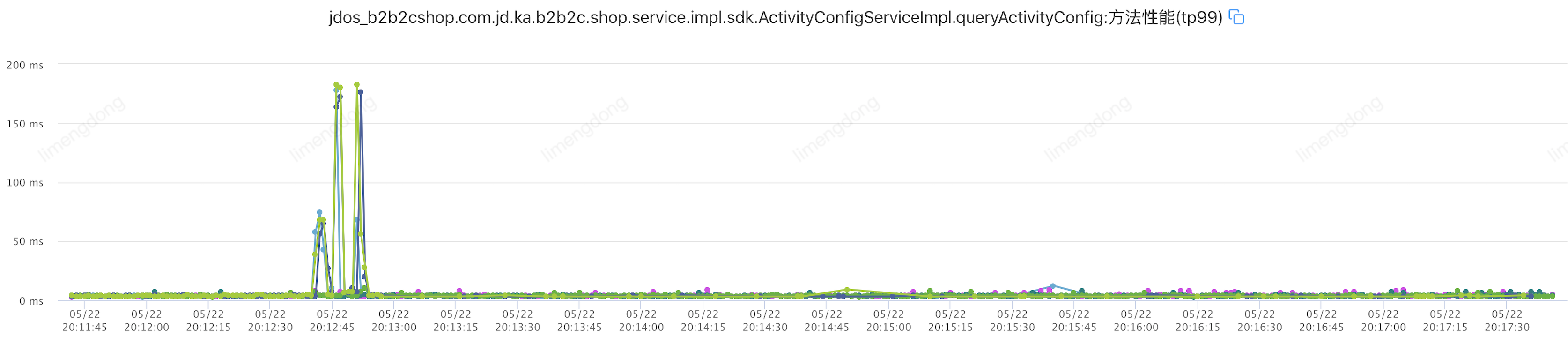 )
)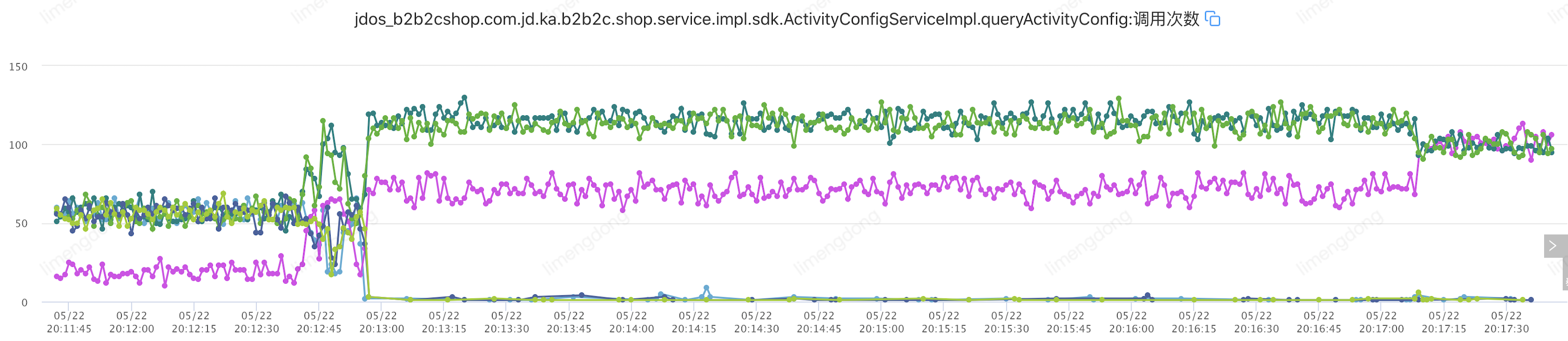 )
)服务熔断小结
从可用率上看,确实在窗口内会关闭对异常机器节点的访问,不过由于并没有实现failback策略以及熔断开启窗口时间较短,可用率还是会在窗口打开后,直接返回了调用失败信息,因此影响了可用率。所以相比于熔断后失败,最好的方式是配合服务降级能力,通过调用预先设置好的服务降级逻辑,以降级逻辑的结果作为最终调用结果,以更优雅的返回给服务调用方。
服务熔断补充
- 集团已搭建了统一的熔断组件,并且在泰山上建立了对应的平台能力。如果团队需要引入熔断能力,可以直接接入使用,避免重复建设。
一种机制可能会击败另一种机制。
其实为了增强系统的弹性和鲁棒性,以应对各种故障和不可预测的情况,在分布式系统中,通常会设计成能够部分故障(partially fail),即使不能满足全量客户,但是仍然可以向某些客户提供服务。但是熔断旨在将部分故障转化为完全故障,以此防止故障进一步扩散。因此服务熔断和分布式系统的设计原则中存在一种相互制约的关系,所以,在使用前,要进行仔细的分析和思考,以及后续的调优。
结论
能力只是手段,稳定性才是目的。
无论采用什么手段,进行稳定性建设,我们需要时刻思考的是如何在业务需求和稳定性建设中寻找平衡,以建设支持业务长期增长的高可用架构。
本次就写到这,如有问题,欢迎交流。希望文章中的一些经验,给大家带来一些收获,或者说,大家不妨思考一下你们会采用何种技术方案和手段来解决类似问题。欢迎留言交流,也希望能和更多志同道合的伙伴沟通交流。
最后老样子,欢迎大家一键三连点赞收藏+关注。
参考文档
The power of two random choices : https://brooker.co.za/blog/2012/01/17/two-random.html
负载均衡:https://cn.dubbo.apache.org/zh-cn/overview/core-features/load-balance/#shortestresponse
作者:京东零售 李孟冬
来源:京东云开发者社区







